







 本文利用Kaggle上的澳大利亚气象数据,通过SVM进行明日降雨预测。数据预处理包括分类变量处理、异常值和缺失值处理,最终模型评估显示线性核函数的准确性较高。
本文利用Kaggle上的澳大利亚气象数据,通过SVM进行明日降雨预测。数据预处理包括分类变量处理、异常值和缺失值处理,最终模型评估显示线性核函数的准确性较高。
案例分析流程
一、获取数据
本案例中所用的数据集为Kaggle提供的澳大利亚气象局十年的气象数据,共142193条数据。本文采用SVM、随机森林进行预测,仅供学习交流。
二、解读数据
数据大小:12.9M,142193条数据;
数据格式:csv
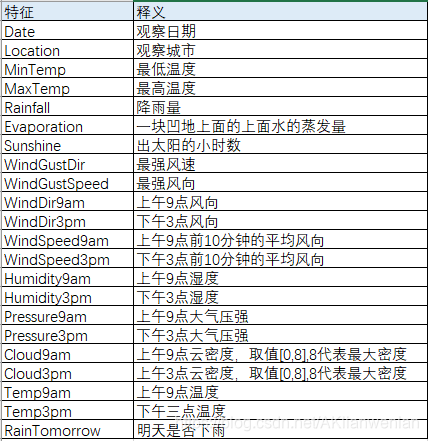
数据特征:总共有23个特征,下图为各特征的中文释义。其中RainTomorrow为目标变量Y,Cloud9am和Cloud3pm是有9个取值范围的,这样的特征有程度的数据,建议用分类型变量进行分析,不建议以连续型变量进行哑变量转换。
三、数据探索
1.导入相关包
# 导入基本包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #画图包
%matplotlib inline
import seaborn as sns #画图包
plt.style.use('seaborn')
import warnings
warnings.filterwarnings('ignore') #警告过滤器,跳过警告
2.导入数据和查看数据
# 导入数据
weather = pd.read_csv('weather.csv',index_col=0) #读取csv文件'weather.csv'
pd.set_option('max_columns',100) #显示所有行
weather.head() #查看数据前5行
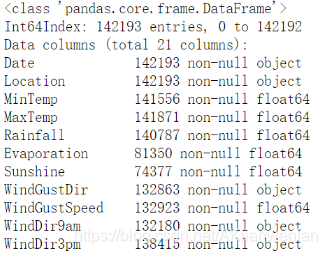
weather.info() #查看数据长相,有多少个特征,有多少条数据,特征的数据类型
查看目标变量的分布
weather.RainTomorrow.value_counts()
3.随机抽样
我们可以先随机抽取10000条数据进行分析建模
# 随机抽取,random_state是随机数种子,为0代表不能重复,1代表可以重复
df = weather.sample(n=10000,random_state=0)
df.index = range(df.shape[0]) #抽取的数据需要重建索引
4.探索变量
df.info()
df.describe().T #观察四分位数,再通过T转置一下,可以比较完整看到各特征的数据分布情况
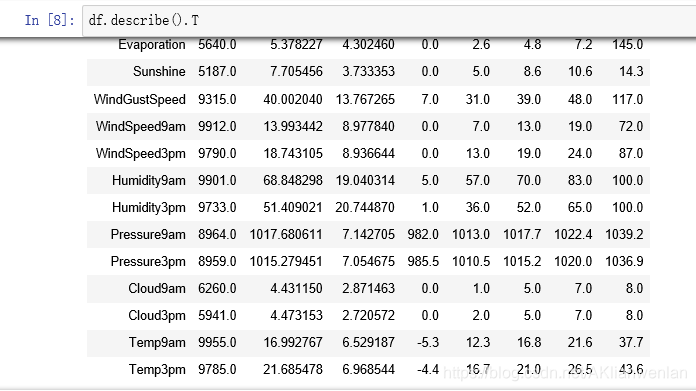
从上述两个数据基本情况可以看出,Cloud9am和Cloud3pm虽然为浮点型数据,但数据取值只有8个,可能为分类型变量。我们来查看一下是否为分类变量?
df.Cloud9am.unique()
df.Cioud3am.unique()

通过查看唯一值,确定Cloud9am和Cloud3pm为分类变量。
5.将样本特征和标签分开
X = df.iloc[:,:-1] #X取所有行中的第一列到倒数第二列
Y = df.iloc[:,-1] #Y取所有行中的最后一列
6.切分训练集和测试集
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size = 0.3,random_state = 100)
print(Xtrain.</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2591
2591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









