







 超级会员免费看
超级会员免费看
 3DETR是一种基于Transformer的3D目标检测模型,使用非参数查询和傅里叶位置嵌入。在ScanNetV2上相比VoteNet提升9.5%,并适用于其他三维任务。模型接收点云输入,通过编码器和解码器预测3D边界框,采用集合匹配和损失函数进行训练优化。
3DETR是一种基于Transformer的3D目标检测模型,使用非参数查询和傅里叶位置嵌入。在ScanNetV2上相比VoteNet提升9.5%,并适用于其他三维任务。模型接收点云输入,通过编码器和解码器预测3D边界框,采用集合匹配和损失函数进行训练优化。
3DETR: An End-to-End Transformer Model for 3D Object Detection
论文简介:
本文提出了基于端到端的 3D 目标检测模型,并提出了具有非参数查询和傅里叶位置嵌入的 Transformer。通过大量的实验发现,3DETR 在具有挑战性的 ScanNetV2 数据集上比 VoteNet 基线高出9.5%。此外,本文还展示了 3DETR 适用于检测之外的三维任务,并可以作为未来研究的构建块。
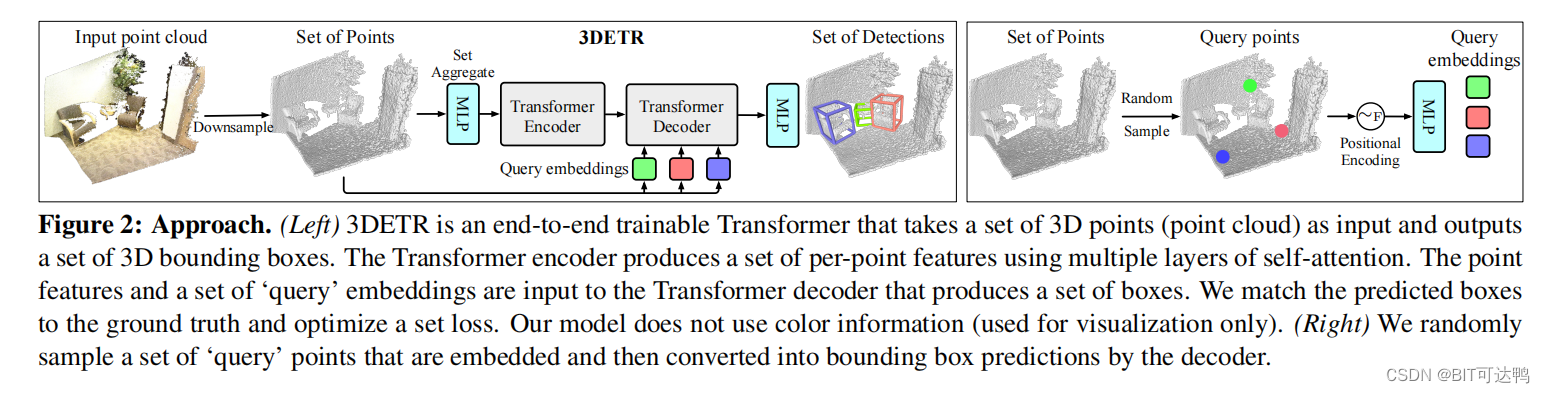
其中 3DETR 是一种端到端可训练的 Transformer,它以一组三维点(点云)作为输入,并输出一组三维边界框。编码器使用多层自注意产生一组点特征。点特征和一组“查询”嵌入被输入到产生一组边界框的解码器中。然后将预测的盒子与地面真实值相匹配,并优化一个集合损失。
注意该模型不使用颜色信息,斌且随机抽样一组嵌入的“查询”点,这些点然后被解码器转换为边界框预测。
具体实现:
基本框架
3DETR 以一个三维点云作为输入,并以三维边界框的形式预测物体的位置。点云是

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











