







在这里分享一下点云分类模型、部件分割模型以及语义分割模型的预测脚本,均根据GitHub - yanx27/Pointnet_Pointnet2_pytorch: PointNet and PointNet++ implemented by pytorch (pure python) and on ModelNet, ShapeNet and S3DIS. https://github.com/yanx27/Pointnet_Pointnet2_pytorch中的test_classification.py、test_partseg.py和test_semseg.py改写的,pointnet++训练可以参考我的这篇博客。
https://github.com/yanx27/Pointnet_Pointnet2_pytorch中的test_classification.py、test_partseg.py和test_semseg.py改写的,pointnet++训练可以参考我的这篇博客。
1.classifacation
主要了解网络的输入和输出就行了,输入是(batch_size,channel,npoints),分别表示批处理大小(这里都是设置为1,即一次预测一张图),通道数(即xyz共3维),输入点数。输出是(batch_size,num_class)指的是该点云num_class个类别的得分,对他取最大值即可得到最后的预测的类别。
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))
import numpy as np
from models import pointnet2_cls_ssg as net
import torch
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc**2, axis=1)))
pc = pc / m
return pc
def test(points):
points=points[None,:,:]
points = points.transpose(0,2, 1)
#将numpy格式转换为tensor格式
tensor_data=torch.tensor(points)
#放进gpu中
torch.cuda.set_device(0)
tensor_data.cuda()
#预测
with torch.no_grad():
pred, _ = model(tensor_data)
pred=np.argmax(pred.detach().cpu().numpy())
return pred
def main():
data_path=r"data\modelnet40_normal_resampled\airplane"
weight_path=r"\Pointnet_Pointnet2_pytorch-master\log\classification\pointnet2_cls_ssg\checkpoints\best_model.pth"
num_class=10
npoints=2048
global model
model=net.get_model(num_class, normal_channel=False)
checkpoint = torch.load(weight_path)
model.load_state_dict(checkpoint['model_state_dict'])
for file in os.listdir(data_path):
if file.endswith(".txt"):
point_set=np.genfromtxt(os.path.join(data_path,file), delimiter=',').astype(np.float32)
point_set[:, 0:3] = pc_normalize(point_set[:, 0:3])
choice = np.random.choice(len(point_set.shape[0]),npoints, replace=True)
point_set = point_set[choice, :3]
#预测类别的下标
pred=test( point_set)
print(f"{file}的类别是{pred}")
if __name__=="__main__":
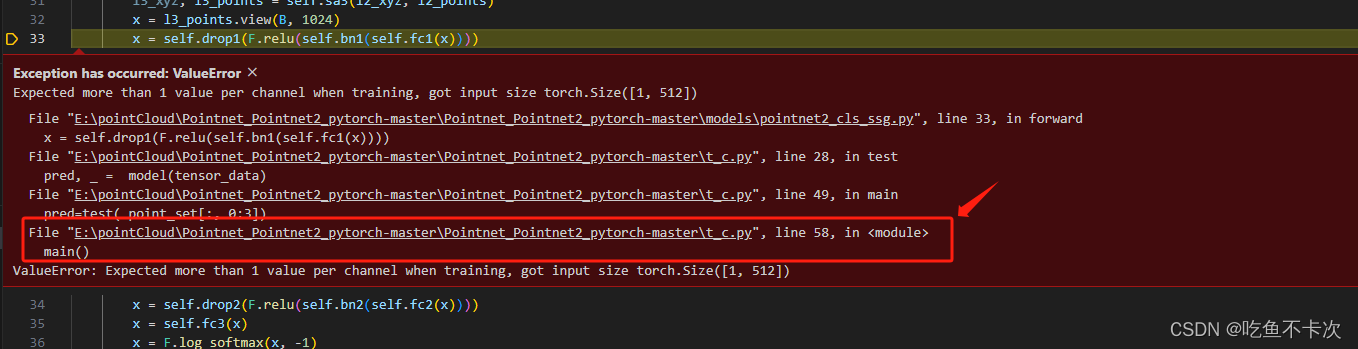
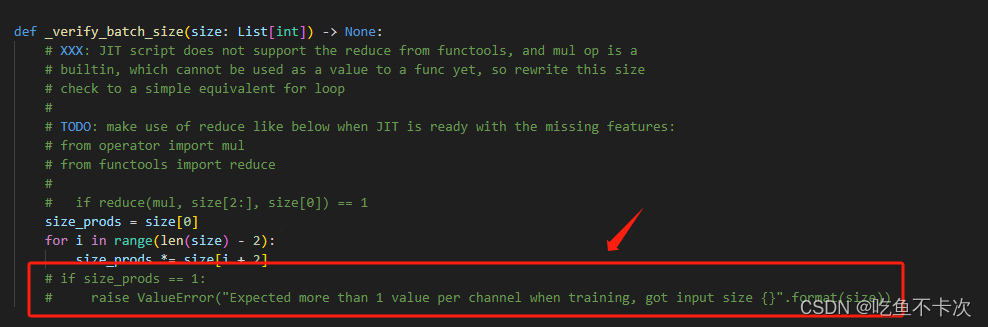
main()其中会遇到一个bug,大概意思就是说取batchsize为1时无法做BN,参考博客,注释了两行源码,如下所示。
 2.PartSegmantation
2.PartSegmantation
输入依旧是(batch_size,channel,npoints),输出变成了(batch,npoints,num_classes),从预测一个点云类别,变成了预测点云上所有点的类别,废话不多说,直接上代码。
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))
import numpy as np
from models import pointnet2_part_seg_msg as net
import torch
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc**2, axis=1)))
pc = pc / m
return pc
def to_categorical(y, num_classes):
""" 1-hot encodes a tensor """
new_y = torch.eye(num_classes)[y.cpu().data.numpy(),]
if (y.is_cuda):
return new_y.cuda()
return new_y
def test(points,matrix):
points=points[None,:,:]
points = points.transpose(0,2,1)
#将numpy格式转换为tensor格式
tensor_data=torch.tensor(points)
#放进gpu中
torch.cuda.set_device(0)
tensor_data.cuda()
#预测
with torch.no_grad():
seg_pred, _ = model(tensor_data, matrix)
seg_pred=seg_pred.detach().cpu().numpy().squeeze()
seg_pred=np.argmax(seg_pred[:, seg_classes[cls]], 1) + seg_classes[cls][0]
return seg_pred
seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46], 'Mug': [36, 37],
'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27], 'Table': [47, 48, 49],
'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40], 'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
def main():
path=r"data\shapenetcore_partanno_segmentation_benchmark_v0_normal\02691156"
weight_path=r"Pointnet_Pointnet2_pytorch-master\log\part_seg\pointnet2_part_seg_msg\checkpoints\best_model.pth"
npoints=2048
num_class = 16
num_part = 50
global cls
cls="Earphone"
classes={'Airplane': 0, 'Bag': 1, 'Cap': 2, 'Car': 3, 'Chair': 4, 'Earphone': 5, 'Guitar': 6, 'Knife': 7, 'Lamp': 8, 'Laptop': 9, 'Motorbike': 10, 'Mug': 11, 'Pistol': 12, 'Rocket': 13, 'Skateboard':14,'Table':15}
global model
model=net.get_model(num_part, normal_channel=True)
checkpoint = torch.load(weight_path)
model.load_state_dict(checkpoint['model_state_dict'])
for file in os.listdir(path):
if file.endswith(".txt"):
point_set=np.loadtxt(os.path.join(path,file)).astype(np.float32)
point_set[:, 0:6] = pc_normalize(point_set[:, 0:6])
choice = np.random.choice(point_set.shape[0],npoints, replace=True)
point_set = point_set[choice, :6]
#预测类别的下标
pred=test(point_set,to_categorical(torch.tensor(classes[cls]),len(classes)))
result=np.concatenate([point_set,pred[:,None]],axis=1)
np.savetxt(f"pre_{file}",result)
if __name__=="__main__":
main()3.Segmantation
这个其实和部件分割差不多,差别就在于部件分割的点数很少,不需要额外的预处理就可以通过网络直接预测,而语义分割要预测的场景一般比较大,比如S3DIS,一个Area有上千万个点很正常。如果你是要预测小规模的点云,完全可以按照上面部件分割的代码来修改。如果是要预测大场景点云,后面有时间我再整理一下代码,预测S3DIS数据集如何进行预处理,预测和拼接。
未完待续。。。


















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











