







原文链接:https://arxiv.org/abs/2409.19405
摘要:大尺度3D场景重建对虚拟现实和仿真等应用来说有重要意义。现有的神经渲染方法(NeRF、3DGS)实现了对大场景的真实重建,但其逐场景优化的成本高、速度慢,且过拟合会带来大视角变换下的伪影。可泛化方法或大型重建模型速度很快,但主要对小场景或物体重建,且渲染质量较低。本文引入可泛化重建方法G3R,可对大场景预测高质量3D场景表达。本文提出学习重建网络,使用可微渲染的梯度反馈信号来迭代更新3D场景表达,将逐场景优化的真实性和数据驱动先验的前馈预测快速性结合起来。在城市驾驶和无人机数据集上的实验表明,G3R可跨场景泛化,并能以10x的速度实现相当于或超越3DGS的性能,且对大视角变化的鲁棒性更高。
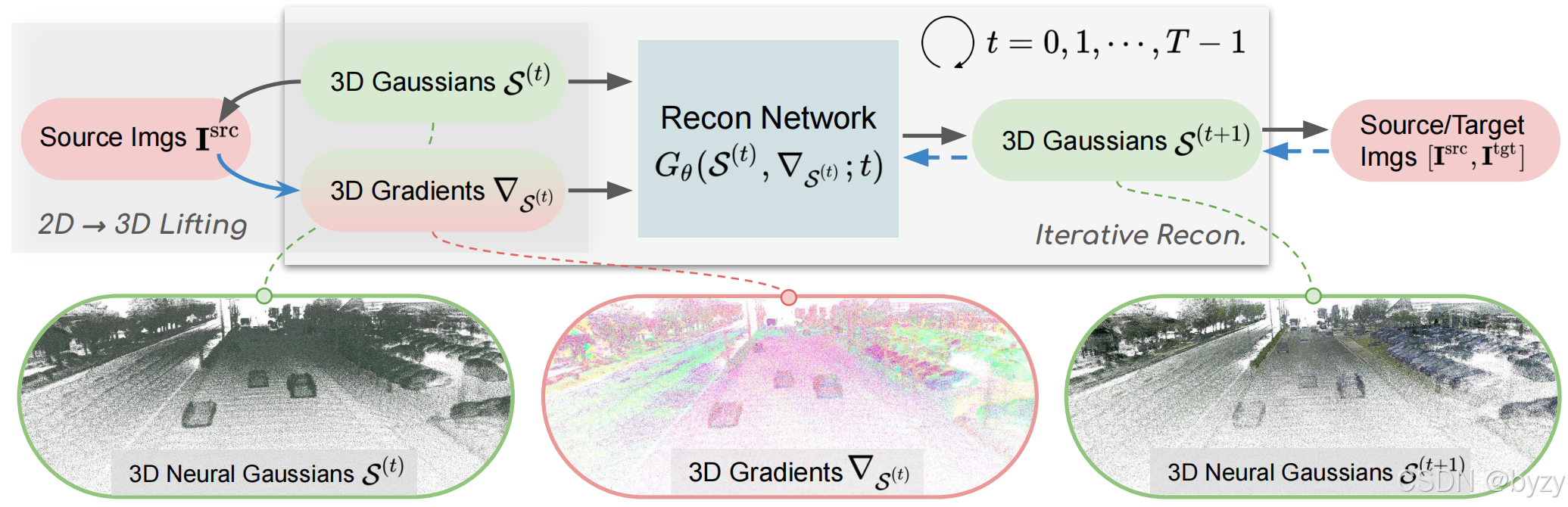
0. 梯度指导的可推广重建(G3R)概述
任务:给定大型动态场景中传感器移动平台捕捉的源图像集合 I s r c = { I i } 1 ≤ i ≤ N I^{src}=\{I_i\}_{1\leq i\leq N} Isrc={Ii}1≤i≤N和近似的几何脚手架 M \mathcal M M(如激光雷达点或多视图立体中的点),目标是有效重建真实的、可编辑的3D表达 S \mathcal S S,以进行实时摄像头仿真。
梯度指导的可推广重建(G3R):G3R是第一个可在2分钟内建立大型真实场景的可修改数字克隆的方法,且可以>90FPS的速度生成真实度高的新视图。方法如图所示。G3R使用单一神经网络,迭代地更新由脚手架
M
\mathcal M
M初始化的3D神经高斯表达。
1. G3R的场景表达
本文对3DGS进行了两种增强:首先为高斯表达增加一个隐式特征向量(称为3D神经高斯),从而为泛化重建和学习优化提供额外能力。其次,将场景分解为近处静态场景、动态参与者和远处区域,以建模无界动态场景。
3D神经高斯:本文的场景表达 S \mathcal S S为3D神经高斯的集合,即 S = { h i } 1 ≤ i ≤ M \mathcal S=\{h_i\}_{1\leq i\leq M} S={hi}1≤i≤M,其中每个点由特征向量 h i ∈ R C h_i\in\mathbb R^C hi∈RC表达。为了渲染,本文使用MLP将3D神经高斯转换为显式的3D高斯 G = { g i } 1 ≤ i ≤ M \mathcal G=\{g_i\}_{1\leq i\leq M} G={gi}1≤i≤M: g i = f m l p ( h i ) g_i=f_{mlp}(h_i) gi=fmlp(hi)。前14个通道被指定为3D高斯属性(位置、尺度、朝向、颜色和不透明度),并在 f m l p f_{mlp} fmlp中添加跳跃连接。
刚性动态物体和无界场景的表达:3D神经高斯被分解为静态背景 S B \mathcal S^B SB,动态参与者 S A \mathcal S^A SA和远处区域 S Y \mathcal S^Y SY。假设动态参与者进行刚体运动 T ( S A , ξ A ) \mathcal T(\mathcal S^A,\xi^A) T(SA,ξA),其中 T \mathcal T T为刚体变换, ξ A \xi^A ξA为参与者外参。动态点 S A \mathcal S^A SA在不同帧间移动,使用3D边界框指示位置和大小。使用脚手架 M \mathcal M M初始化静态背景和动态参与者的3D神经高斯,并固定一定数量的远处点以建模远处区域。
渲染:给定
S
\mathcal S
S和相机姿态
Π
=
{
K
i
,
ξ
i
}
\Pi=\{K_i,\xi_i\}
Π={Ki,ξi}(其中
K
i
K_i
Ki和
ξ
i
\xi_i
ξi为相机
i
i
i的内外参),将
S
\mathcal S
S转化为3D高斯
G
\mathcal G
G后,使用可微tile栅格化器渲染图像
I
^
\hat I
I^:
f
r
e
n
d
e
r
(
S
;
Π
)
:
=
f
r
a
s
t
(
G
;
Π
)
=
f
r
a
s
t
(
f
m
l
p
(
S
)
;
Π
)
:
=
f
r
a
s
t
(
f
m
l
p
(
S
B
,
S
Y
,
T
(
S
A
,
ξ
A
)
)
;
Π
)
\begin{aligned}f_{render}(\mathcal S;\Pi)&:=f_{rast}(\mathcal G;\Pi)=f_{rast}(f_{mlp}(\mathcal S);\Pi)\\ &:=f_{rast}(f_{mlp}(\mathcal S^B,\mathcal S^Y,\mathcal T(\mathcal S^A,\xi^A));\Pi)\end{aligned}
frender(S;Π):=frast(G;Π)=frast(fmlp(S);Π):=frast(fmlp(SB,SY,T(SA,ξA));Π)
2. 将2D图像提升为3D作为梯度
过去的泛化方法从源视图提取图像特征,并使用相机和几何先验(如对极几何或多视图立体)聚合之,从而将2D图像提升到3D。但每个图像分别由一个神经网络处理,受到存储限制,不能使用大量的输入图像来重建大型场景。
本文使用“渲染和反向传播”的方法将2D图像提升到3D,以获取3D表达的梯度。
优点:3D梯度作为统一表达,可有效聚合尽可能多的图像;3D梯度将渲染纳入考量,可自然处理遮挡;允许调整3D表达;3D梯度可通过现代可微栅格化引擎快速计算。
给定3D表达
S
\mathcal S
S,首先渲染源视图图像
I
^
s
r
c
=
f
r
e
n
d
e
r
(
S
;
Π
s
r
c
)
\hat I_{src}=f_{render}(\mathcal S;\Pi^{src})
I^src=frender(S;Πsrc),并与输入比较,计算重建损失
L
L
L,并反向传播到3D表达
S
\mathcal S
S以获得累积梯度
∇
S
:
=
∇
S
L
(
S
,
I
s
r
c
;
Π
s
r
c
)
\nabla_{\mathcal S}:=\nabla_{\mathcal S}L(\mathcal S,I^{src};\Pi^{src})
∇S:=∇SL(S,Isrc;Πsrc):
L
(
S
,
I
s
r
c
;
Π
s
r
c
)
=
∑
i
∥
I
i
s
r
c
−
I
^
i
s
r
c
∥
2
=
∑
i
∥
I
i
s
r
c
−
f
r
e
n
d
e
r
(
S
;
Π
i
s
r
c
)
∥
2
∇
S
L
(
S
,
I
s
r
c
;
Π
s
r
c
)
=
∂
L
(
S
,
I
s
r
c
;
Π
s
r
c
)
∂
S
=
∑
i
∂
∥
I
i
s
r
c
−
f
r
e
n
d
e
r
(
S
;
Π
i
s
r
c
)
∥
2
∂
S
L(\mathcal S,I^{src};\Pi^{src})=\sum_i\|I_i^{src}-\hat I_i^{src}\|_2=\sum_i\|I_i^{src}-f_{render}(\mathcal S;\Pi_i^{src})\|_2\\ \nabla_{\mathcal S}L(\mathcal S,I^{src};\Pi^{src})=\frac{\partial L(\mathcal S,I^{src};\Pi^{src})}{\partial\mathcal S}=\sum_i\frac{\partial \|I_i^{src}-f_{render}(\mathcal S;\Pi_i^{src})\|_2}{\partial\mathcal S}
L(S,Isrc;Πsrc)=i∑∥Iisrc−I^isrc∥2=i∑∥Iisrc−frender(S;Πisrc)∥2∇SL(S,Isrc;Πsrc)=∂S∂L(S,Isrc;Πsrc)=i∑∂S∂∥Iisrc−frender(S;Πisrc)∥2
其中可微函数 f r e n d e r f_{render} frender建立了2D到3D的联系;梯度 ∇ S \nabla_{\mathcal S} ∇S以 S \mathcal S S为代理,在3D中编码了2D图像。
3. 使用神经网络迭代重建
本节介绍如何给定源图像
I
s
r
c
I^{src}
Isrc,迭代更新场景表达
S
\mathcal S
S。在每一步
t
t
t,根据当前的3D表达
S
(
t
)
\mathcal S^{(t)}
S(t),通过可微渲染计算梯度
∇
S
(
t
)
\nabla_{\mathcal S^{(t)}}
∇S(t),从而将2D源图像反投影到3D。随后,将
∇
S
(
t
)
\nabla_{\mathcal S^{(t)}}
∇S(t)送入网络
G
θ
G_\theta
Gθ,预测更新的3D表达
S
(
t
+
1
)
\mathcal S^{(t+1)}
S(t+1):
S
(
t
+
1
)
=
S
(
t
)
+
γ
(
t
)
⋅
G
θ
(
S
(
t
)
,
∇
S
(
t
)
L
(
S
(
t
)
,
I
s
r
c
;
Π
s
r
c
)
;
t
)
,
t
=
0
,
1
,
⋯
,
T
−
1
\mathcal S^{(t+1)}=\mathcal S^{(t)}+\gamma(t)\cdot G_\theta(\mathcal S^{(t)},\nabla_{\mathcal S^{(t)}}L(\mathcal S^{(t)},I^{src};\Pi^{src});t), \ t=0,1,\cdots,T-1
S(t+1)=S(t)+γ(t)⋅Gθ(S(t),∇S(t)L(S(t),Isrc;Πsrc);t), t=0,1,⋯,T−1
其中 γ ( t ) \gamma(t) γ(t)定义更新尺度。类似梯度下降,期望的衰减调度 γ ( t ) \gamma(t) γ(t)和较小的 T T T,使模型能预测初始的粗糙表达,并快速细化。本文使用DDIM中的余弦调度,并使用带稀疏卷积的3D UNet作为 G θ G_\theta Gθ。迭代过程使得3D表达能够被细化从而提高质量,同时能够使用更高效、更容易学习的小网络。
4. 训练 & 推断
对每个场景,从几何脚手架
M
\mathcal M
M初始化场景表达
S
(
0
)
\mathcal S^{(0)}
S(0),并进行
T
T
T步迭代细化。为增强泛化性,本文在训练时对源视图
I
s
r
c
I^{src}
Isrc和新视图
I
t
g
t
I^{tgt}
Itgt均进行了渲染,并传播梯度到
G
θ
G_\theta
Gθ和
f
m
l
p
f_{mlp}
fmlp(注意
G
θ
G_\theta
Gθ的更新只使用源视图的梯度)。对模型进行跨场景训练,总的损失为
L
=
L
m
s
e
(
I
^
,
I
)
+
λ
l
p
i
p
s
L
l
p
i
p
s
(
I
^
,
I
)
+
λ
r
e
g
L
r
e
g
(
G
)
L=L_{mse}(\hat I,I)+\lambda_{lpips}L_{lpips}(\hat I,I)+\lambda_{reg}L_{reg}(\mathcal G)
L=Lmse(I^,I)+λlpipsLlpips(I^,I)+λregLreg(G)
其中
L
m
s
e
L_{mse}
Lmse为光度损失,
L
l
p
i
p
s
L_{lpips}
Llpips为感知损失,
L
r
e
g
L_{reg}
Lreg为正则化损失(使高斯
G
\mathcal G
G扁平化以和表面对齐):
L
r
e
g
(
G
)
=
∑
i
max
(
0
,
d
i
min
−
ϵ
)
L_{reg}(\mathcal G)=\sum_i\max(0,d_i^{\min}-\epsilon)
Lreg(G)=i∑max(0,dimin−ϵ)
其中 d i min d_i^{\min} dimin是高斯 g i g_i gi 3尺度中的最小值。
推断:给定预训练重建网络 G θ G_\theta Gθ和神经高斯解码器 f M L P f_{MLP} fMLP,可重建新场景。输入新场景图像 I s r c I^{src} Isrc和3D高斯初始化 S ( 0 ) \mathcal S^{(0)} S(0),迭代计算梯度 ∇ S \nabla_{\mathcal S} ∇S,细化3D表达。最后,将 S ( T ) \mathcal S^{(T)} S(T)转化为标准3D高斯 G ( T ) \mathcal G^{(T)} G(T)以进行实时栅格化。
实施细节:使用下采样的激光雷达点作为初始化高斯 S ( 0 ) \mathcal S^{(0)} S(0)的位置;高斯尺度被初始化为各向同性的,为第三近的点的距离。旋转被初始化为identity,不透明度被初始化为0.7。其它维度被随机初始化。未使用3DGS中的球面谐波。3D梯度 ∇ S ( t ) L ( S ( t ) ) \nabla_{\mathcal S^{(t)}}L(\mathcal S^{(t)}) ∇S(t)L(S(t))在输入网络前,被跨点逐通道归一化。动态场景为静态背景、动态参与者和远处区域使用3个网络,输出层使用tanh激活函数。逐场景重建步数 T = 24 T=24 T=24。
泛化能力:G3R能跨数据集泛化,即在A数据集上训练的模型,在B数据集上测试,可超过其它直接在B数据集上训练的方法的性能;若进一步在B数据集上使用少量数据微调,可达到与直接在B数据集上训练的G3R相当性能。
看上去本文方法是两步训练,第一步训练具有泛化能力的网络 G θ , f m l p G_\theta,f_{mlp} Gθ,fmlp,第二步是逐场景训练高斯 S \mathcal S S(速度较快)。此外,和传统3DGS不同,本文方法好像不能在训练过程中改变(静态)高斯数量(当然应该可结合进来,但速度会受到影响)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











