







前言
需求是这样的,要求用纯C写一个my shell,可以实现
1.help 打印help文档
2.set variable value 设置变量variable为value并以数组形式存储
3.print variable 打印变量
4.run xxx 以每行的内容为一个命令,依次执行文件所有指令
要求完成三个.C文件,分别为shell.c interpreter.c shellmemory.c
他们的功能分别如下:
shell.c
main方法和parse方法。parse用来解析输入并把带空格的输入存放到一个 * tokens[] 中,这个数组中每个下标存放的地址对应着每个单词string的首地址。main方法把parse转换后的* tokens[]传给interpreter.c
interpreter.c
对于help set print run四个指令分别编写对应程序,如果输入不规范,输出 Unknown Command。
shellmemory.c
用来设置变量和遍历(查找)变量。
Struct MEM{char *var;char value;}
使用Struct数组。
代码
这里只给出shellmemory.c的代码。
#include<stdlib.h>
#include<string.h>
#define buffSize 100
struct MEM{
char *value;
char *var;
};
struct MEM *array;
int len;
首先是把指针p1的内容复制到p2,需要用到二级指针。
void copy(char *source, char **des){
int s = 0;
char buffer[buffSize];
while (*(source + s) != '\0'){
buffer[s] = *(source + s);
s++;
}
buffer[s] = *(source + s);
*des = _strdup(buffer);
}
内存方面,对于指向一个struct的指针p,p++会自动指向相邻的下一块地址。本例中,指向array的地址自动+8bytes,也就是两个char * 的长度(8位16进制地址,(8*4bit)/8bit =4bytes)。可通过
printf("%p\n", &(array + i)->var); 验证。
void setVar(char *name, char *value){
//create an array when first add
if (array == NULL) {
array = malloc(100 * sizeof(struct MEM));
copy(name, &array->var);
copy(value, &array->value);
len = 1;
return;
}
int ex = 0;
int i = 0;
// traverse the array
for (i = 0; i < len; i++){
if (strcmp((array+i)->var, name) == 0){
ex = 1;
break;
}
}
if (ex){//if exist
copy(value, &(array + i)->value);
}
else { //add to memory
copy(name, &(array + i)->var);
copy(value, &(array + i)->value);
len++;
}
}

上面是value的地址,下面是var的地址。
int PrintVar(char *name,char **res){
for (int i = 0; i < len; i++){
if (strcmp((array+i)->var, name) == 0){
copy((array + i)->value, res);// pass the address
//printf("%s\n",(array+i)->value); //or print out here
/* //to see what we store
char *p = (array + i)->var;
if (*p) {
printf("%d\n", *p);
p++;
}
*/
/* to have a test about pointer
printf("%p\n", (array + i)->var);
if (*(array + i)->var) {
printf("%d\n", *(array + i)->var);
((array + i)->var )++;
}
printf("%p\n", (array + i)->var);
*/
/*
//to see what the addresses exactly are
printf("%p\n", &(array + i)->value);
printf("%p\n", &(array + i)->var);
*/
return 1;
}
}
return 0;
}
注意点
结构体取值
对于结构体指针temp中的指针value,(*temp).value等价于temp->value
二级指针
如果想要通过参数传递的方式改变一个指针,需要使用二级指针。
**p :二级指针,表示p所指向的地址里面存放的是一个指向类型的指针。
*p:一级指针,表示p所指向的地址里面存放的是一个类型的值。
简单来说,在参数传递中,一级指针可以改值,二级指针可以改指针。
下面举个例子加深对指针的记忆。
&array->var 就是结构体array中var的地址,这个地址里放的是var(本身也是指针,本身是目标内容的首地址)。
*(array->var)就是var指向的内容,(array->var)++ 就是var指向的内容的首地址+1。下面的代码就是说,如果char *var指向的地址不为空,则打印该字母的ASCII码,并把var指向的地址++,不断读取直到为空。
printf("%p\n", (array + i)->var);
if (*(array + i)->var) {
printf("%d\n", *(array + i)->var);
((array + i)->var )++;
}
printf("%p\n", (array + i)->var);
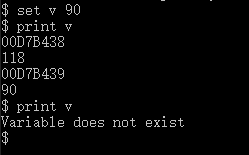
如果再想print v,控制台给出"Variable does not exist",因为现在var存储的地址已经+1,内容变成了NULL空,和v这个字符不匹配。
malloc
malloc是开辟一块存储空间并传回首地址。值得注意的是,本例我尝试array = malloc(sizeof(struct MEM)); Windows VS2013环境下,在set进一个数据x后,由于空间满了,下一个被set进的变量将会自动放到另外某一块地址,并在那里连续存储(存储上限暂不知道),第一个set的x被清除回收。
所以务必注意分配足够的空间,否则可能引发数据丢失,
file操作
http://c.biancheng.net/view/2054.html
FILE *fp = fopen(name, “r”);
以只读方式打开,成功则返回句柄,失败返回NULL
fgets(buff, size, fp)
从fp读取至多size个字符到buff中。Windows下注意文件每行结尾的细节。比如我自己定义的SCRIPT.TXT,最后以\n\0结尾,\n被读入,需要做额外处理。
网上说Windows下文件换行\r\n,但是我测试的时候并没有发现\r,仍然只是以\n结尾。具体什么情况未知。
值得注意的是在linux环境下不能想VS里一样用gets从控制台接受输入,要用fgets(buff,size,stdin),这种情况结尾会读入\n,而Windows下控制台不会。
后记
其实这个任务本身不难,就是有很多细节让人抓狂。对于我这种不常写纯C语言、不太熟悉指针的人来说有点不友好,各种指针的应用需要好好沉淀吸收。

















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









