







 本文介绍了在Qunar智能风控中,如何利用Tensorflow for Java和Spark-Scala构建分布式机器学习计算框架。作者分析了项目场景、框架选型原因,选择了Tensorflow for Java和Spark-Scala进行模型预测,强调了性能优化和踩坑经验,展示了从训练模型到服务部署的完整流程,最终实现了高效离线模型预测。
本文介绍了在Qunar智能风控中,如何利用Tensorflow for Java和Spark-Scala构建分布式机器学习计算框架。作者分析了项目场景、框架选型原因,选择了Tensorflow for Java和Spark-Scala进行模型预测,强调了性能优化和踩坑经验,展示了从训练模型到服务部署的完整流程,最终实现了高效离线模型预测。

王辉,2017年加入去哪儿网。 目前负责反爬虫相关风控业务,技术领域涉猎广泛,在风控智能化实践方向的道路上持续探索中。
一. 前言
Qunar 智能风控场景中,风控研发团队经常会应用一些算法模型,来解决复杂场景问题。典型的如神经网络模型,决策树模型等等。而要完成模型从训练到部署预测的全过程,除了模型算法之外,离不开技术框架的支撑。本篇文章将和大家分享一下,在预测服务部署阶段,基于 Tensorflow for Java 和 Spark-Scala 构建分布式机器学习计算框架的实践经验。主要围绕以下几点展开:
- Tensorflow for Java & Spark-Scala 是什么?
- 框架选型和适用场景思考
- 如何使用 Spark-Scala 集成 Tensorflow for Java 构建预测服务?
- 框架实践过程中的优化以及踩坑经验
二. 框架选型
2.1 项目场景
项目的背景,是对手机客户端收集的用户风控数据采集后,构建神经网络模型,离线分析预测用户风险。
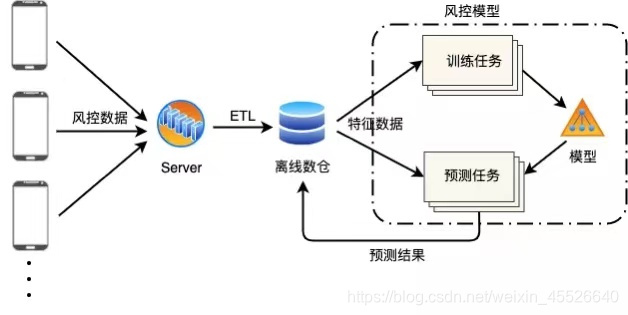
客户端收集的数据量很大,目前阶段小时特征数据量约 300w ,后续还会扩大到千万级别。同时,我们希望每小时执行一次预测任务,那么需要保证一次计算能在小时内完成,否则会出现任务积压。所以即使是离线计算这种实时性要求不高的场景,也依然有着高性能处理的要求。
在这个背景下,我们期望基于大数据分布式机器学习计算框架来提升模型预测效率。
2.2 框架选型
在分布式机器学习计算框架选型上,一类是机器学习框架自身支持的分布式能力,比如Tensorflow、Pytorch两大主流框架都已支持分布式计算;另一类是大数据分布式框架和机器学习框架结合,通过Spark、Flink等大数据框架集成机器学习框架API。
目前虽然机器学习框架逐渐具备分布式能力,但主要目的是解决数据量大、模型参数多场景下的模型训练性能问题。相对于传统大数据分布式框架,优点是对于分布式训练的支持和针对机器学习场景的分布式方案。缺点是在数据归并和多级分层上没有提供很好的解决方案,其次,需要单独搭建和维护集群,增加了运维成本。综合考虑,在分布式预测场景下,采用了大数据框架和机器学习框架结合的方案。
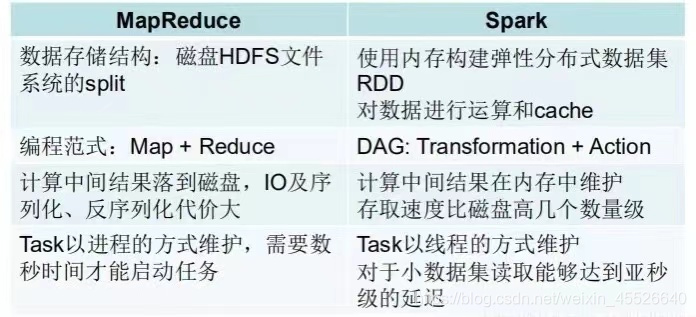
大数据框架通常分为流处理和批处理两类。流处理适用于实时和准实时计算, Flink 、 Storm 、 Spark-Streaming 等都属于流处理框架;批处理适用于离线计算,我们的场景是典型的离线批处理场景,主流的批处理框架目前有 Spark 和 Hadoop 的 MapReduce 。通过框架实现上的对比,可以发现 Spark 基于内存运算虽然消耗更多资源,但在性能上能带来很大的提升。
而在机器学习框架领域, TensorFlow 、 PyTorch 目前分别成为了工业界和学术界使用最广泛的两大框架。TensorFlow 是谷歌的开发者创造的一款开源的深度学习框架,于 2015 年发布。PyTorch 是最新的深度学习框架之一,由 Facebook 的团队开发,并于 2017 年在 GitHub 上开源。
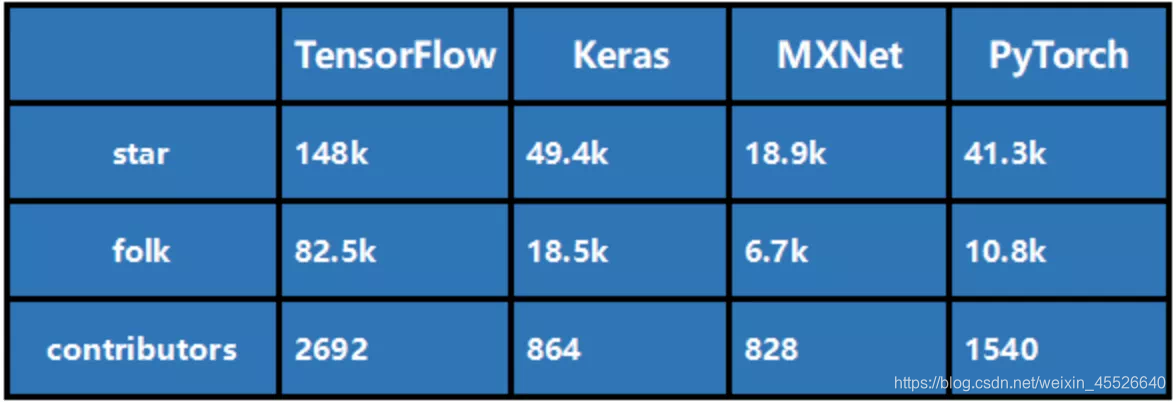
我们从多个维度对比下 Tensorflow 和 Pytorch 两种框架,可以发现:Pytorch 具备更优秀的 API ,上手快,动态图,易调试等优点,适合研究者快速构建模型,迭代速度快。Tensorflow 在多语言支持、跨平台能力、性能、生产部署等方面具备优势,适合于生产部署。这也是为什么 Pytorch 更受学术界欢迎,而 Tensorflow 保持着工业界的主导地位。Tensorflow 和 Pytorch 目前都在试图向对方的优势靠拢,不过短期内这样的现状应该不会改变。

通过上面的分析,结合实际应用场景,风控模型的算法结构并不是很复杂,在 Tensorflow 和 Pytorch 下都能快速构建,因此考虑到模型生产环境部署难度,以及跨平台部署的需求,我们选择 Tensorflow 来构建模型。
2.3 为什么选择Tensorflow for Java & Spark-Scala?
在Spark和Tensorflow集成的方案中,一种是在Python环境中使用PySpark+Tensorflow for Python 来实现,这也是目前多数的实践方案。另一种就是 Java/Scala 环境中 Spark-Scala+Tensorflow for Java 的方案。我们选择第二种方案,主要是出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









