




 本文深入探讨了逻辑回归模型及其背后的数学原理,通过极大似然估计推导出了交叉熵代价函数,揭示了逻辑回归如何通过Sigmoid函数预测样本属于正例的概率,并通过最大似然估计构建了逻辑回归的代价函数。
本文深入探讨了逻辑回归模型及其背后的数学原理,通过极大似然估计推导出了交叉熵代价函数,揭示了逻辑回归如何通过Sigmoid函数预测样本属于正例的概率,并通过最大似然估计构建了逻辑回归的代价函数。
一、极大似然估计
首先得知道什么是极大似然估计
吴恩达老师在公开课直接给出交叉熵代价函数并简单解释了交叉熵代价函数作为逻辑回归代价函数的合理性,在周志华老师的《机器学习》教材中,从极大似然估计角度详细证明了交叉熵代价函数的推导。
二、逻辑回归模型
周志华老师从模型开始详细的介绍了逻辑回归的由来与其实质。

加入Sigmoid函数后得出
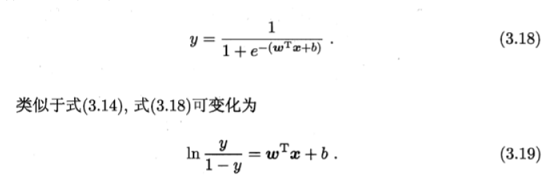
而在经过进一步的计算y=0和y=1时的概率

最终某样本属于正例的概率可以表示为
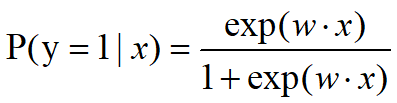
某样本属于负例的概率可以表示为
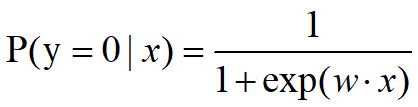
将w·x视为Sigmoid函数的输入,其中w是模型参数,x是特征向量,将Sigmoid函数的输出视为预测为正例的概率。
那模型将样本预测为正例的概率为sigmod(w·x);将样本预测为负例概率为1- sigmod(w·x)。
三、极大化目标
极大化 => 将所有正例预测为正例的概率的累乘 * 将所有负例预测为负例的概率的累乘
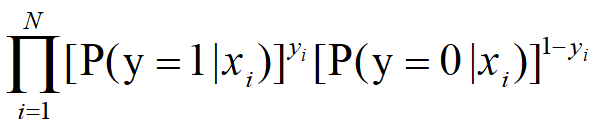
而在计算机中通常求最小化问题,对上述公式运用对数法则对数似然并转换为求解最小化问题得出交叉熵代价函数:
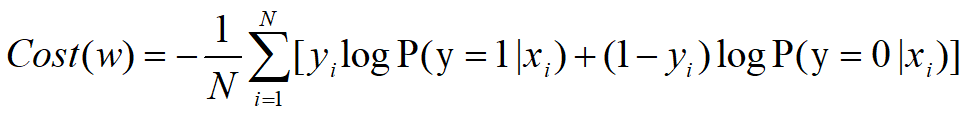
四、使用极大似然估计构建逻辑回归代价函数另一种写法

五、最大似然估计和最小代价函数两种方式推导逻辑回归
大佬链接:
最大似然估计和最小代价函数两种方式推导逻辑回归

















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









