







- HKU&Microsoft NeurIPS 2023
- https://github.com/ShihaoZhaoZSH/Uni-ControlNet
- https://arxiv.org/pdf/2305.16322
- 问题引入
- 为文生图模型增加文本以外的生成控制条件,包含两类local controls (e.g., edge maps, depth map, segmentation masks) and global controls (e.g., CLIP image embeddings),并且无论是什么条件组合都只需要额外训练两个adapter;
- 区别于之前方法的需要全参数微调或者为每一种条件都需要专门训练对应的adapter;
- methods
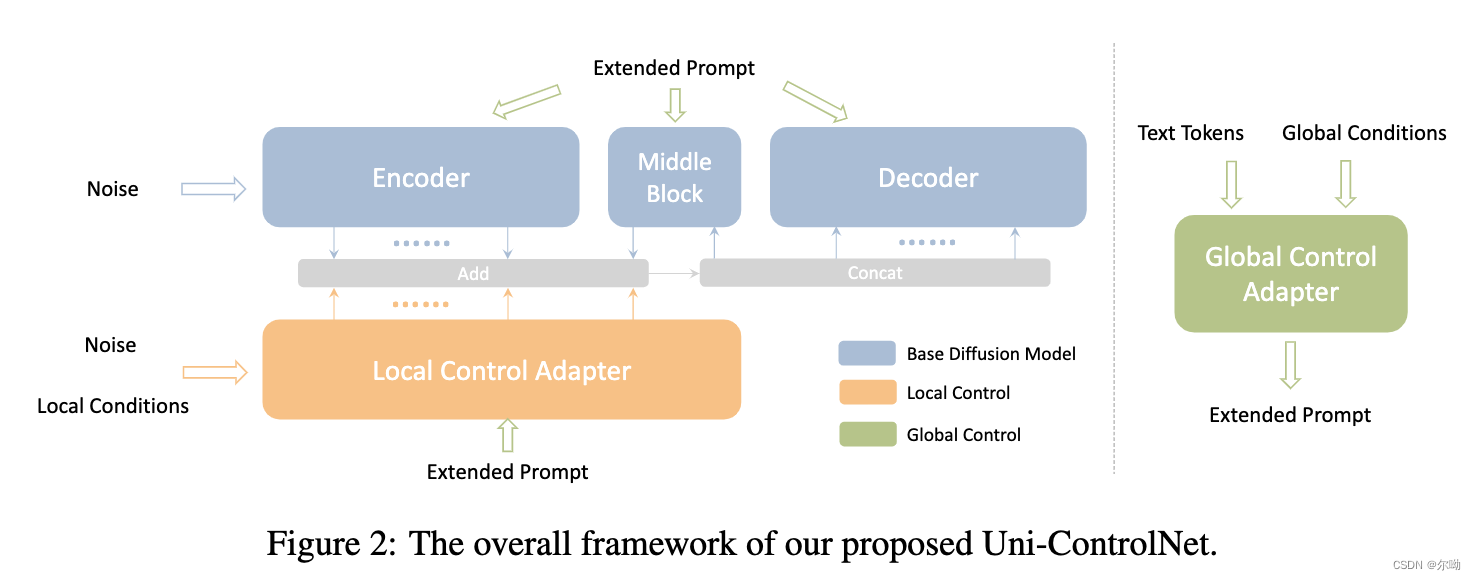
- 使用 F , M , G F,M,G F,M,G分别表示unet的encoder,middle,decoder三部分, f i , m , g i f_i,m,g_i fi,m,gi分别表示对应block的输出,因为skip connection,decoder对应的block的输入由 { c o n c a t ( m , f j ) i = 1 , i + j = 13 c o n c a t ( g i − 1 , f j ) 2 ≤ i ≤ 12 , i + j = 13 \begin{cases}concat(m,f_j) & i = 1,i+j=13\\concat(g_{i - 1}, f_j) &2\leq i\leq12,i+j=13\end{cases} {concat(m,fj)concat(gi−1,fj)i=1,i+j=132≤i≤12,i+j=13, y y y表示text embedding;
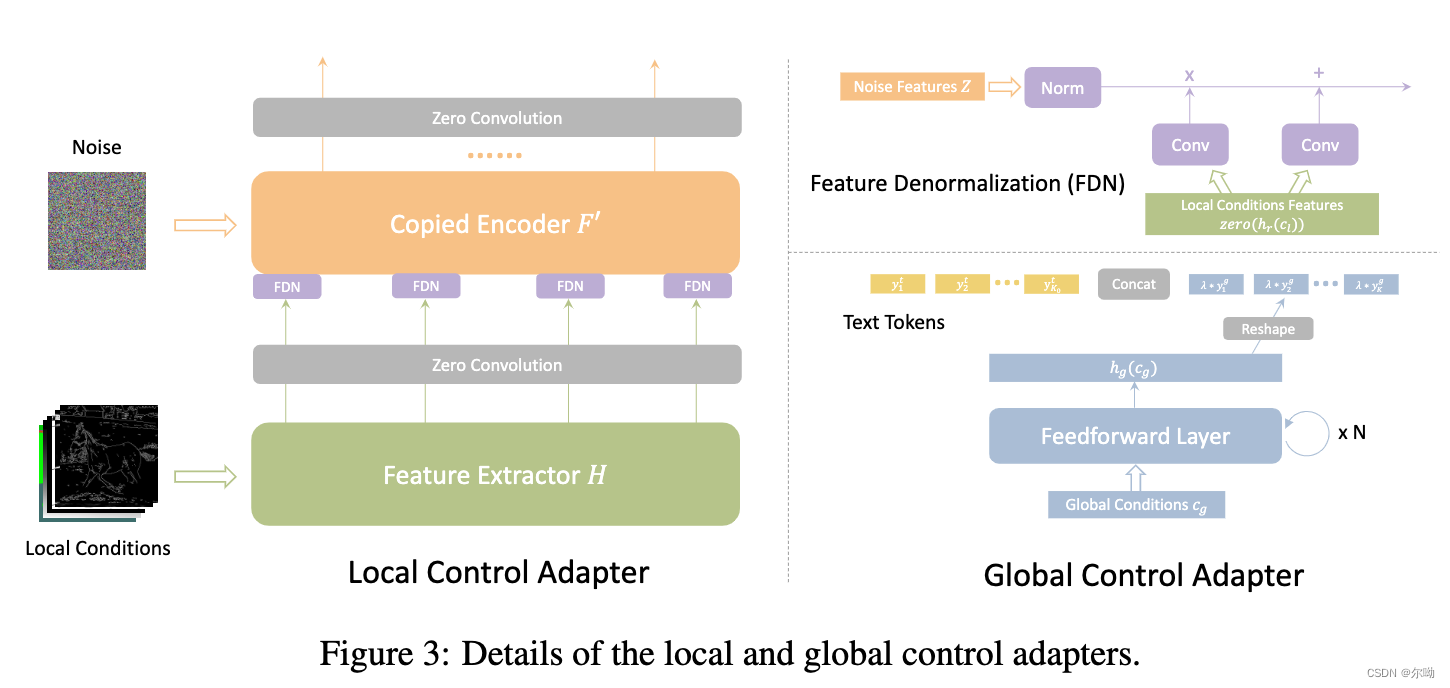
- local adapter:复制了一份encoder和middle block
F
′
,
M
′
F',M'
F′,M′,之后再decoder部分进行信息integrate,
{
c
o
n
c
a
t
(
m
+
m
′
,
f
j
+
z
e
r
o
(
f
j
′
)
)
i
=
1
,
i
+
j
=
13
c
o
n
c
a
t
(
g
i
−
1
,
f
j
+
z
e
r
o
(
f
j
′
)
)
2
≤
i
≤
12
,
i
+
j
=
13
\begin{cases}concat(m + m',f_j + zero(f'_j)) & i = 1,i+j=13\\concat(g_{i - 1}, f_j + zero(f_j')) &2\leq i\leq12,i+j=13\end{cases}
{concat(m+m′,fj+zero(fj′))concat(gi−1,fj+zero(fj′))i=1,i+j=132≤i≤12,i+j=13,与controlnet不同的是controlnet将condition和noisy latent进行concat作为复制的encoder的输入,本文采取了另外的condition injection策略,首先将不同的local condition进行concat,然后使用feature extractor
H
H
H来提取不同scale的特征,选择复制的encoder的每个scale的第一个block作为condition injection的位置,injection通过FDN(feature denormalization)完成,
F
D
N
r
(
Z
r
,
c
l
)
=
n
o
r
m
(
Z
r
)
⋅
(
1
+
c
o
n
v
γ
(
z
e
r
o
(
h
r
(
c
l
)
)
)
)
+
c
o
n
v
β
(
z
e
r
o
(
h
r
(
c
l
)
)
)
FDN_r(Z_r,c_l) = norm(Z_r)\cdot(1 + conv_\gamma(zero(h_r(c_l)))) + conv_\beta(zero(h_r(c_l)))
FDNr(Zr,cl)=norm(Zr)⋅(1+convγ(zero(hr(cl))))+convβ(zero(hr(cl))),其中
c
l
c_l
cl是concat的condition,
h
r
h_r
hr是对应scale的feature extractor
H
H
H的输出,
c
o
n
v
γ
,
c
o
n
v
β
conv_\gamma,conv_\beta
convγ,convβ分别是convert condition features into spatial-sensitive scale and shift modulation
coefficients; - global adapter:例如通过CLIP image encoder得到的image embedding c g c_g cg,首先经过condition encoder h g h_g hg,包含若干FFN,之后进行reshape到 K K K长度,再和 K 0 K_0 K0个text token进行concat操作, K K K个token在拼接的时候乘上了一个系数 λ \lambda λ;
- 训练策略:分开训练两个类型的adapter,训练时随机丢弃一些条件,丢弃条件对应的channel置为0;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









