






目录
Pytorch概述
来自百度:
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络
https://pytorch.org/
官网需要科学才能快速访问
PyTorch具有以下功能:
-
张量操作:PyTorch支持多种张量操作,如加法、减法、乘法、除法、矩阵乘法等。张量是PyTorch的基本数据结构,类似于NumPy中的数组。PyTorch的张量支持自动求导功能,可以方便地计算梯度。
-
动态计算图:PyTorch使用动态计算图。当我们构建计算图时,我们可以使用Python的控制流结构,如if语句、for循环等。这使得我们可以方便地编写动态模型,比如变长序列模型和递归模型。
-
静态计算图:此外,PyTorch还支持静态计算图,称为TorchScript。TorchScript是一个中间表示,可以将模型保存为二进制文件或导出为C++代码。这使得我们可以在实际生产环境中使用PyTorch模型。
-
模型定义:PyTorch提供了多种方式定义模型。我们可以使用Python类来定义模型,使用多个函数来构建模型,或使用PyTorch的逆向自动微分函数来构建模型。
-
数据加载:PyTorch提供了多种数据加载方式,如内置数据集、自定义数据集、数据转换操作和数据集迭代器等。此外,PyTorch还可以从常见的数据格式(如CSV、JSON和HDF5)中加载数据。
-
神经网络层:PyTorch提供了多种神经网络层,包括卷积层、池化层、全连接层、循环神经网络层、门控循环神经网络层、变换器层等。
-
优化器:PyTorch提供了多种优化器,如随机梯度下降(SGD)、Adam、Adagrad等。这些优化器可以帮助我们自动优化模型参数,降低训练误差。
-
分布式训练:PyTorch支持分布式训练,在多台机器上训练深度学习模型。使用分布式训练可以大大缩短训练时间,提高模型训练效率。
作用的领域
PyTorch主要用于深度学习和神经网络的研究和开发。它可以应用于以下领域:
-
自然语言处理:PyTorch在自然语言处理(NLP)领域广泛应用,包括文本分类、语言模型、机器翻译等领域。PyTorch提供了多种预训练模型,如BERT、GPT等,并包含多种NLP技术,如词向量表示、注意力机制和神经机器翻译等。
-
计算机视觉:PyTorch在计算机视觉(CV)领域被广泛应用,包括物体检测、图像分类、分割等领域。使用PyTorch可以轻松构建深度神经网络模型,并使用预训练卷积神经网络(CNN)模型,如AlexNet、ResNet等。
-
声音处理:PyTorch可以在语音识别、语音合成、音乐生成等领域广泛应用。PyTorch提供了多种预训练语音处理模型,如Wav2Vec、Deepspeech等。
-
强化学习:PyTorch在强化学习领域被广泛应用,如模拟器和机器人控制。
-
智能对话:PyTorch可以帮助构建智能对话系统,如聊天机器人、客服聊天系统等。PyTorch提供了多种自然语言处理技术,如词向量表示、实体识别等,以提高对话系统的智能水平。
其他框架
TensorFlow是Google Brain基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理,于2015年11月9日在Apache 2.0开源许可证下发布,并于2017年12月份预发布动态图机制Eager Execution。
Tensorflow1.0:
静态图
Tensorflow2.0:
动态图
Keras是一个用Python编写的开源神经网络库,它能够在TensorFlow,CNTK,Theano或MXNet上运行。Keras本身并不是一个框架,而是一个位于其他深度学习框架之上的高级API。
MXNet是DMLC(Distributed Machine Learning Community)开发的一款开源的、轻量级、可移植的、灵活的深度学习库,它让用户可以混合使用符号编程模式和指令式编程模式来最大化效率和灵活性,目前已经是AWS官方推荐的深度学习框架。MXNet的很多作者都是中国人,其最大的贡献组织为百度。
PyTorch是Facebook于2017年1月18日发布的python端的开源的深度学习库,基于Torch。支持动态计算图,提供很好的灵活性。在今年(2018年)五月份的开发者大会上,Facebook宣布实现PyTorch与Caffe2无缝结合的PyTorch1.0版本将马上到来。
最大优势是建立的神经网络是动态的, 对比静态的 Tensorflow, 它能更有效地处理一些问题, 比如说 RNN 变化时间长度的输出。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。
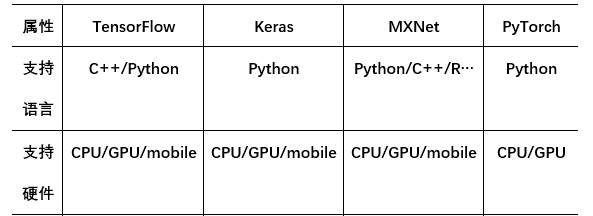
注: pytorch1.3已支持moblie
其他相关主题
Onnx
ONNX(Open Neural Network Exchange),开放神经网络交换,是一种模型IR,用于在各种深度学习训练和推理框架转换的一个中间表示格式。在实际业务中,可以使用Pytorch或者TensorFlow训练模型,导出成ONNX格式,然后在转换成目标设备上支撑的模型格式,比如TensorRT Engine、NCNN、MNN等格式。ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性,开放性较强。
Braches:
Opencv
OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。
OpenCV用C++语言编写,它具有C ++,Python,Java和MATLAB接口, 如今也提供对于C#、Ch、Ruby,GO的支持
Pycharm
PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
Anaconda
Anaconda是用于科学计算(数据科学、机器学习应用、大规模数据处理、预测分析等)的Python和R编程语言的发行版,旨在简化包管理和部署。该发行版包括适用于Windows、Linux和macOS的数据科学包。它由Anaconda, Inc.开发和维护
Anaconda中的包版本由包管理系统conda管理。[9]这个包管理器是作为一个单独的开源包分离出来的,因为它最终对自己和Python以外的东西都很有用。[10]Anaconda还有一个名为Minicon da的小型引导版本,它只包括conda、Python、它们所依赖的包以及少量其他包。[11]
环境搭建
建议利用Anaconda第三方工具来部署pytorch环境;懂C#的朋友可以理解成Nuget管理平台(Anaconda比Nuget更强大,可以做版本环境隔离),后期所有用到的包、API,都可以用Anaconda来获取与安装部署;
唯一对比Nuget的缺点就是,Anaconda大多数使用方式与教程都是CLI方式。
Anaconda安装
官网下载https://www.anaconda.com/download#downloads
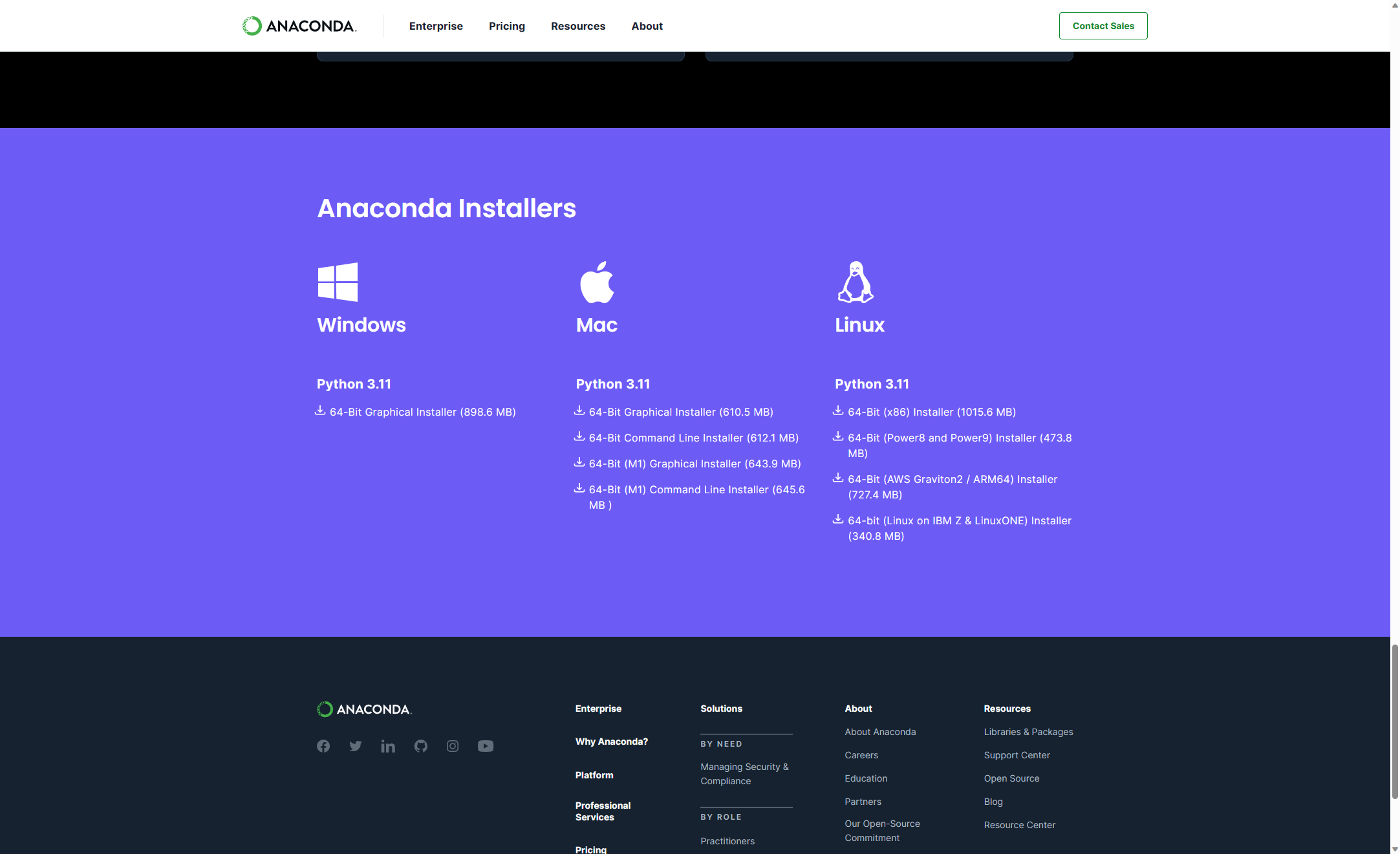
剩下的安装步骤傻瓜式,记得勾选上 “设置conda可执行文件的环境变量” 的选项;提示选项应该是英文,翻译过来就是了
Pytorch安装
网站https://pytorch.org/get-started/locally/
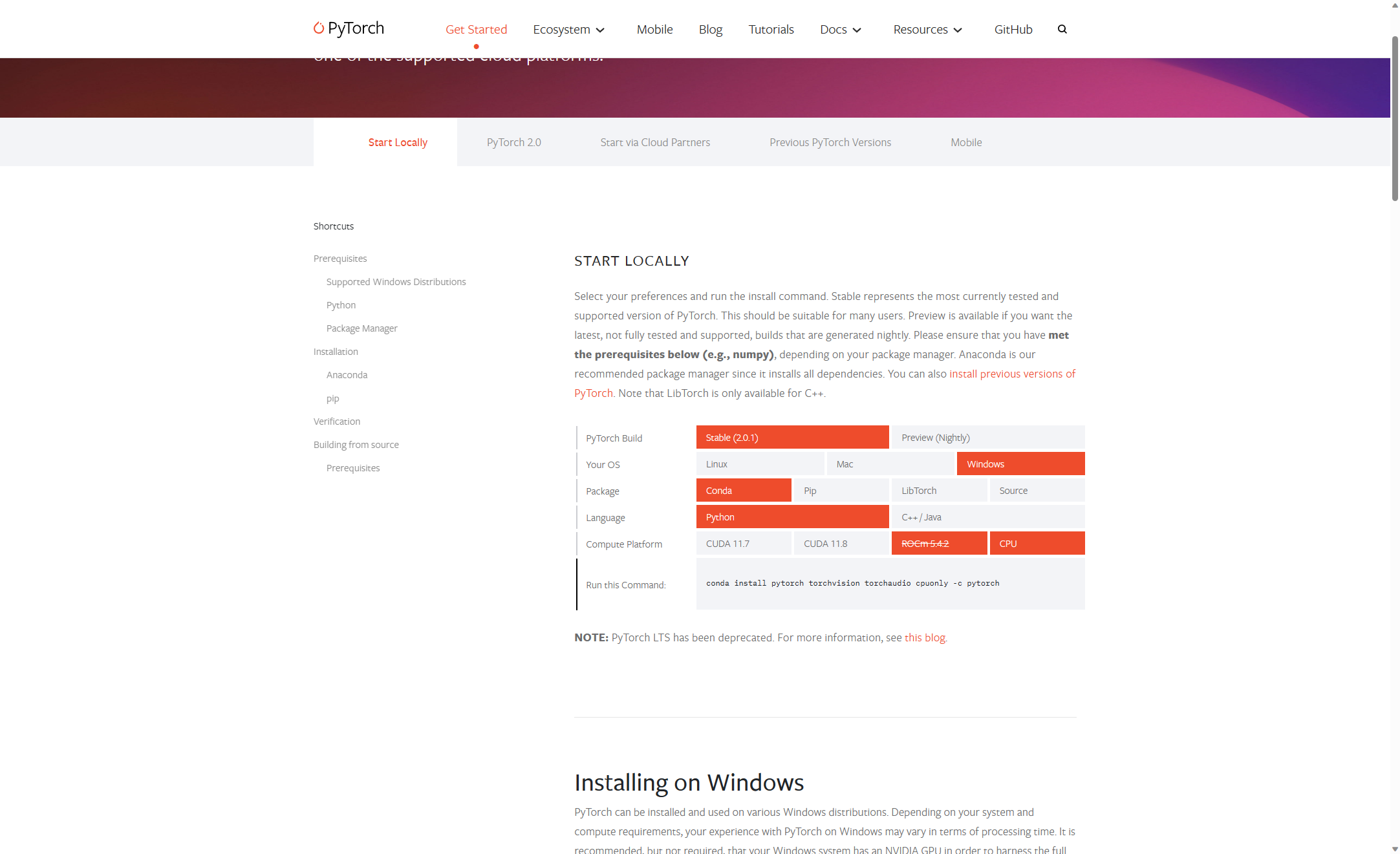
如果想要预览版本选择Preview
如果想要老版本https://pytorch.org/get-started/previous-versions/
conda常用指令合集
常用安装包指令:
python.exe -m pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple
步骤
- 创建Conda虚拟环境,用来版本隔离
conda create -n env_name python=3.8
如果报错conda未识别之类的,检查环境变量;或者指定conda.exe路径来执行这条命令
- 安装完成后,切换到对应的虚拟环境来安装pytorch: conda activate 环境名
- 复制上面pytorch的命令,执行,例如
GPU版本,cuda版本自行对应
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
GPU版本安装完成后,可以在python中执行
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')查看device的值
CPU版本
conda install pytorch torchvision torchaudio cpuonly -c pytorch
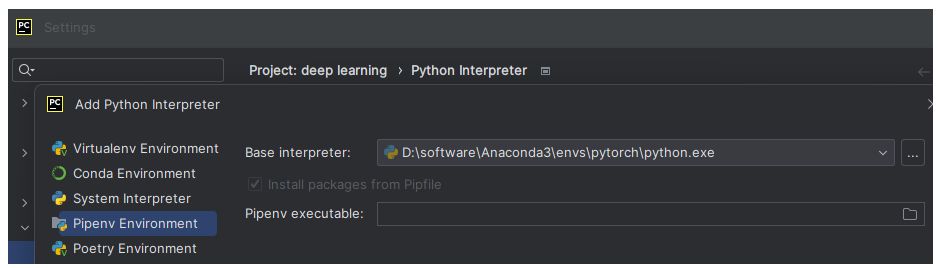
- 随便进入pycharm新建一个项目,设置编译器,如下图
interpreter设置为anaconda安装位置-envs-pytorch的python.exe,如果pipeenv environment不行,换poetry environment
poetry
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Guq0ULL-1692544604227)(pytorch.assets/image-20230720100224819.png)]](https://i-blog.csdnimg.cn/blog_migrate/5ac6df42d908c3ce18acb5ef4bb1ff12.png)
5. import torch,右键运行查看是否成功
分类环境搭建
1.创建虚拟环境
建议创建虚拟环境,你也可以公用,但是不提倡,因为有些场景用到的库版本不一样,以及全部放在一起的话,环境就会非常大,python本身就是一个体积小巧的脚本语言
名字随便取,我这里叫cls_py38
conda create -n cls_py38 python=3.8
2.安装需要的包
用conda activate切换到虚拟环境cls_py38
执行安装,-c pytorch是指定包源
conda install pytorch torchvision torchaudio cpuonly -c pytorch
3.写一个经典VGG
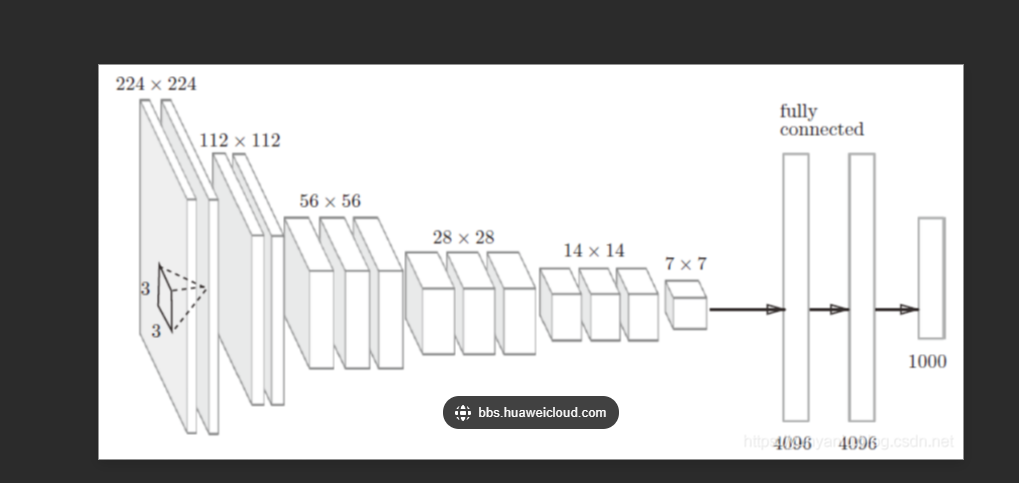
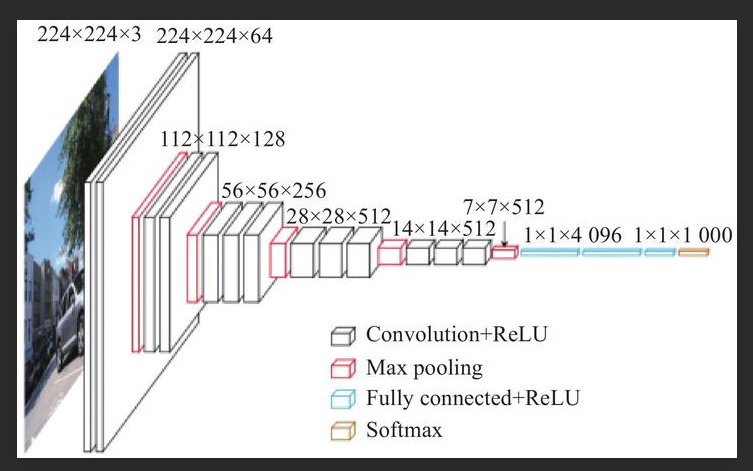
模型步骤,不是python代码,不要复制
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(11): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): ReLU(inplace=True)
(13): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(14): ReLU(inplace=True)
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(16): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(19): ReLU(inplace=True)
(20): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
模型解析
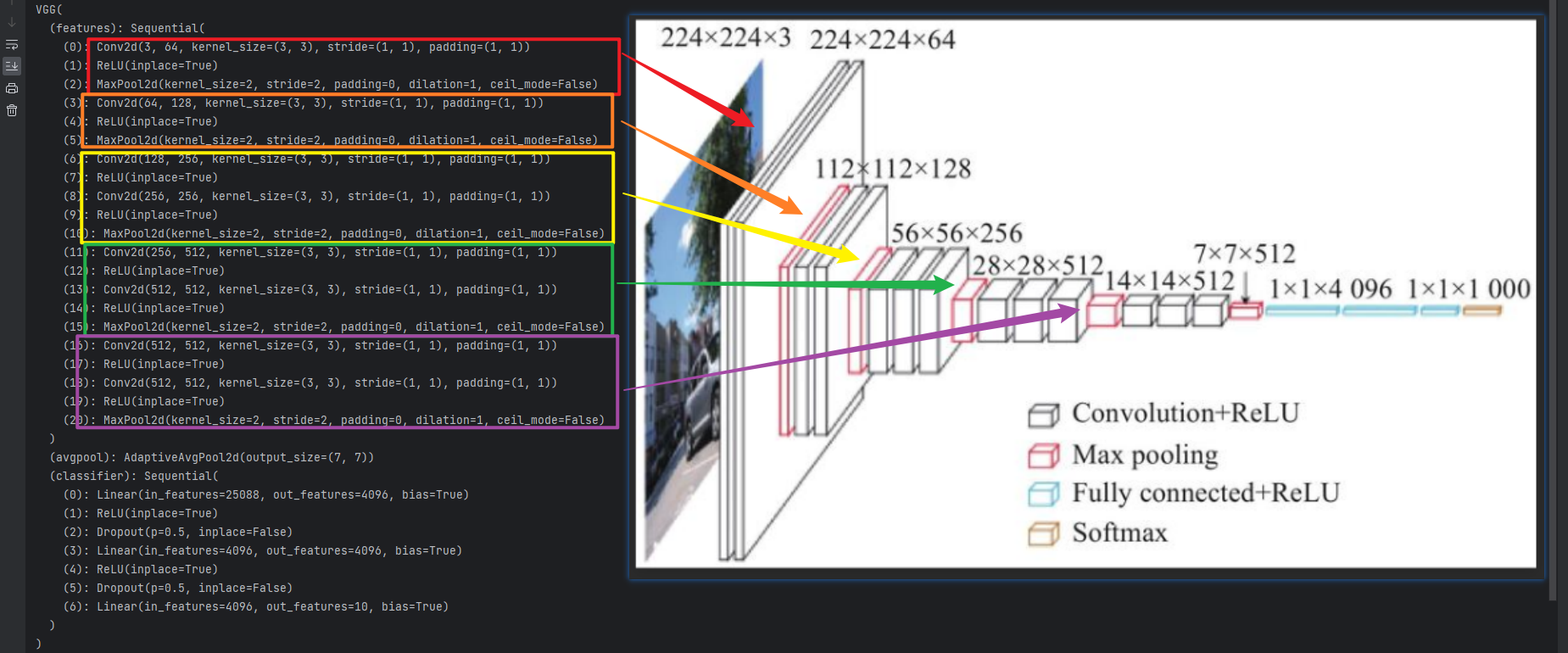
这才是模型代码,可以复制
class VGG(nn.Module):
def __init__(self,in_channels=3,out_features=10):
super(VGG, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
self.avgpool = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(7, 7)))
self.classifier = nn.Sequential(
nn.Linear(in_features=25088, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=out_features, bias=True))
def forward(self,x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
下一篇写网络中的各个算法详解以及训练推理应用,敬请期待

















 6298
6298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









