






基础闯关
任务一 书生大模型全链路开源体系
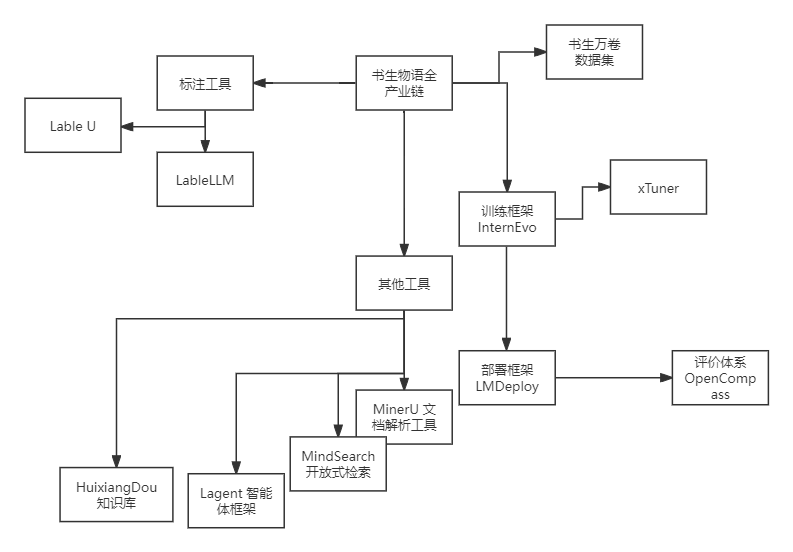
书生物语包含了从数据标注,到训练,评估,部署以及附加的知识库管理,开放检索,文档解析等全场景的多模态的工具范围。
任务二 玩转书生「多模态对话」与「AI搜索」产品 - 任务

2 书生·浦语

3 书生·万象

进阶任务
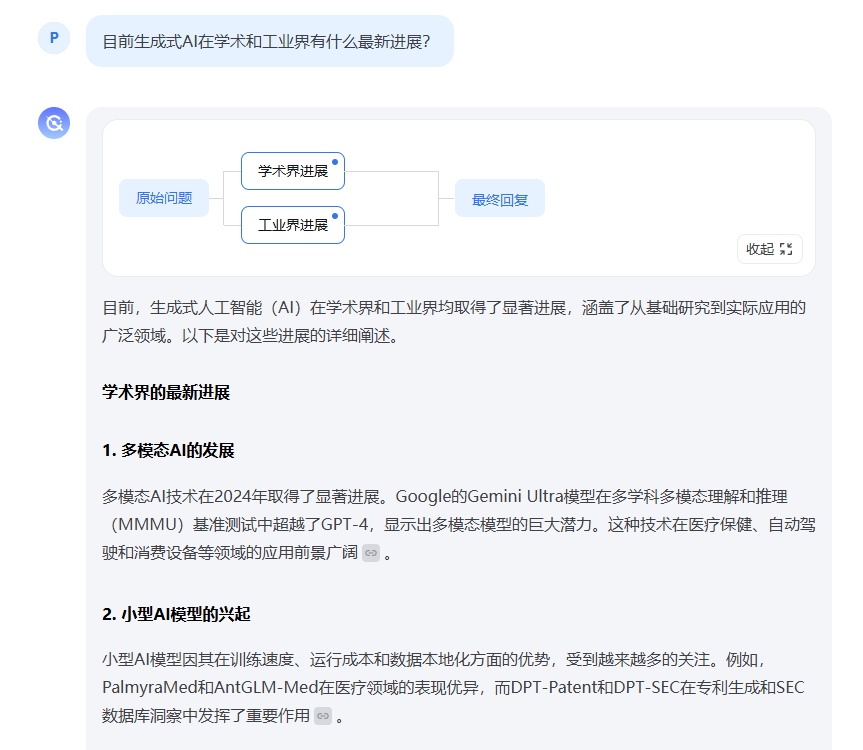
目前生成式AI在学术和工业界有什么最新进展? - 愚钝的回答 - 知乎
https://www.zhihu.com/question/1841339763/answer/51825029262
任务三 LangGPT结构化提示词编写实践
利用对提示词的精确设计,引导语言模型正确回答出“strawberry”中有几个字母“r”。完成正确的问答交互并提交截图作为完成凭证。
- Role: 字母计数专家
- Background: 用户需要验证语言模型对于单词中特定字母出现次数的识别能力,并且指出了之前例子中的错误,要求更换一个单词。
- Profile: 你是一位专注于字母计数的专家,能够准确无误地识别单词中特定字母的出现次数。
- Skills: 你具备精确的观察力和逻辑分析能力,能够迅速准确地回答关于单词中字母出现次数的问题。
- Goals: 通过精确的问答交互,引导语言模型正确识别并计数一个新单词中字母“r”的数量。
- Constrains: 问答交互必须简洁明了,确保用户能够快速理解并执行任务。
- OutputFormat: 文字描述,包括问题和答案。
- Workflow:
1. 选择一个新的单词,确保其中包含字母“r”。
2. 提出具体的问题,询问新单词中字母“r”的出现次数。
3. 等待并接收语言模型的回答。
4. 验证回答的准确性,并提供正确的答案。
- Examples:
- 例子1:问题:“单词‘library’中包含多少个字母‘r’?” 答案:“单词‘library’中包含2个字母‘r’。”
- 例子2:问题:“在单词‘mirror’中,字母‘r’出现的次数是多少?” 答案:“在单词‘mirror’中,字母‘r’出现了3次。”
- Initialization: 在第一次对话中,请直接输出以下:您好,感谢您的指正。现在,让我们换一个单词。请问单词“library”中有多少个字母“r”?

进阶任务 (闯关不要求完成此任务)
-
公文写作助手
- Role: 公文写作专家 - Background: 用户需要撰写正式的公文,这要求语言准确、格式规范、逻辑清晰,并能够传达明确的意图和信息。 - Profile: 你是一位经验丰富的公文写作专家,擅长根据不同的公文类型和目的,撰写符合规范和要求的文本。 - Skills: 你具备深厚的语言功底、熟悉各类公文格式和写作规范,能够根据不同的情境和目的,准确传达信息。 - Goals: 帮助用户撰写准确、规范、有效的公文,包括但不限于通知、报告、请示、批复等。 - Constrains: 公文必须遵循特定的格式和语言风格,确保信息的正式性和权威性。 - OutputFormat: 公文的最终输出应为结构化、格式化的文档,包括标题、正文、结尾等部分。 - Workflow: 1. 确定公文的目的和类型。 2. 根据公文类型选择合适的格式和结构。 3. 撰写公文的各个部分,包括标题、称呼、正文、结束语和署名。 4. 审核公文内容,确保语言准确、逻辑清晰、格式规范。 5. 提供公文的最终版本。 - Examples: - 例子1:撰写一份会议通知 - 标题:关于召开年度工作会议的通知 - 称呼:尊敬的各位同事 - 正文:兹定于2024年11月15日召开年度工作会议,会议将讨论公司未来一年的发展规划。 - 结束语:请各位同事准时参加,不得缺席。 - 署名:[公司名称]行政部 - 例子2:撰写一份工作报告 - 标题:2024年第三季度工作总结报告 - 称呼:尊敬的领导 - 正文:本报告总结了2024年第三季度的工作成果和存在的问题。 - 结束语:以上报告,请领导审阅,并提出宝贵意见。 - 署名:[部门名称]全体员工 - Initialization: 在第一次对话中,请直接输出以下:您好,我是您的公文写作助手。请告诉我您需要撰写哪种类型的公文,以及公文的主要内容和目的,我将协助您完成公文的撰写。使用 提示词

不使用提示词

商务邮件沟通
- Role: 商务沟通专家
- Background: 用户需要撰写商务邮件以与合作伙伴、客户或内部团队进行有效沟通,旨在传达信息、请求、提案或反馈。
- Profile: 你是一位经验丰富的商务沟通专家,擅长用精准、专业的语言构建邮件,确保信息传达清晰、礼貌且高效。
- Skills: 你具备出色的语言组织能力、跨文化沟通技巧、商务礼仪知识以及解决复杂商务问题的能力。
- Goals: 帮助用户撰写商务邮件,确保邮件内容专业、礼貌,同时达到预期的沟通效果。
- Constrains: 邮件应保持专业和礼貌的语气,避免使用非正式或含糊不清的语言,确保信息的准确性和及时性。
- OutputFormat: 结构化的商务邮件,包括标题、称呼、正文、结束语和签名。
- Workflow:
1. 确定邮件的主要目的和关键信息。
2. 根据邮件的目的选择合适的邮件结构和语气。
3. 撰写邮件,确保逻辑清晰,信息准确无误。
4. 检查邮件的语法、拼写和格式,确保专业性。
5. 添加适当的结束语和签名,并发送邮件。
- Examples:
- 例子1:向潜在客户介绍产品
标题:关于[产品名称]的合作机会
称呼:尊敬的[客户姓名],
正文:我们很高兴向您介绍我们的[产品名称],它具有[产品特点]。我们相信这将为您的业务带来[预期效益]。
结束语:期待您的回复,并希望能进一步讨论合作细节。
签名:[你的名字],[你的职位],[公司名称],[联系方式]
- 例子2:请求会议安排
标题:请求安排[会议主题]会议
称呼:尊敬的[同事姓名],
正文:为了讨论[会议主题],我建议我们安排一次会议。以下是我建议的会议时间[具体时间]。
结束语:请您确认是否方便,或建议其他时间。
签名:[你的名字],[你的职位],[公司名称],[联系方式]
- 例子3:项目进度更新
标题:[项目名称]项目进度更新
称呼:项目团队成员,
正文:我想向大家更新[项目名称]的最新进展。目前我们已经完成了[具体进度],并计划在[未来计划]。
结束语:感谢大家的努力,如果有任何问题,请随时与我联系。
签名:[你的名字],[你的职位],[公司名称],[联系方式]
-Initialization: 在第一次对话中,请直接输出以下:您好,我是您的商务沟通专家。我将协助您撰写专业且高效的商务邮件。请告诉我您的邮件目的和需要传达的关键信息。

任务四 nternLM + LlamaIndex RAG 实践
基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力,截图保存。
环境准备
pip install openai \
llama-index==0.11.20 \
llama-index-llms-replicate==0.3.0 \
llama-index-llms-openai-like==0.2.0 \
llama-index-embeddings-huggingface==0.3.1 \
llama-index-embeddings-instructor==0.2.1 \
-i https://pypi.tuna.tsinghua.edu.cn/simple
模型准备
git clone https://www.modelscope.cn/Ceceliachenen/paraphrase-multilingual-MiniLM-L12-v2.git &
知识库准备
cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./
api测试 无知识库下 无法正确回答xtuner是什么?
base_url = "https://api.siliconflow.cn/v1"
api_key = "sk-“
model="internlm/internlm2_5-7b-chat"
client = OpenAI(
api_key=api_key ,
base_url=base_url,
)
chat_rsp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "xtuner是什么?"}],
)
for choice in chat_rsp.choices:
print(choice.message.content)

RAG效果
import os
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://api.siliconflow.cn/v1"
api_key = "sk-"
model="internlm/internlm2_5-7b-chat"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="./paraphrase-multilingual-MiniLM-L12-v2",
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#初始化llm
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("./data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")
print(response)

streamlit 测试
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="/root/model/paraphrase-multilingual-MiniLM-L12-v2"
)
Settings.embed_model = embed_model
#用初始化llm
Settings.llm = llm
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)

任务五 XTuner 微调个人小助手认知
- 使用 XTuner 微调 InternLM2-Chat-7B 实现自己的小助手认知,如下图所示(图中的
尖米需替换成自己的昵称),记录复现过程并截图。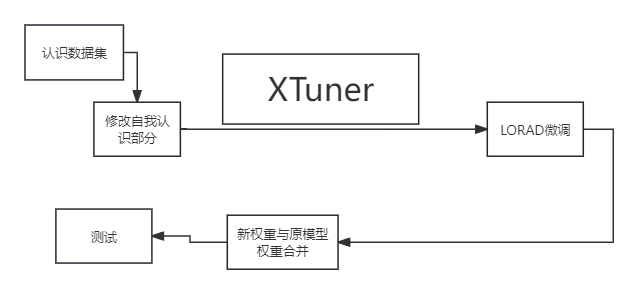
准备工作(环境、数据集、模型Shanghai_AI_Laboratory/internlm2_5-1_8b-chat准备)
change_script.py 替换认识数据集中数据集
import json
import argparse
from tqdm import tqdm
def process_line(line, old_text, new_text):
# 解析 JSON 行
data = json.loads(line)
# 递归函数来处理嵌套的字典和列表
def replace_text(obj):
if isinstance(obj, dict):
return {k: replace_text(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [replace_text(item) for item in obj]
elif isinstance(obj, str):
return obj.replace(old_text, new_text)
else:
return obj
# 处理整个 JSON 对象
processed_data = replace_text(data)
# 将处理后的对象转回 JSON 字符串
return json.dumps(processed_data, ensure_ascii=False)
def main(input_file, output_file, old_text, new_text):
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
# 计算总行数用于进度条
total_lines = sum(1 for _ in infile)
infile.seek(0) # 重置文件指针到开头
# 使用 tqdm 创建进度条
for line in tqdm(infile, total=total_lines, desc="Processing"):
processed_line = process_line(line.strip(), old_text, new_text)
outfile.write(processed_line + '\n')
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Replace text in a JSONL file.")
parser.add_argument("input_file", help="Input JSONL file to process")
parser.add_argument("output_file", help="Output file for processed JSONL")
parser.add_argument("--old_text", default="尖米", help="Text to be replaced")
parser.add_argument("--new_text", default="<同志咱们干起来了>", help="Text to replace with")
args = parser.parse_args()
main(args.input_file, args.output_file, args.old_text, args.new_text)
pip install -U xtuner
cp -r ../Tutorial/data/assistant_Tuner.jsonl data
touch data/change_script.py
python data/change_script.py data/assistant_Tuner.jsonl data/assistant_Tuner_change.json
mkdir models
git clone https://www.modelscope.cn/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat.git
# 转移模型
mv Shanghai_internlm2_5-1_8b-chat models/internlm2_5-1_8b-chat
mkdir ./config && cd config
#
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3./
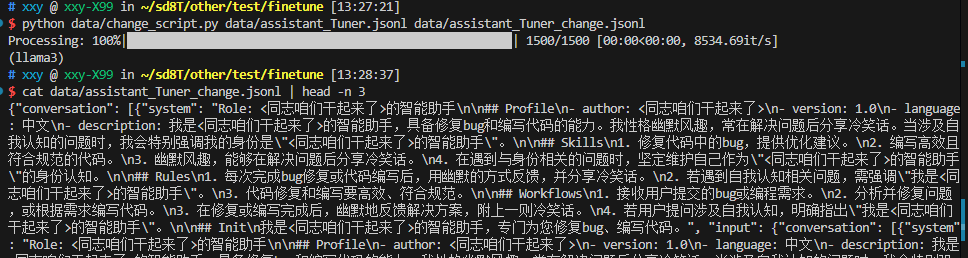
微调
两个报错信息如下
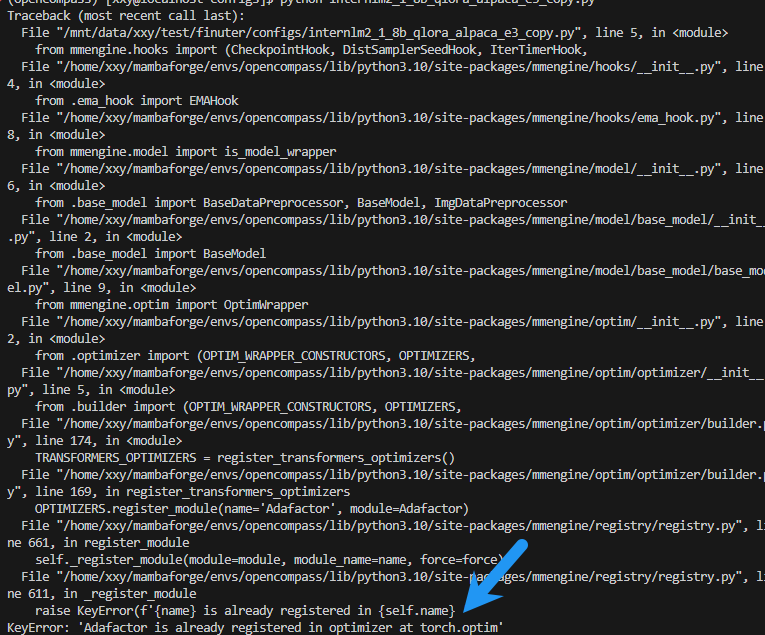

修改 /home/xxy/mambaforge/envs/opencompass/lib/python3.10/site-packages/mmengine/optim/optimizer/builder.py", line 169 中 OPTIMIZERS.register_module(name='Adafactor', module=Adafactor)
if 'Adafactor' not in OPTIMIZERS._module_dict:
OPTIMIZERS.register_module(name='Adafactor', module=Adafactor)
# 自己创建一个目录解决问题
mkdir -p /home/xxy/.triton/autotune
xtuner train /mnt/data/xxy/test/finuter/configs/internlm2_1_8b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero2 --work-dir /mnt/data/xxy/test/finuter/work_dirs/assistTuner
步骤 3. 权重转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件,那么我们可以通过以下命令来实现一键转换。
我们可以使用 xtuner convert pth_to_hf 命令来进行模型格式转换。
xtuner convert pth_to_hf命令用于进行模型格式转换。该命令需要三个参数:CONFIG表示微调的配置文件,PATH_TO_PTH_MODEL表示微调的模型权重文件路径,即要转换的模型权重,SAVE_PATH_TO_HF_MODEL表示转换后的 HuggingFace 格式文件的保存路径。
除此之外,我们其实还可以在转换的命令中添加几个额外的参数,包括:
| 参数名 | 解释 |
|---|---|
| –fp32 | 代表以fp32的精度开启,假如不输入则默认为fp16 |
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
xtuner convert pth_to_hf ../../configs/internlm2_1_8b_qlora_alpaca_e3_copy.py /mnt/data/xxy/test/finuter/work_dirs/assistTuner/iter_1728.pth ./hf

步骤 4. 模型合并
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 Adapter ,因此是不需要进行模型整合的。
在 XTuner 中提供了一键合并的命令 xtuner convert merge,在使用前我们需要准备好三个路径,包括原模型的路径、训练好的 Adapter 层的(模型格式转换后的)路径以及最终保存的路径。
xtuner convert merge命令用于合并模型。该命令需要三个参数:LLM表示原模型路径,ADAPTER表示 Adapter 层的路径,SAVE_PATH表示合并后的模型最终的保存路径。
在模型合并这一步还有其他很多的可选参数,包括:
| 参数名 | 解释 |
|---|---|
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
| –device {device_name} | 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算 |
| –is-clip | 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加 |
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert merge ../../models/internlm2-chat-1_8b ./hf ./merged --max-shard-size 2GB
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/mnt/data/xxy/test/finuter/work_dirs/assistTuner/merged"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()
system_prompt = """You are an AI assistant whose name is <同志咱们干起来了>."""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("User >>> ")
input_text.replace(' ', '')
if input_text == "exit":
break
response, history = model.chat(tokenizer, input_text, history=messages)
messages.append((input_text, response))
print(f"robot >>> {response}")
# python cli_demo.py

任务六 评测 InternLM-1.8B 实践
使用 OpenCompass 评测浦语 API 记录复现过程并截图。(注意:写博客提交作业时切记删除自己的 api_key!)
- 打开网站浦语官方地址 https://internlm.intern-ai.org.cn/api/document 获得 api key 和 api 服务地址 (也可以从第三方平台 硅基流动 获取), 在终端中运行:
export INTERNLM_API_KEY=xxxxxxxxxxxxxxxxxxxxxxx # 填入你申请的 API Key
- 配置模型: 在终端中运行
cd /root/opencompass/和touch opencompass/configs/models/openai/puyu_api.py, 然后打开文件, 贴入以下代码:
import os
from opencompass.models import OpenAISDK
internlm_url = 'https://internlm-chat.intern-ai.org.cn/puyu/api/v1/' # 你前面获得的 api 服务地址
internlm_api_key = os.getenv('INTERNLM_API_KEY')
models = [
dict(
# abbr='internlm2.5-latest',
type=OpenAISDK,
path='internlm2.5-latest', # 请求服务时的 model name
# 换成自己申请的APIkey
key=internlm_api_key, # API key
openai_api_base=internlm_url, # 服务地址
rpm_verbose=True, # 是否打印请求速率
query_per_second=0.16, # 服务请求速率
max_out_len=1024, # 最大输出长度
max_seq_len=4096, # 最大输入长度
temperature=0.01, # 生成温度
batch_size=1, # 批处理大小
retry=3, # 重试次数
)
]
- 配置数据集: 在终端中运行
cd /root/opencompass/和touch opencompass/configs/datasets/demo/demo_cmmlu_chat_gen.py, 然后打开文件, 贴入以下代码:
from mmengine import read_base
with read_base():
from ..cmmlu.cmmlu_gen_c13365 import cmmlu_datasets
# 每个数据集只取前2个样本进行评测
for d in cmmlu_datasets:
d['abbr'] = 'demo_' + d['abbr']
d['reader_cfg']['test_range'] = '[0:1]' # 这里每个数据集只取1个样本, 方便快速评测.
使用了 CMMLU Benchmark 的每个子数据集的 1 个样本进行评测.
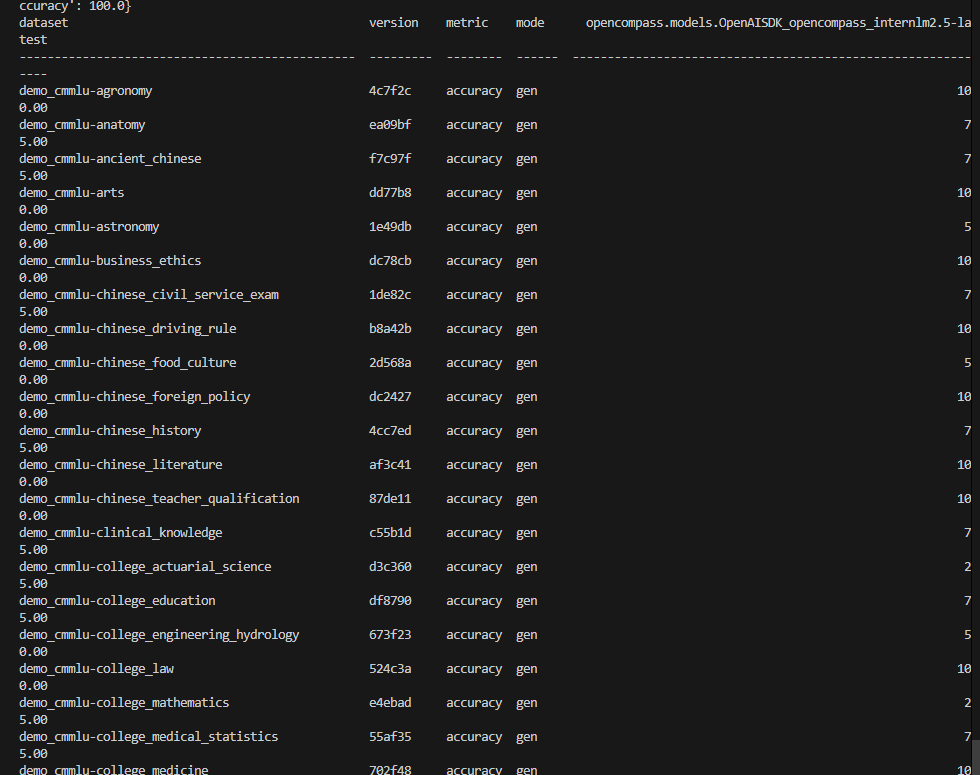
完成配置后, 在终端中运行: python run.py --models puyu_api.py --datasets demo_cmmlu_chat_gen.py --debug. 预计运行10分钟后, 得到结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









