







 本文介绍了卷积神经网络的基础知识,包括卷积层的结构、图像获取过程、图像类型,详细阐述了卷积、padding和stride的概念,并通过PyTorch代码展示了卷积层的使用。此外,还讨论了下采样中的MaxPooling操作和一个简单的卷积神经网络的构建与训练过程。
本文介绍了卷积神经网络的基础知识,包括卷积层的结构、图像获取过程、图像类型,详细阐述了卷积、padding和stride的概念,并通过PyTorch代码展示了卷积层的使用。此外,还讨论了下采样中的MaxPooling操作和一个简单的卷积神经网络的构建与训练过程。
convolutional neural network
目录
revision
全连接:网络全由线性层串起来。每一个输入结点都要参与到下一层任何一个输出结点的计算上。 处理输入数据时,把正方形像素变成了一长条,损失了空间信息。

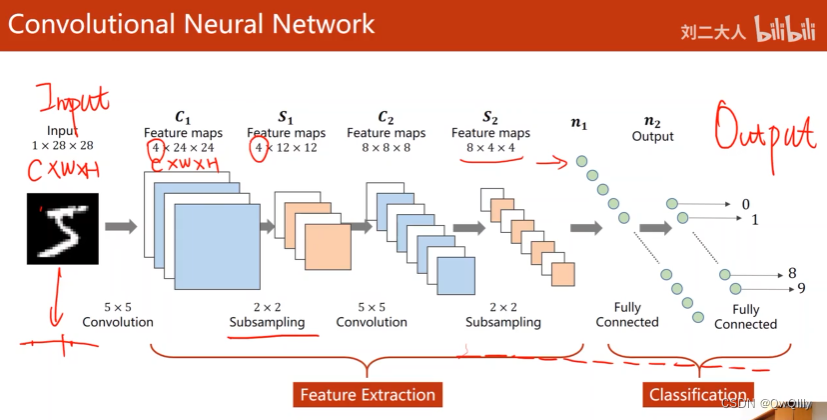
卷积神经网络的结构
卷积层:保留图像的空间特征
图像获取过程
- 有的手机像素数量会虚标。一个电阻测一个像素值。测出2*2之后,做插值变成3*3
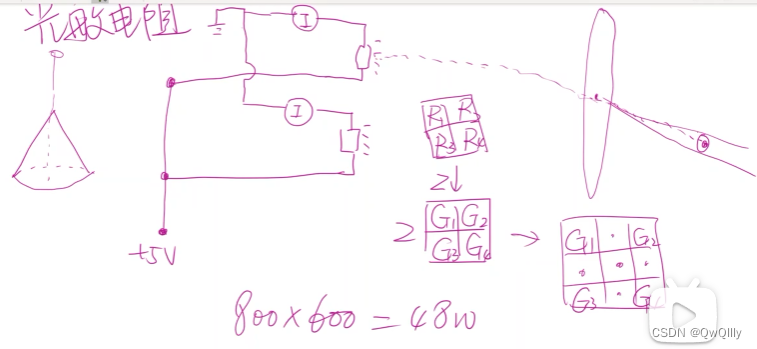
- 处理一个像素,布局传感器时,可能有2个绿传感器,1个红传感器,1个蓝传感器。来自3个不同的光敏元器件,光照强度不同,电阻值不同。(蓝色传感器对蓝色波段的光更敏感。。)经过转换后得到红色、绿色、蓝色颜色值的分量R G B

图像类型
栅格图像
光栅图也叫做位图、点阵图、像素图,简单的说,就是最小单位由像素构成的图,只有点的信息,缩放时会失真。每个像素有自己的颜色,类似电脑里的图片都是像素图,你把它放很大就会看到点变成小色块了。
矢量图像:程序生成的,描述圆心 直径 边的颜色 填充颜色
矢量图,就是使用直线和曲线来描述的图形,构成这些图形的元素是一些点、线、矩形、多边形、圆和弧线等,它们都是通过数学公式计算获得的,具有编辑后不失真的特点。例如一幅画的矢量图形实际上是由线段形成外框轮廓,由外框的颜色以及外框所封闭的颜色决定画显示出的颜色。
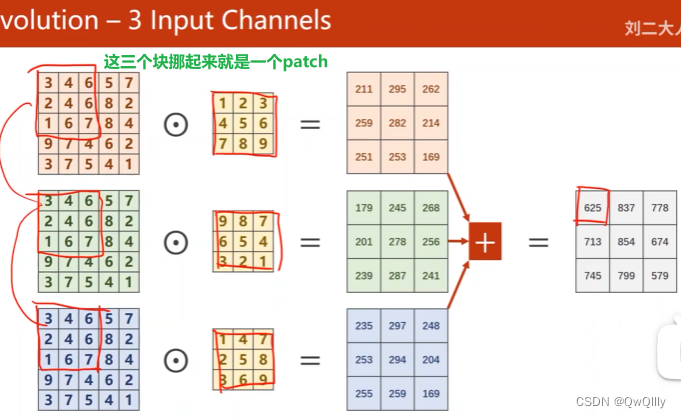
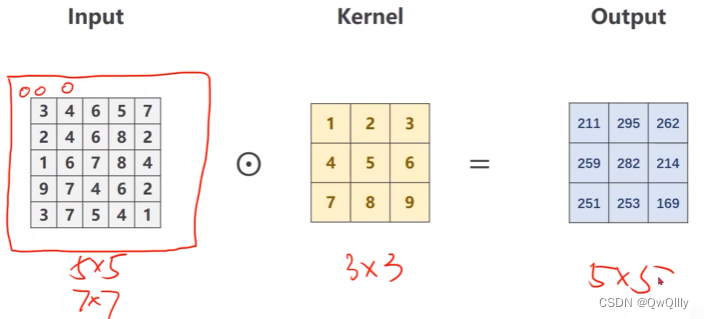
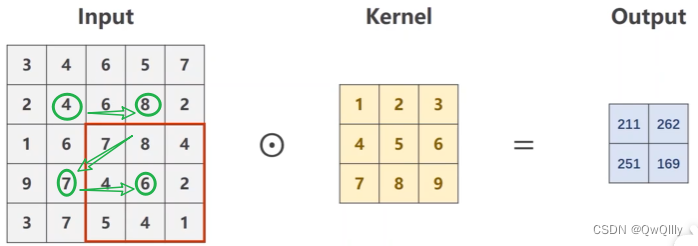
卷积(注意看图)
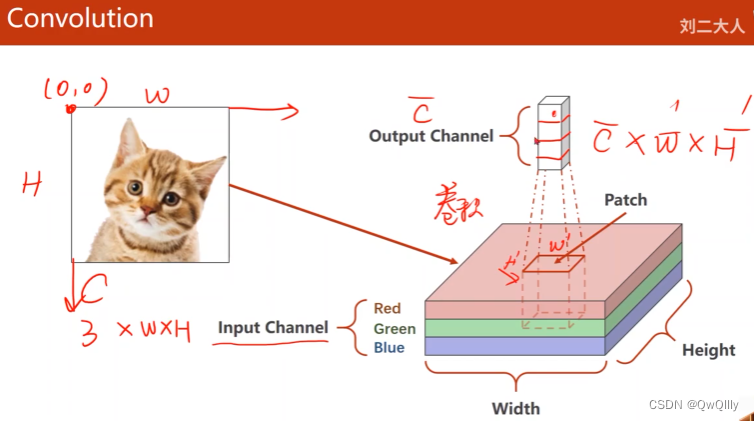
总结:输入通道数等于卷积核的通道数, 卷积核的个数等于输出通道数
格子内对应做数乘
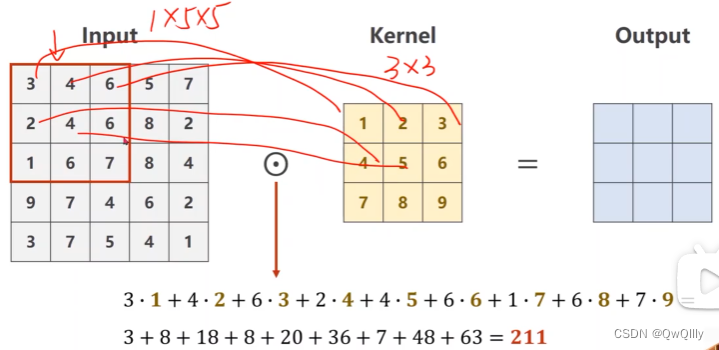
记住一个公式,width_in - kernel_size + 1就是输出的width 和 height。
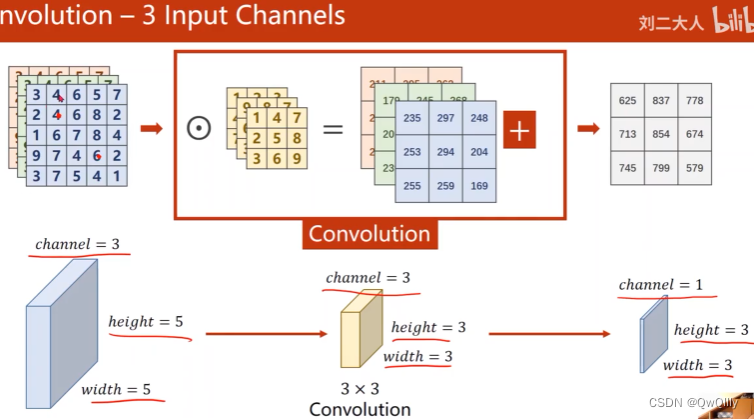
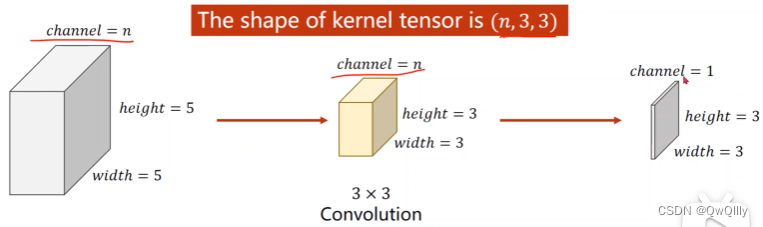
输出channel变成n时
N输入通道, M输出通道
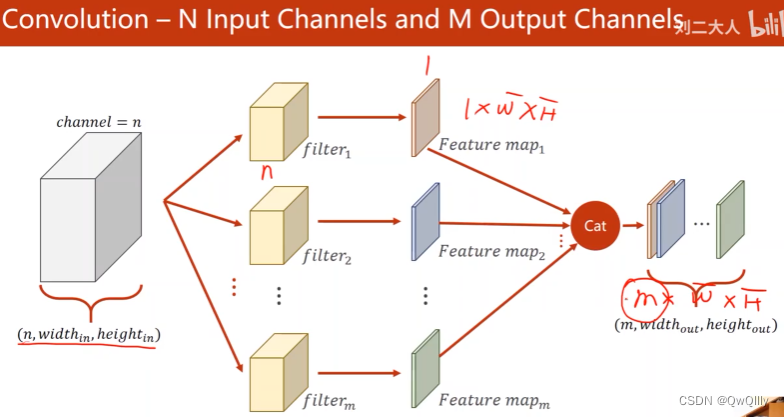 需要的卷积核维度总结 卷积核大小一般是奇数
需要的卷积核维度总结 卷积核大小一般是奇数

pytorch模块代码测试
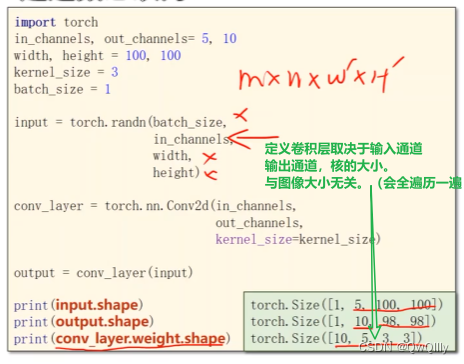
卷积层中常见参数
1.padding
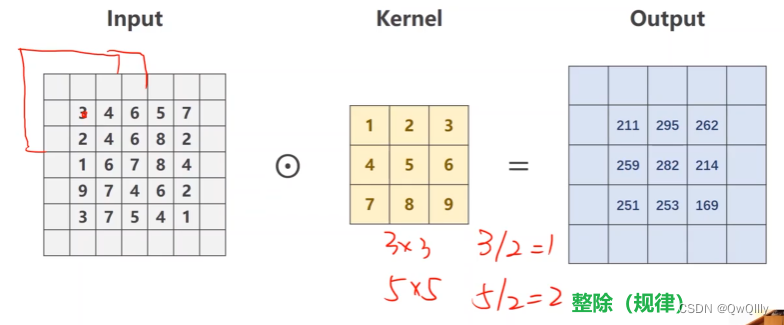
想得到输出也是5*5的矩阵,那么需要在输入矩阵外填充一圈、两圈。。。 这个过程叫padding
(n+2*p-f)/s向下取整+1
代码
Conv2d — PyTorch 2.0 documentation
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1,1,5,5)
conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,padding=1,bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output) 输出结果: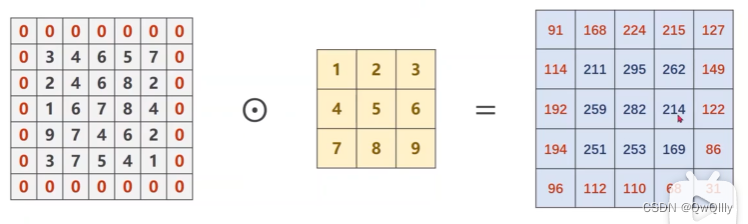
2.stride
stride=2 :步长为2,即:中心一次跳2格
作用:有效降低图像的宽度和高度。
padding默认是valid,stride默认是1
代码:
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1,1,5,5)
conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,stride=2,bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)下采样
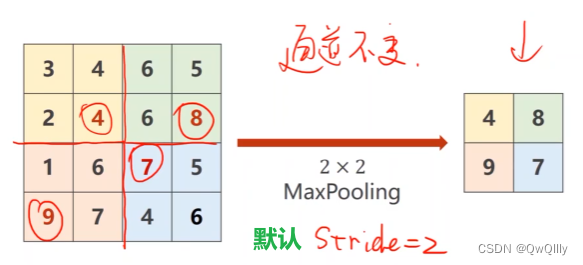
使用较多的方法是 MaxPooling (最大池化层,没有权重)
通道数量不变,用2*2时,大小变为原来的一半
简单介绍及作用
CNN基础知识——池化(pooling) - 知乎 (zhihu.com)
(9条消息) MaxPooling的作用_fu_shuwu的博客-优快云博客
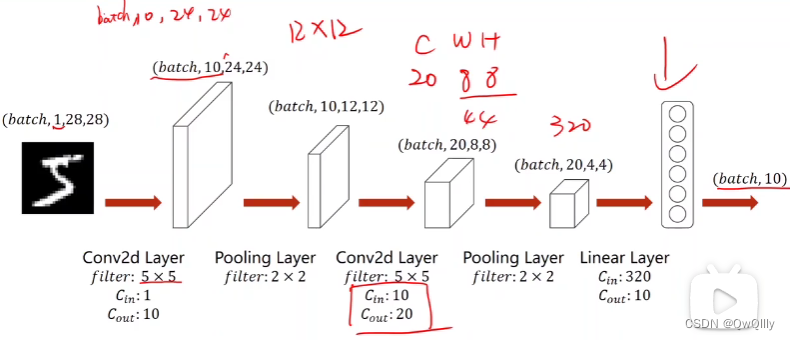
一个简单的卷积神经网络
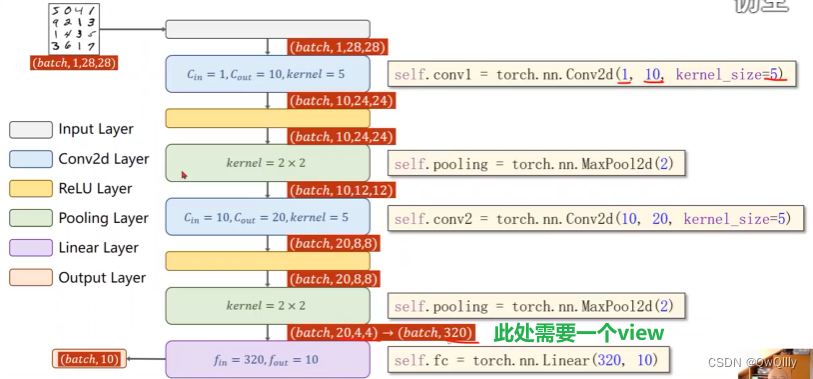
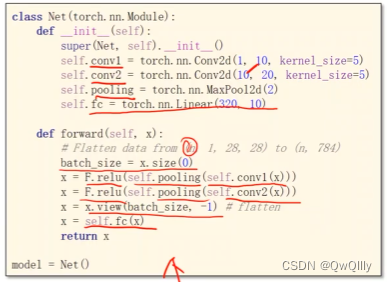
代码:
import torch
from torch.utils.data import DataLoader #我们要加载数据集的
from torchvision import transforms #数据的原始处理
from torchvision import datasets #pytorch十分贴心的为我们直接准备了这个数据集
import torch.nn.functional as F#激活函数
import torch.optim as optim
batch_size = 64
#我们拿到的图片是pillow,我们要把他转换成模型里能训练的tensor也就是张量的格式
transform = transforms.Compose([transforms.ToTensor()])
#加载训练集,pytorch十分贴心的为我们直接准备了这个数据集,注意,即使你没有下载这个数据集
#在函数中输入download=True,他在运行到这里的时候发现你给的路径没有,就自动下载
train_dataset = datasets.MNIST(root='../data', train=True, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size)
#同样的方式加载一下测试集
test_dataset = datasets.MNIST(root='../data', train=False, download=True, transform=transform)
test_loader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size)
#接下来我们看一下模型是怎么做的
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
#定义了我们第一个要用到的卷积层,因为图片输入通道为1,第一个参数就是1
#输出的通道为10,kernel_size是卷积核的大小,这里定义的是5x5的
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
#看懂了上面的定义,下面这个你肯定也能看懂
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
#再定义一个池化层
self.pooling = torch.nn.MaxPool2d(2)
#最后是我们做分类用的线性层
self.fc = torch.nn.Linear(320, 10)
#下面就是计算的过程
def forward(self, x):
# Flatten data from (n, 1, 28, 28) to (n, 784)
batch_size = x.size(0) #这里面的0是x大小第1个参数,自动获取batch大小
#输入x经过一个卷积层,之后经历一个池化层,最后用relu做激活
x = F.relu(self.pooling(self.conv1(x)))
#再经历上面的过程
x = F.relu(self.pooling(self.conv2(x)))
#为了给我们最后一个全连接的线性层用
#我们要把一个二维的图片(实际上这里已经是处理过的)20x4x4张量变成一维的
x = x.view(batch_size, -1) # flatten
#经过线性层,确定他是0~9每一个数的概率
x = self.fc(x)
return x
model = Net()#实例化模型
#把计算迁移到GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#定义一个损失函数,来计算我们模型输出的值和标准值的差距
criterion = torch.nn.CrossEntropyLoss()
#定义一个优化器,训练模型咋训练的,就靠这个,他会反向的更改相应层的权重
optimizer = optim.SGD(model.parameters(),lr=0.1,momentum=0.5)#lr为学习率
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):#每次取一个样本
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
#优化器清零
optimizer.zero_grad()
# 正向计算一下
outputs = model(inputs)
#计算损失
loss = criterion(outputs, target)
#反向求梯度
loss.backward()
#更新权重
optimizer.step()
#把损失加起来
running_loss += loss.item()
#每300次输出一下数据
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():#不用算梯度
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
#我们取概率最大的那个数作为输出
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
#计算正确率
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
if epoch % 10 == 9:
test()
用显卡的代码修改
把模型,和输入数据扔到显卡上即可。
1. Move Model to GPU
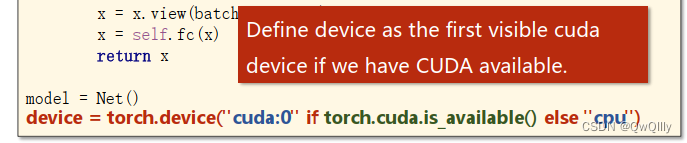

2. Move Tensors to GPU

描述性能的技巧
从错误率的角度描述性能的提升:
从百分之3 降低到百分之2,降低了1/3,有百分之30多的改进



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









