







- 问题引入
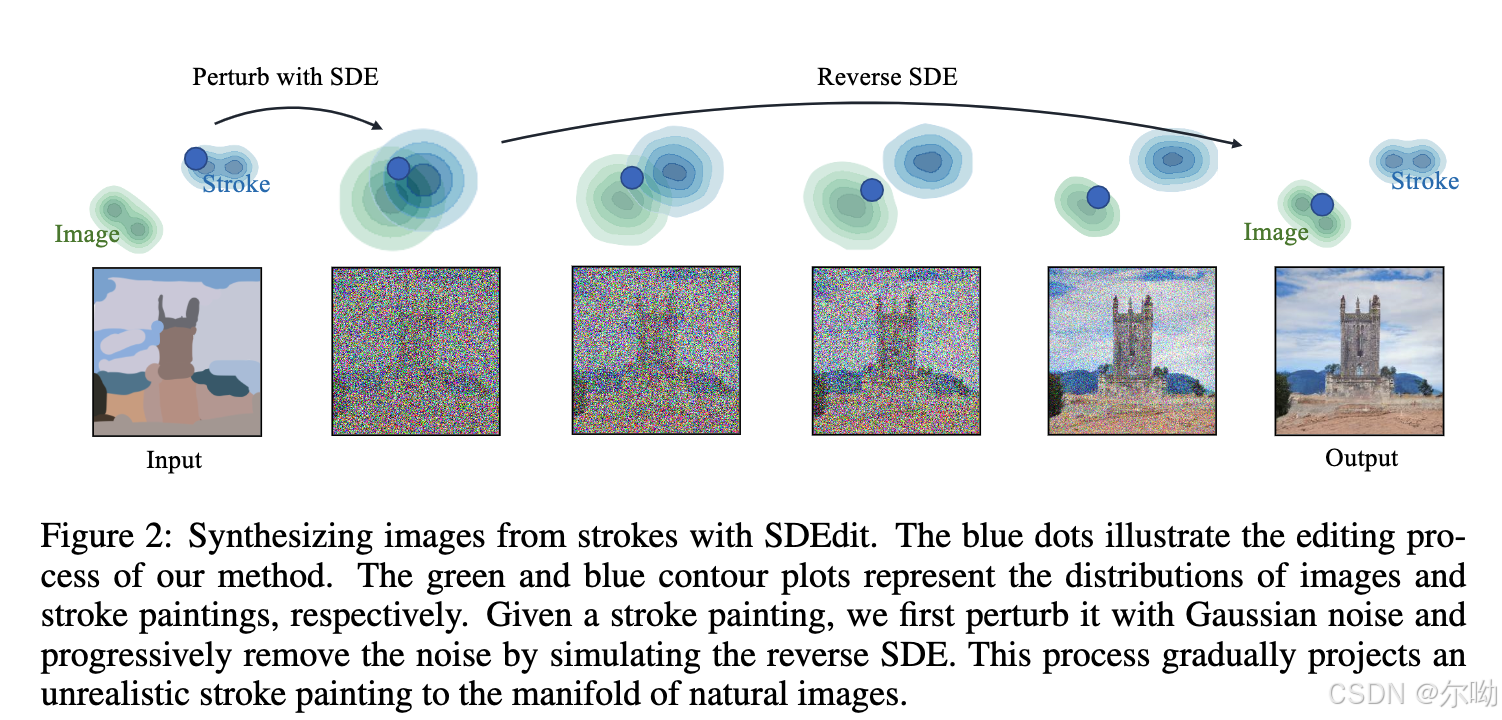
- 解决的问题包括stroke painting to image, image composition, stroke based editing,示意图如下:

- 方法是首先对输入加噪,之后进行去噪,该方法可以不通过额外的训练以及新的损失函数就可以实现1)和输入的一致性以及2)高真实性两个目标;
- methods
- stochastic differential equations(SDEs): 对于从数据中采样得到的 x ( 0 ) ∼ p 0 = p d a t a x(0)\sim p_0=p_{data} x(0)∼p0=pdata,经过forward SDE加噪得到 x ( t ) , t ∈ ( 0 , 1 ] , x ( t ) = α ( t ) x ( 0 ) + σ ( t ) z , z ∼ N ( 0 , I ) x(t),t\in(0,1],x(t) = \alpha(t)x(0)+\sigma(t)z,z\sim N(0,I) x(t),t∈(0,1],x(t)=α(t)x(0)+σ(t)z,z∼N(0,I),其中 σ ( t ) : [ 0 , 1 ] → [ 0 , ∞ ) \sigma(t):[0,1]\rightarrow [0,\infty) σ(t):[0,1]→[0,∞)是一个标量方程,形容噪声的程度, α ( t ) : [ 0 , 1 ] → [ 0 , 1 ] \alpha(t):[0,1]\rightarrow[0,1] α(t):[0,1]→[0,1]也是一个标量方程控制原图的magnitude, x ( t ) x(t) x(t)的概率密度方程用 p t p_t pt表示;
- 包含两种SDE,variance exploding SDE,VE-SDE( α ( t ) = 1 \alpha(t)=1 α(t)=1for all t, σ ( 1 ) \sigma(1) σ(1)是一个大的常量,此时的概率密度函数 p 1 ∼ N ( 0 , σ 2 ( 1 ) I p_1\sim N(0, \sigma^2(1)I p1∼N(0,σ2(1)I),另一种是variance preserving(VP) SDE( α 2 ( t ) + σ 2 ( t ) = 1 \alpha^2(t) + \sigma^2(t)=1 α2(t)+σ2(t)=1,当 t ∼ 1 t\sim 1 t∼1时, α ( t ) ∼ 0 , p 1 ∼ N ( 0 , I ) \alpha(t)\sim 0,p_1\sim N(0, I) α(t)∼0,p1∼N(0,I)),两种SDE都随着 t t t从0到1,逐渐将分布转化为随机的高斯噪声;
- 在ve-sde的设定之下,image synthesis的过程可以通过reverse sde来实现,noise perturbed score function ∇ x log p t ( x ) \nabla_x\log{p_t(x)} ∇xlogpt(x),reverse sde d x ( t ) = [ − d [ σ 2 ( t ) ] d t ∇ x log p t ( x ) ] d t + d [ σ 2 ( t ) ] d t d w ‾ dx(t) = \left[-\frac{d[\sigma^2(t)]}{dt}\nabla_x\log{p_t(x)}\right]dt + \sqrt{\frac{d[\sigma^2(t)]}{dt}}d\overline{w} dx(t)=[−dtd[σ2(t)]∇xlogpt(x)]dt+dtd[σ2(t)]dw,其中 w ‾ \overline{w} w是Wiener process,起点是 x ( 1 ) ∼ p 1 = N ( 0 , σ 2 ( 1 ) I ) x(1)\sim p_1 = N(0,\sigma^2(1)I) x(1)∼p1=N(0,σ2(1)I),最后 x ( 0 ) x(0) x(0)满足 p d a t a p_{data} pdata的分布,noise perturbed score function ∇ x log p t ( x ) \nabla_x\log{p_t(x)} ∇xlogpt(x)可以通过denoising score matching来得到,目标是 L t = E x ( 0 ) ∼ p d a t a , z ∼ N ( 0 , I ) [ ∣ ∣ σ t s θ ( x ( t ) , t ) − z ∣ ∣ 2 2 ] L_t = \mathbb{E}_{x(0)\sim p_{data},z\sim N(0,I)}[||\sigma_ts_\theta(x(t),t)-z||^2_2] Lt=Ex(0)∼pdata,z∼N(0,I)[∣∣σtsθ(x(t),t)−z∣∣22], s θ ( x ( t ) , t ) s_\theta(x(t),t) sθ(x(t),t)近似 ∇ x log p t ( x ) \nabla_x\log{p_t(x)} ∇xlogpt(x),SDE solution可以用Euler-maruyama method来近似,从 t + Δ t t+\Delta t t+Δt到 t t t的更新: x ( t ) = x ( t + Δ t ) + ( σ 2 ( t ) − σ 2 ( t + Δ t ) ) s θ ( x ( t ) , t ) + σ 2 ( t + Δ t ) − σ 2 ( t ) z x(t) = x(t + \Delta t) + (\sigma^2(t)-\sigma^2(t + \Delta t))s_\theta(x(t),t) + \sqrt{\sigma^2(t + \Delta t)-\sigma^2(t)}z x(t)=x(t+Δt)+(σ2(t)−σ2(t+Δt))sθ(x(t),t)+σ2(t+Δt)−σ2(t)z,选取一个 1 ∼ 0 1\sim 0 1∼0的discretizationd的方法,就可以得到 x ( 0 ) x(0) x(0);在本文中 σ ( t ) = { 0 t = 0 σ m i n ( σ m a x σ m i n ) t t > 0 , σ m i n = 0.01 , σ m a x = 380 , 378 , 348 , 1348 \sigma(t)=\begin{cases} 0& t= 0\\ \sigma_{min}(\frac{\sigma_{max}}{\sigma_{min}})^t & t > 0 \end{cases},\sigma_{min} = 0.01,\sigma_{max}=380,378,348,1348 σ(t)={0σmin(σminσmax)tt=0t>0,σmin=0.01,σmax=380,378,348,1348对于不同的数据集;
- 在vp-sde的设定之下, d x ( t ) = − 1 2 β ( t ) x ( t ) d t + β ( t ) d w ( t ) , β ( t ) = β m i n + t ( β m a x − β m i n ) , β m i n = 0.1 , β m a x = 20 dx(t) = -\frac12\beta(t)x(t)dt + \sqrt{\beta(t)}dw(t),\beta(t) = \beta_{min} + t(\beta_{max}-\beta_{min}),\beta_{min}=0.1,\beta_{max}=20 dx(t)=−21β(t)x(t)dt+β(t)dw(t),β(t)=βmin+t(βmax−βmin),βmin=0.1,βmax=20,此时 x n − 1 = 1 1 − β ( t n ) Δ t ( x n + β ( t n ) Δ t s θ ( x ( t n ) , t n ) ) + β ( t n ) Δ t z n x_{n - 1} = \frac{1}{\sqrt{1 - \beta(t_n)\Delta t}}(x_n + \beta(t_n)\Delta ts_\theta(x(t_n),t_n))+\sqrt{\beta(t_n)\Delta t}z_n xn−1=1−β(tn)Δt1(xn+β(tn)Δtsθ(x(tn),tn))+β(tn)Δtzn;
- 该方法在faithful和realistic之间权衡,选取的 t 0 t_0 t0越大,也就是加噪程度越大,越realistic;
- 输入的图片
x
(
g
)
x^{(g)}
x(g),选取
t
0
t_0
t0,对输入进行加噪得到
x
(
g
)
(
t
0
)
∼
N
(
x
(
g
)
;
σ
2
(
t
0
)
I
)
x^{(g)}(t_0)\sim N(x^{(g)};\sigma^2(t_0)I)
x(g)(t0)∼N(x(g);σ2(t0)I),之后再进行去噪的步骤得到
x
(
0
)
x(0)
x(0),对应ve-sde的算法如下:

对应vp-sde的算法如下:

- 对于image composition和stroke base editing任务来说,希望未经edit的部分和原图保持一致,给出
Ω
∈
{
0
,
1
}
C
×
H
×
W
\Omega\in\{0,1\}^{C\times H\times W}
Ω∈{0,1}C×H×W,1表示可编辑区域,其中可编辑区域的操作和上面一样,先加噪再去噪,未编辑区域的中间
x
(
t
)
x(t)
x(t)使用原图加噪到指定
t
t
t来替换:



















 1644
1644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









