







 本文介绍了在机器学习中特征缩放的重要性及其两种常见方法:归一化特征缩放和标准化特征缩放。通过这两种方法,可以有效提升模型收敛速度并提高模型精度。
本文介绍了在机器学习中特征缩放的重要性及其两种常见方法:归一化特征缩放和标准化特征缩放。通过这两种方法,可以有效提升模型收敛速度并提高模型精度。
一、为什么特征缩放
在面对多维特征问题的时,有时特征数据数据值相差过大,如在运用多变量线性回归预测房价模型中,房屋面积和卧室个数这俩个特征之间数值相差大,而要保证这些特征都具有相近的尺度,就要进行特征缩放,这能帮助梯度下降算法更快地收敛。如图:
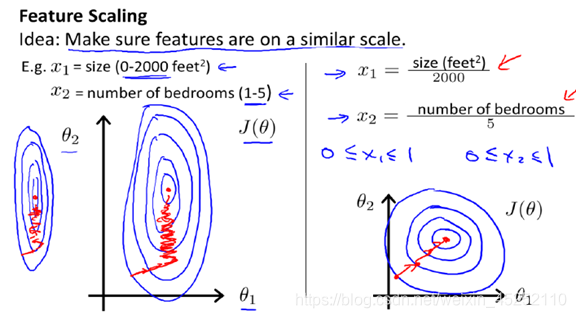
直接求解的缺点:
1、当x1 特征对应权重会比x2 对应的权重小很多,降低模型可解释性
2、梯度下降时,最终解被某个特征所主导,会影响模型精度与收敛速度
3、正则化时会不平等看待特征的重要程度(尚未标准化就进行L1/L2正则化是错误的)
特征缩放的好处:
1、提升模型收敛速度
2、提高模型精度
二、特征缩放常用的方法
特征缩放思想: 确保这些特征都处在一个相近的范围。
下面介绍俩种常用的特征缩放方法。
1、归一化特征缩放(0-1缩放)
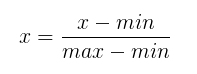
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用这种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
python代码实现:
#数据预处理
def preprocess(X,y):
#进行0-1缩放特征
X_min = np.min(X)
X_max = np.max(X)
X = (X-X_min)/(X_max-X_min)
#数据初始化
X = np.c_[np.ones(len(X)),X]
y = np.c_[y]
return X,y
X,y = preprocess(X,y)
2、标准化特征缩放
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
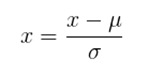
其中μ是平均值,σ是标准差
python代码实现:
def preProcess(x,y):
#标准化特征缩放
x -= np.mean(x,axis=0)
x /= np.std(x,axis=0,ddof=1)
#数据初始化
x = np.c_[np.ones(len(x)),x]
y = np.c_[y]
return x,y
X,y = preprocess(X,y)

















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









