







 在进行Hudi测试时,遇到一个错误:当分区列包含中文字符时,如'春秋',系统抛出URISyntaxException。问题出现在文件路径中,建议避免使用中文作为分区列,可以考虑使用英文或拼音代替,以解决此类问题。
在进行Hudi测试时,遇到一个错误:当分区列包含中文字符时,如'春秋',系统抛出URISyntaxException。问题出现在文件路径中,建议避免使用中文作为分区列,可以考虑使用英文或拼音代替,以解决此类问题。
在做hudi测试的时候 发现 如果hudi的分区列是 中文字符的 就会报 先下面的错误 hdfs://linux01:9000/hudi/insertHDFS/ggggggg/ä¸å½/eb4ddae6-9841-469b-9fed-c2375f13d616-0_2-21-28_20210122113859.parquet
在gggggggg目录下面报乱码这个是我的分区列 ä¸å½ 是中文字符报这个问题 , 以后用英文吧 或者其他的 实在不行上拼音 嘎嘎
16241 [qtp1096084691-76] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - #files found in partition (春秋) =2, Time taken =2
16241 [qtp1096084691-74] INFO org.apache.hudi.common.table.view.HoodieTableFileSystemView - Adding file-groups for partition :default, #FileGroups=1
16241 [qtp1096084691-74] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - addFilesToView: NumFiles=3, FileGroupsCreationTime=1, StoreTimeTaken=0
16241 [qtp1096084691-74] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - Time to load partition (default) =4
16241 [qtp1096084691-76] INFO org.apache.hudi.common.table.view.HoodieTableFileSystemView - Adding file-groups for partition :春秋, #FileGroups=1
16241 [qtp1096084691-76] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - addFilesToView: NumFiles=2, FileGroupsCreationTime=0, StoreTimeTaken=0
16241 [qtp1096084691-76] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - Time to load partition (春秋) =4
16242 [qtp1096084691-70] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - Pending Compaction instant for (FileSlice {fileGroupId=HoodieFileGroupId{partitionPath='三国', fileId='eb4ddae6-9841-469b-9fed-c2375f13d616-0'}, baseCommitTime=20210122113859, baseFile='HoodieDataFile{fullPath=hdfs://linux01:9000/hudi/insertHDFS/ggggggg/三国/eb4ddae6-9841-469b-9fed-c2375f13d616-0_2-21-28_20210122113859.parquet, fileLen=435686}', logFiles='[]'}) is :Option{val=null}
16242 [qtp1096084691-74] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - Pending Compaction instant for (FileSlice {fileGroupId=HoodieFileGroupId{partitionPath='default', fileId='7570a823-0c9c-4c9c-9ac1-4b7049bda06a-0'}, baseCommitTime=20210122113859, baseFile='HoodieDataFile{fullPath=hdfs://linux01:9000/hudi/insertHDFS/ggggggg/default/7570a823-0c9c-4c9c-9ac1-4b7049bda06a-0_0-21-26_20210122113859.parquet, fileLen=432566}', logFiles='[]'}) is :Option{val=null}
16242 [qtp1096084691-76] INFO org.apache.hudi.common.table.view.AbstractTableFileSystemView - Pending Compaction instant for (FileSlice {fileGroupId=HoodieFileGroupId{partitionPath='春秋', fileId='38955f0a-4891-412d-aa3a-ff83cb85f81e-0'}, baseCommitTime=20210122113859, baseFile='HoodieDataFile{fullPath=hdfs://linux01:9000/hudi/insertHDFS/ggggggg/春秋/38955f0a-4891-412d-aa3a-ff83cb85f81e-0_1-21-27_20210122113859.parquet, fileLen=435503}', logFiles='[]'}) is :Option{val=null}
16243 [qtp1096084691-76] INFO org.apache.hudi.timeline.service.FileSystemViewHandler - TimeTakenMillis[Total=6, Refresh=0, handle=6, Check=0], Success=true, Query=partition=%E6%98%A5%E7%A7%8B&basepath=%2Fhudi%2FinsertHDFS%2Fggggggg&lastinstantts=20210122113859&timelinehash=1dd7dcd13f88921e2bf8ec650caa2f6f9c7c9b224d72d86a2e0a453368b72d9e, Host=windows:51997, synced=false
16243 [qtp1096084691-74] INFO org.apache.hudi.timeline.service.FileSystemViewHandler - TimeTakenMillis[Total=7, Refresh=1, handle=6, Check=0], Success=true, Query=partition=default&basepath=%2Fhudi%2FinsertHDFS%2Fggggggg&lastinstantts=20210122113859&timelinehash=1dd7dcd13f88921e2bf8ec650caa2f6f9c7c9b224d72d86a2e0a453368b72d9e, Host=windows:51997, synced=false
16243 [qtp1096084691-70] INFO org.apache.hudi.timeline.service.FileSystemViewHandler - TimeTakenMillis[Total=7, Refresh=1, handle=6, Check=0], Success=true, Query=partition=%E4%B8%89%E5%9B%BD&basepath=%2Fhudi%2FinsertHDFS%2Fggggggg&lastinstantts=20210122113859&timelinehash=1dd7dcd13f88921e2bf8ec650caa2f6f9c7c9b224d72d86a2e0a453368b72d9e, Host=windows:51997, synced=false
16274 [Executor task launch worker for task 32] ERROR org.apache.spark.executor.Executor - Exception in task 0.0 in stage 28.0 (TID 32)
java.lang.RuntimeException: java.net.URISyntaxException: Illegal character in path at index 46: hdfs://linux01:9000/hudi/insertHDFS/ggggggg/ä¸å½/eb4ddae6-9841-469b-9fed-c2375f13d616-0_2-21-28_20210122113859.parquet
at org.apache.hudi.common.table.timeline.dto.FilePathDTO.toPath(FilePathDTO.java:54)
at org.apache.hudi.common.table.timeline.dto.FileStatusDTO.toFileStatus(FileStatusDTO.java:102)
at org.apache.hudi.common.table.timeline.dto.BaseFileDTO.toHoodieBaseFile(BaseFileDTO.java:46)
at org.apache.hudi.common.table.timeline.dto.FileSliceDTO.toFileSlice(FileSliceDTO.java:58)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$generateCompactionPlan$85ff16a$1(HoodieMergeOnReadTableCompactor.java:207)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:125)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:125)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.generic.Growable$class.$plus$plus$eq(Growable.scala:59)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:104)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:48)
at scala.collection.TraversableOnce$class.to(TraversableOnce.scala:310)
at scala.collection.AbstractIterator.to(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toBuffer(TraversableOnce.scala:302)
at scala.collection.AbstractIterator.toBuffer(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toArray(TraversableOnce.scala:289)
at scala.collection.AbstractIterator.toArray(Iterator.scala:1334)
at org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$15.apply(RDD.scala:990)
at org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$15.apply(RDD.scala:990)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.net.URISyntaxException: Illegal character in path at index 46: hdfs://linux01:9000/hudi/insertHDFS/ggggggg/ä¸å½/eb4ddae6-9841-469b-9fed-c2375f13d616-0_2-21-28_20210122113859.parquet
at java.net.URI$Parser.fail(URI.java:2848)
at java.net.URI$Parser.checkChars(URI.java:3021)
at java.net.URI$Parser.parseHierarchical(URI.java:3105)
at java.net.URI$Parser.parse(URI.java:3053)
at java.net.URI.<init>(URI.java:588)
at org.apache.hudi.common.table.timeline.dto.FilePathDTO.toPath(FilePathDTO.java:52)
... 38 more
16274 [Executor task launch worker for task 33] ERROR org.apache.spark.executor.Executor - Exception in task 1.0 in stage 28.0 (TID 33)
java.lang.RuntimeException: java.net.URISyntaxException: Illegal character in path at index 45: hdfs://linux01:9000/hudi/insertHDFS/ggggggg/æ¥ç§/38955f0a-4891-412d-aa3a-ff83cb85f81e-0_1-21-27_20210122113859.parquet
at org.apache.hudi.common.table.timeline.dto.FilePathDTO.toPath(FilePathDTO.java:54)
at org.apache.hudi.common.table.timeline.dto.FileStatusDTO.toFileStatus(FileStatusDTO.java:102)
at org.apache.hudi.common.table.timeline.dto.BaseFileDTO.toHoodieBaseFile(BaseFileDTO.java:46)
at org.apache.hudi.common.table.timeline.dto.FileSliceDTO.toFileSlice(FileSliceDTO.java:58)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$generateCompactionPlan$85ff16a$1(HoodieMergeOnReadTableCompactor.java:207)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:125)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:125)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.generic.Growable$class.$plus$plus$eq(Growable.scala:59)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:104)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:48)
at scala.collection.TraversableOnce$class.to(TraversableOnce.scala:310)
at scala.collection.AbstractIterator.to(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toBuffer(TraversableOnce.scala:302)
at scala.collection.AbstractIterator.toBuffer(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toArray(TraversableOnce.scala:289)
at scala.collection.AbstractIterator.toArray(Iterator.scala:1334)
at org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$15.apply(RDD.scala:990)
at org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$15.apply(RDD.scala:990)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
因为我的分区字段时中文。
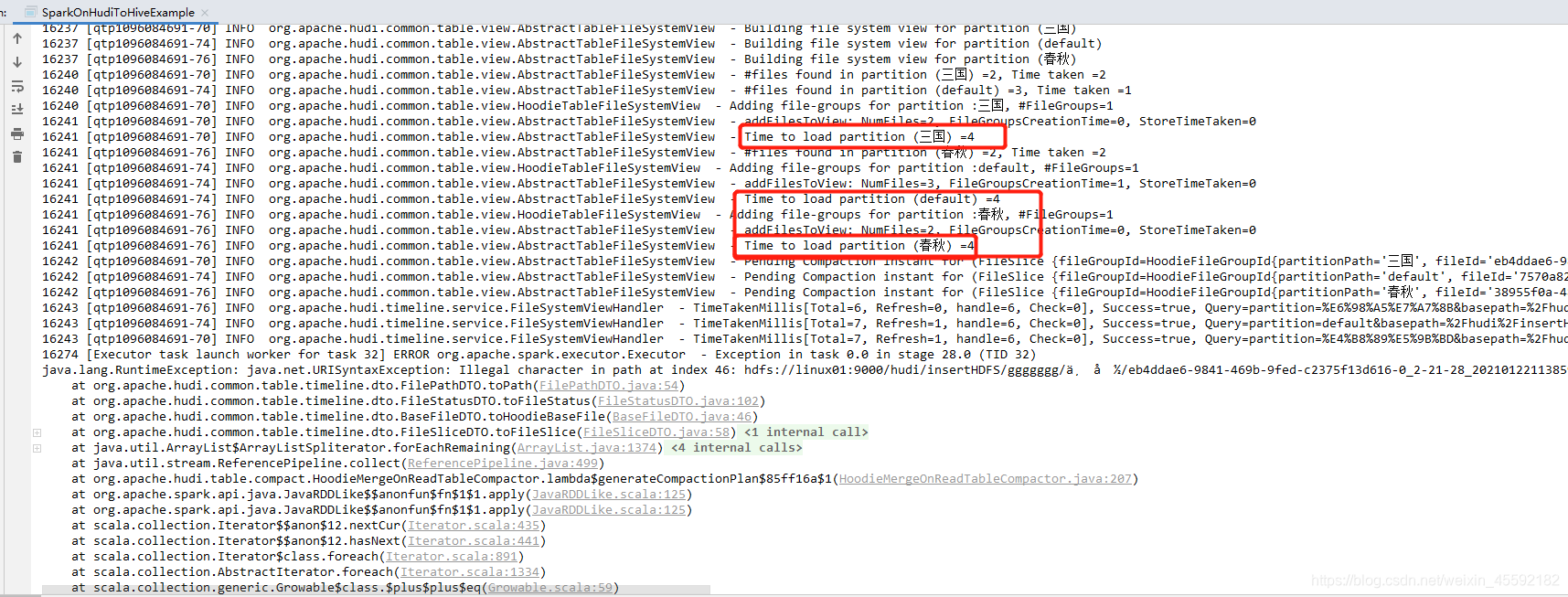
所以尽量避免中文字符作为hudi分区列 是在不行用拼音 总可以吧 !

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









