







 本文基于Kaggle数据集,通过预处理15W行中的5000个样本,预测明天是否会下雨。内容包括数据分拣、特征工程,涉及异常值处理、日期特征提取、分类型变量编码、连续变量处理等步骤,以SVC作为模型进行预测。
本文基于Kaggle数据集,通过预处理15W行中的5000个样本,预测明天是否会下雨。内容包括数据分拣、特征工程,涉及异常值处理、日期特征提取、分类型变量编码、连续变量处理等步骤,以SVC作为模型进行预测。
概述:
此数据来源于Kaggle上的一份数据,我们的目的是在这个数据集上来预测明天是否会下雨。在这个15W行数据的数据集上,随机抽样5000个样本来为大家演示一些数据预处理和特征工程的思路。欢迎大家交流和指正:)
数据预处理
1.导库导数据,探索特征
- 导入需要的库
// An highlighted block
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
- 导入数据,探索数据
// An highlighted block
df = pd.read_csv('weather.csv',index_col=0)
df.shape # 查询数据形状 查看数据是几行几列 -(142193, 22)
因为数据比较大,有142193行,所以我们抽取5000条样本进行分析建模
// An highlighted block
weather = df.sample(n=5000,random_state=0)
首先看一下数据情况:
// An highlighted block
df.head() #查看数据的前几行

由此可以看出由于抽样的原因, 数据的索引需要我们重新设置
// An highlighted block
weather.index = range(weather.shape[0]) #重置索引
weather.head()

// An highlighted block
weather.columns #提取所有的特征名

以下是所有特征的含义,最后一个变量RainTomorrow 就是我们的目标变量,我们的标签:明天下雨了吗?
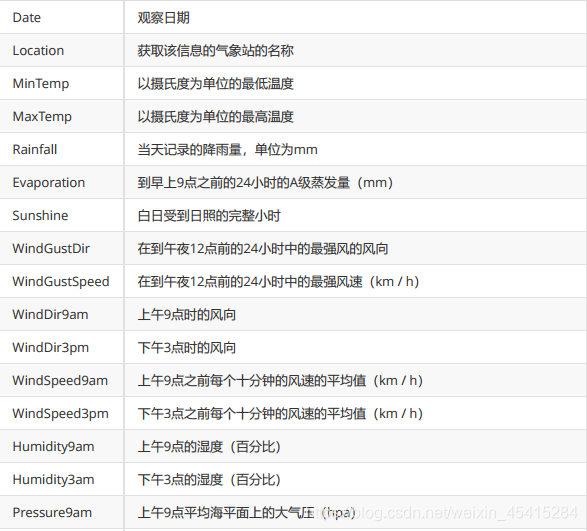
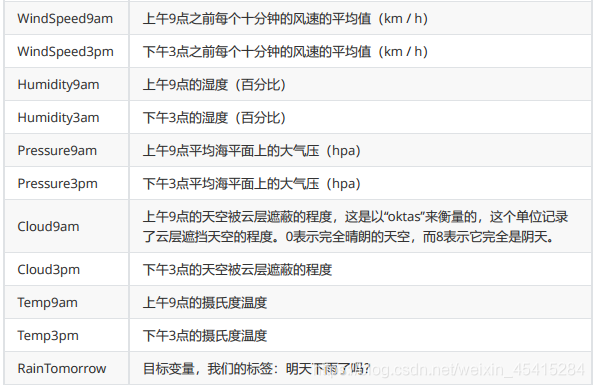
分别提取特征矩阵和标签:
// An highlighted block
X=weather.iloc[:,:-1]
Y=weather.iloc[:,-1]
// An highlighted block
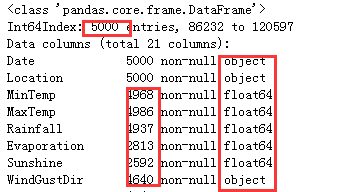
X.info()
// An highlighted block
#查看标签类别
np.unique(Y)
#查看缺失值的比例(各个特征的缺失值比例)
X.isnull().mean()
查看特征矩阵整体情况:可以分析得出此特征矩阵里存在缺失值, 粗略观察可以发现,这个特征矩阵由一部分分类变量和一部分连续变量组成,其中云层遮蔽程度虽然是以数字表示,但是本质却是分类变量。大多数特征都是采集的自然数据,比如蒸发量,日照时间,湿度等等,而少部分特征是人为构成的。还有一些是单纯表示样本信息的变量,比如采集信息的地点,以及采集的时间。
标签是包含’No’和’Yes’的二分类问题。
2. 分数据集,探索标签
- 切分训练集和测试集
在现实中,我们会先分训练集和测试集,再开始进行数据预处理。这是由于,测试集在现实中往往是不可获得的,或者被假设为是不可获得的,我们不希望我们建模的任何过程受到测试集数据的影响,否
则的话,就相当于提前告诉了模型一部分预测的答案。在这里,为了让案例尽量接近真实的样貌,所以采取了现实中所使用的这种方式:先分训练集和测试集,再一步步进行预处理。这样导致的结果是,我
们对训练集执行的所有操作,都必须对测试集执行一次,工作量是翻倍的。
// An highlighted block
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
Xtrain.shape #训练集特征数据形状
Xtest.shape #测试集特征数据形状
新切分数据后,索引需要重新设置:
// An highlighted block
#恢复索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
- 查看是否有样本不均衡问题
通过查看标签每一类的数量和,来比较一下样本是否不均衡
// An highlighted block
Ytrain.value_counts()
Ytest. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









