







 本文深入探讨Spark的起源、MapReduce的局限性以及Spark的优势。通过对比,阐述Spark如何通过内存计算、DAG和RDD优化处理速度和易用性。文章还介绍了Spark的基础概念、提交过程、Web UI以及性能优化策略,旨在帮助读者更好地理解和优化Spark应用。
本文深入探讨Spark的起源、MapReduce的局限性以及Spark的优势。通过对比,阐述Spark如何通过内存计算、DAG和RDD优化处理速度和易用性。文章还介绍了Spark的基础概念、提交过程、Web UI以及性能优化策略,旨在帮助读者更好地理解和优化Spark应用。
作者介绍
周明,去哪网算法开发工程师。2018年加入去哪儿网,主要从事推荐算法相关工作。
这篇文章可以带给你什么
-
不太了解 Spark :可以快速对 Spark 有个简单且清晰的认知,同时知道Spark可以用来做什么,对于经常处理大数据的同学可以思考如何运用到自己的工作中;
-
刚开始写 Spark :一起来回顾 Spark 基础概念和原理,避免新手那些常见的坑,培养性能优化意识,知道如何做性能调优;
-
Spark 老司机 :一起来回顾 Spark 的三三两两,知识点查缺补漏。
一、Spark 的由来
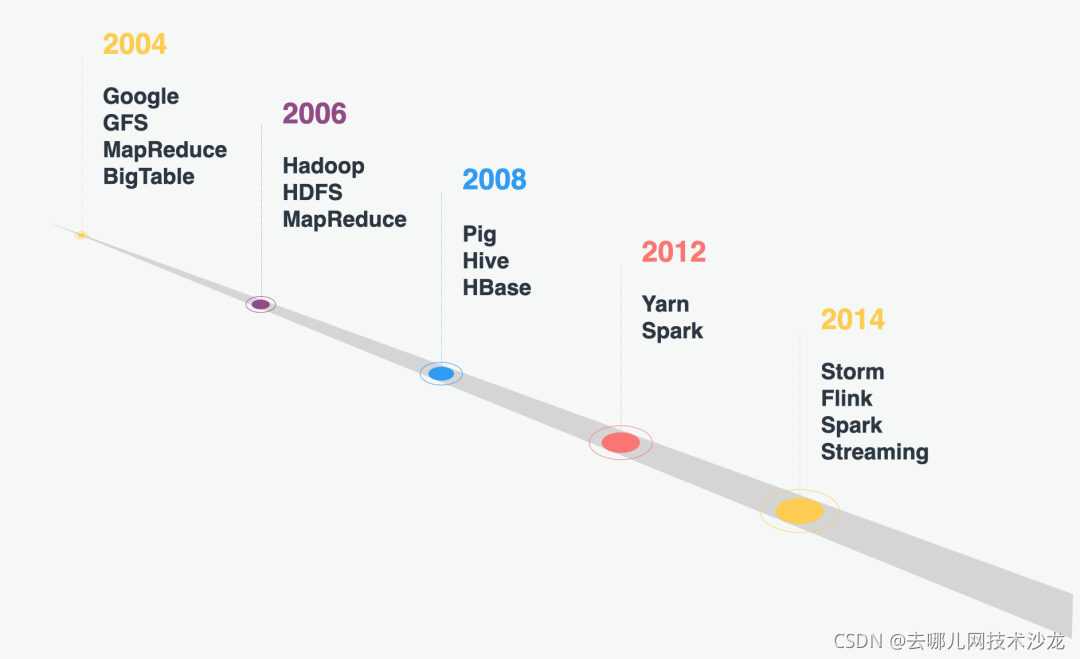
花一些篇幅来讲讲大数据技术的发展史,可以帮助我们更好理解 Spark 诞生的历史背景。
今天我们常说的大数据技术,其实起源于 Google 在 2004 年前后发表的三篇论文,也就是我们经常听到的“三驾马车”,分别是分布式文件系统 GFS 、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统 BigTable 。
2006年,Lucene 开源项目的创始人 Doug Cutting 基于论文原理开发了 Hadoop ,主要包括 Hadoop 分布式文件系统 HDFS 和大数据计算引擎 MapReduce ,Hadoop 一经发布便引起轰动,Yahoo 、百度和阿里巴巴等知名互联网公司逐渐使用 Hadoop 进行大数据存储与计算。
早期使用 MapReduce 进行大数据编程很复杂,于是Yahoo工程师们开发了一种使用类 SQL 语法的脚本语言 Pig , Pig 脚本经过编译后会生成 MapReduce 程序,然后在 Hadoop 上运行。但毕竟是类 SQL 语法,大量 SQL 数据开发者的迁移学习成本还是很高,于是 Facebook 发布了 Hive ,支持使用 SQL 语法进行大数据计算,Hive 会把 SQL 语句转化成 Map 和 Reduce 的计算程序。
在 Hadoop 早期,MapReduce 既是一个执行引擎,又是一个资源调度框架,MapReduce 维护困难且模块臃肿。于是2012年一个专门负责资源调度的系统Yarn诞生了。同年, UC 伯克利 AMP 实验室开发的基于内存计算的 Spark 开始崭露头角。由于 MapReduce 进行复杂大数据计算的时候需要频繁 I/O 磁盘操作,导致使用 MapReduce 执行效率非常慢,而且在当时内存已经突破了容量和成本限制,所以基于内存计算的 Spark 一经推出,立即受到业界的追捧,并逐步替代 MapReduce 在企业应用中的地位。
以上这些计算框架处理的业务场景都被称作批处理计算,而在大数据领域,还有另外一类应用场景,它们需要对实时产生的大量数据进行即时计算,2014 年三个流计算框架 Storm (毫米级计算响应,但吞吐量低)、 Spark Streaming (秒级响应,但吞吐量高) 和 Flink (毫米级计算响应,同时吞吐量高) 成为 Apache 的顶级项目,开启流计算时代。
二、What is MapReduce?
上节我们知道 Spark 带着比 MapReduce 更快更高更强的使命诞生,我们有必要了解什么是 MapReduce 。
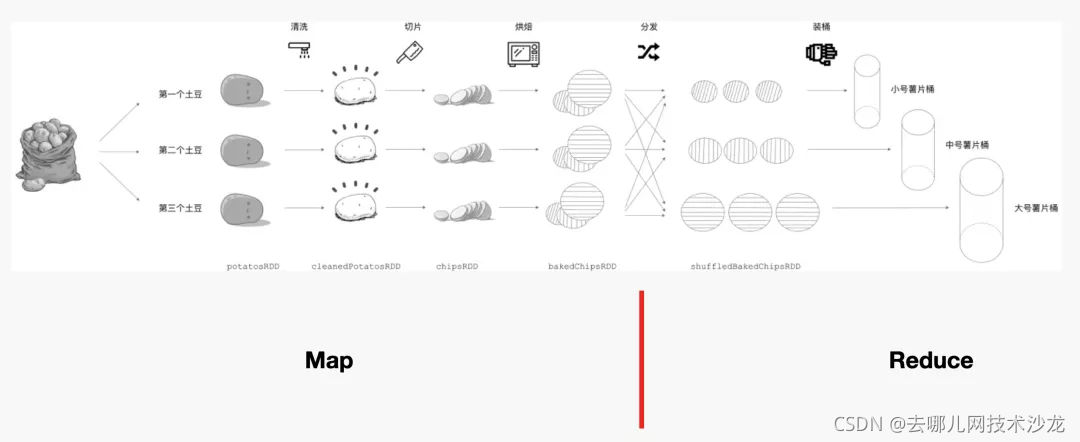
我们从薯片的加工流程来介绍一个MapReduce是如何运作的:
首先,有 3 颗土豆作为原始素材被送上流水线。流水线的第一道工序是清洗
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









