







6月29日,FATE开源社区第3期【大咖实战分享】圆满落幕。本次活动,社区邀请到亚信科技(中国)有限公司的刘志勇老师,为大家分享运营商与医疗机构联邦建模案例。
接下来,让我们一起回顾经典问答环节,希望能帮助大家解决在FATE实践中遇到的问题。
问答环节
● Q1:
后面做推理的时候,是使用FATE server吧?这个组件是两个机器都部署的吗?FATE server绑定模型之后,它会有一个服务,服务是起在哪里?具体查询的时候,例如他现在医疗机构需要类似于一个ID,假如他接受了一个查询ID的请求,运营商会帮你们进行交互的接口在哪里,或者说是怎么进行交互的,怎么把数据提供给他?
● A1:
对,这个FATE server是在医疗机构和运营商是都做了的。因为这边医疗机构是guest方,所以数据使用方是医疗机构,运营商只是一个数据提供方,所以说推理服务是在医疗机构这边发起的。
就是利用的FATE server进行交互,比如医疗机构发起推理请求的时候,在调用接口时会传一些参数,包括 ID以及医疗机构这边的一些数据特征,就是建模时候的医疗机构这边数据特征,然后它会把ID以及这边的结果传到运营商(host)这边。host方需要根据现场的实际情况开发adapter,这个是在部署FATE serving的时候就要做好的,adapter会根据guest方传来的ID去数据库或者文件获取建模的时候那些特征,查到特征之后,host侧会结合本方数据特征以及guest侧的部分结果得到最终的结果返回给医疗机构这边。这样一个完整的推理过程就结束了。
● Q2:
三方的合作模式是怎样的?亚信是什么角色,是居间协调节点?
● A2:
我们这边做的是只有运营商和医疗机构两方的,然后arbiter是放到云端的,通常为了数据隐私安全,arbiter是要放到一个具有公信力的地方的。亚信负责的内容是搭建整个流程,包括双方以及arbiter的FATE框架的构建,基于FATE的联邦学习建模及调优等等,相当于运营商和医疗机构提出需求,并提供硬件资源与数据,剩下的都是亚信来实现的。
● Q3:
请问一下老师,推理机器和训练机器可以分开部署吗?可以不通吗?
● A3:
是可以分开部署的,现场部署训练和推理就是在不同的机器上的,但是要能通,因为在训练完之后,模型是储存在训练机器上的,要进行推理的话需要将储存在训练机器上的模型加载和绑定到推理机器上,如果不通的话,是没法把模型放到推理机器上的,就启动不了推理服务了。
● Q4:
请问老师模型结构是guest设计,只有guest知道模型结构吗?
● A4:
这个模型结构的话,FATE本身提供了一个FATE board组件,如果双方都部署了FATE board的话,运营商侧也就是说host方打开 FATE board也是可以看到整个模型的结构的,比如说我用的是secure boost,那么我在医疗机构这边,FATE board页面上是可以看到一个树状的一个结构的,而在运营商那边也是可以看到这样一个结构的,只不过它有些参数是看不到的。双方都是可以看到完整的模型结构的,但是和对方数据相关的参数是不会显示出来的。
● Q5:
请问一下,模型预测的是什么,标签是什么?医疗机构和运营商这些数据的结合的应用场景是什么,解决什么问题,怎么利用联邦建模的结果向用户推荐什么?
● A5:
你可以简单的理解为,预测的是某个用户会不会去办理业务,就是他会不会去点击页面的推荐业务,标签就是很简单的会或者不会。因为医疗机构它本身是有一些用户的特征的,然后运营商机构包含的用户信息也是非常丰富的,包括你的个人信息上网记录等等,这些对了解你在医疗方面想知道的东西是很有帮助的。场景之一比如说合理利用双方的数据包含的信息去构建一个分类模型,标签是用户是否点击了某一业务,那么后续对于别的用户就可以根据模型的推理结果判断是否给这个用户做这类业务相关的推荐,以达到精准营销的目的。
以下为本次大咖分享的部分内容介绍,添加小助手(FATEZS001)可获取详细资料:


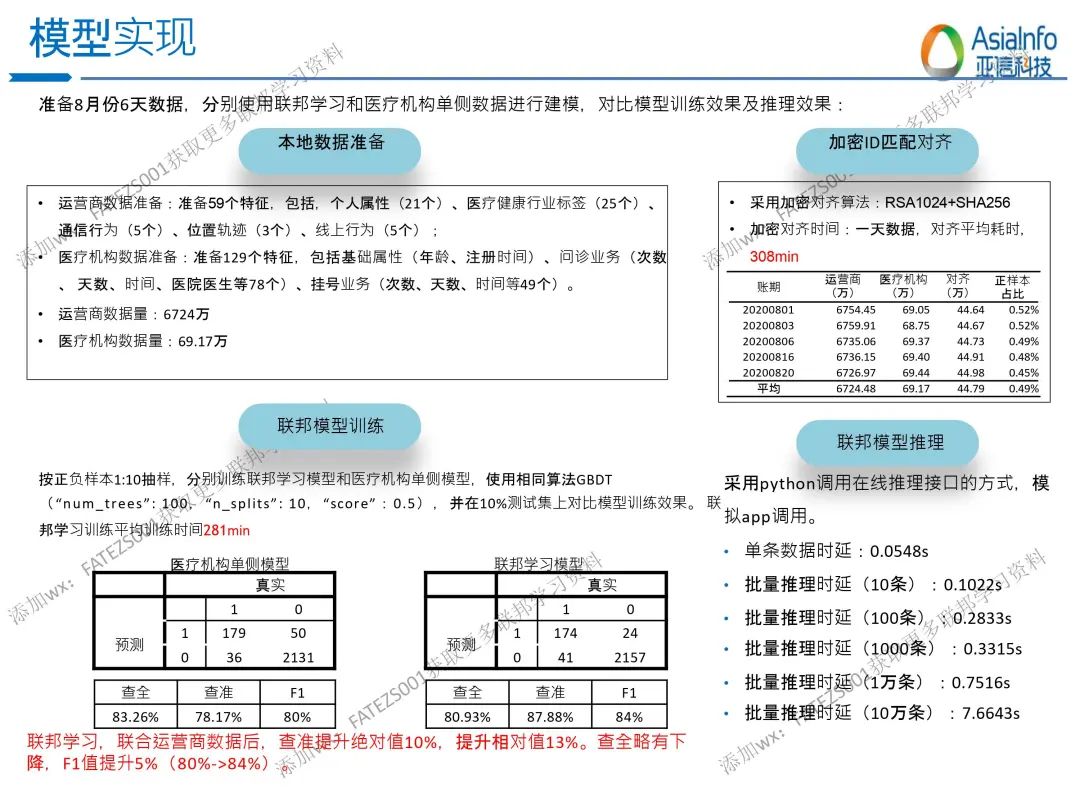
以上就是本次分享会互动环节内容,
想观看本期视频。
想报名参与下一期的活动?
或者对以上内容还有疑问,
联系小助手获取协助。


















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









