







目录
双塔模型
矩阵补充模型只用到了用户id和物品id,其余属性没有用上
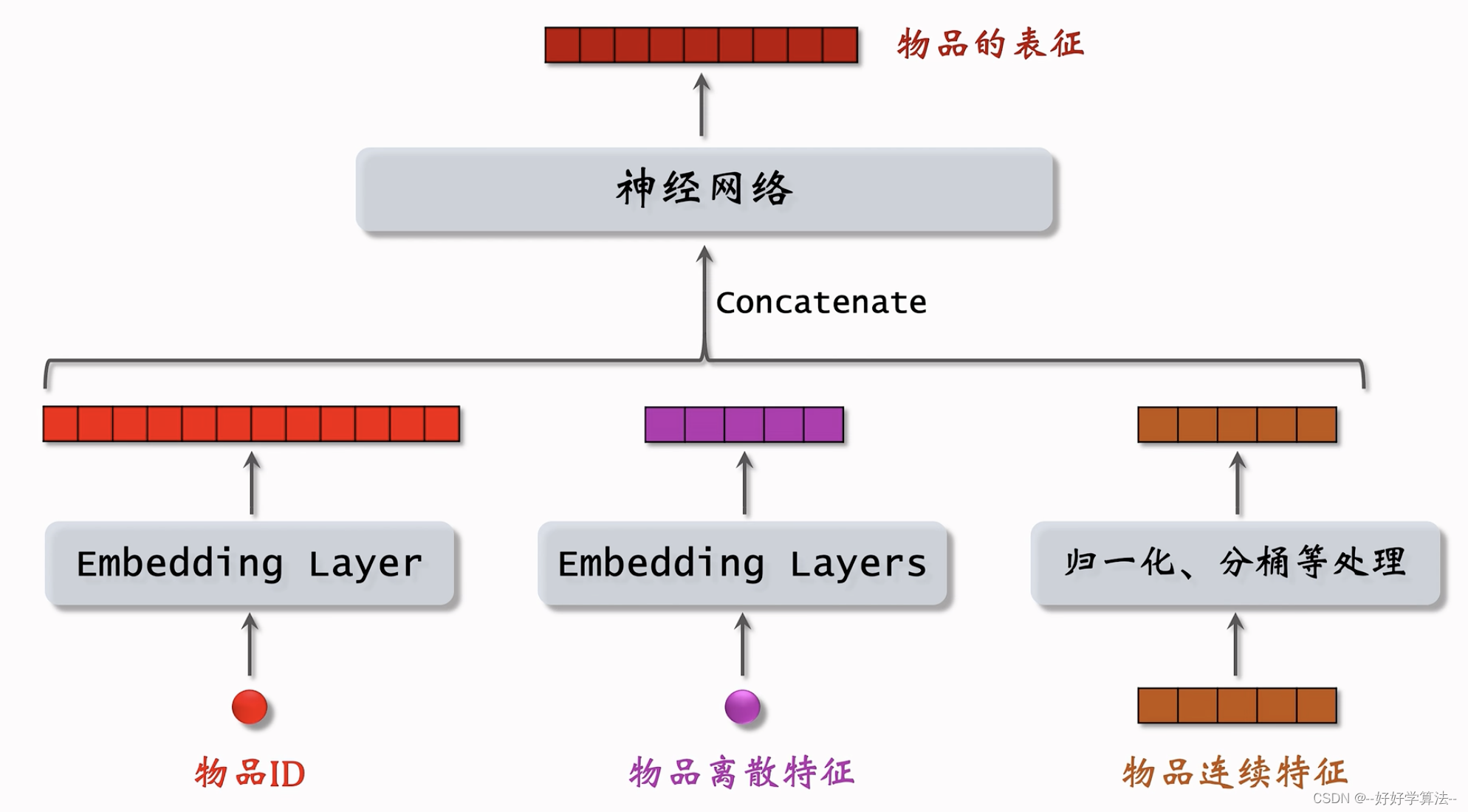
用户属性也可以这样处理
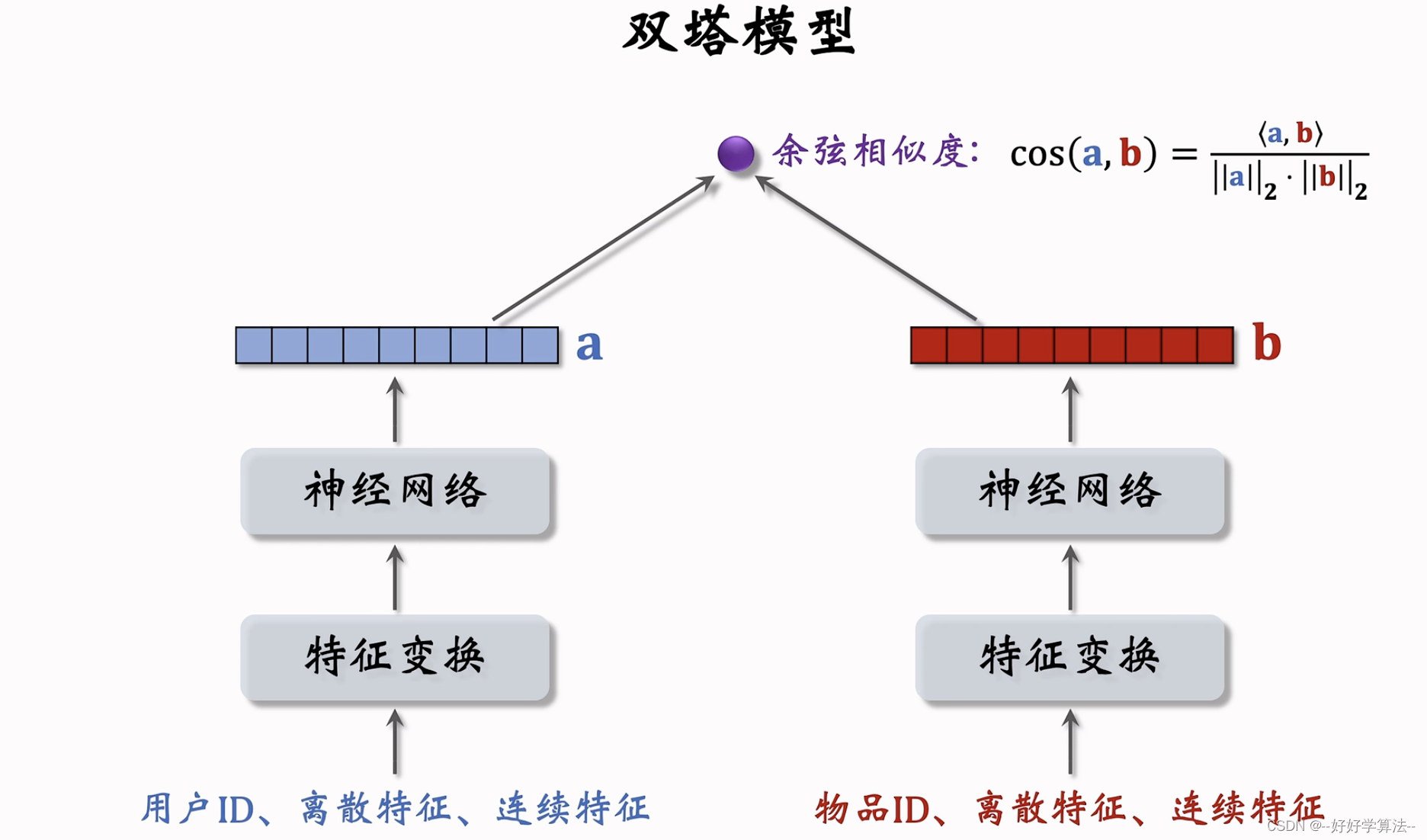
用户塔和物品塔各输出一个向量,两个向量的余弦相似度作为兴趣的预估值
训练
第一种:pointwise,独立看待每个正负样本,做二分类
第二种:pairwise,每次取一个正样本一个负样本
第三种:listwise,每次取一个正样本多个负样本,多分类
正负样本的选择:
正样本:用户点击
负样本:未被召回的,召回但是被粗排精排淘汰的,曝光但是未点击的(具体怎么选择后面会讲)
pointwise训练
把召回看作二元分类任务,鼓励正样本相似度接近1,负样本相似度接近-1
控制正负样本比例1:2,1:3(互联网大厂的经验之言)
pairwise训练
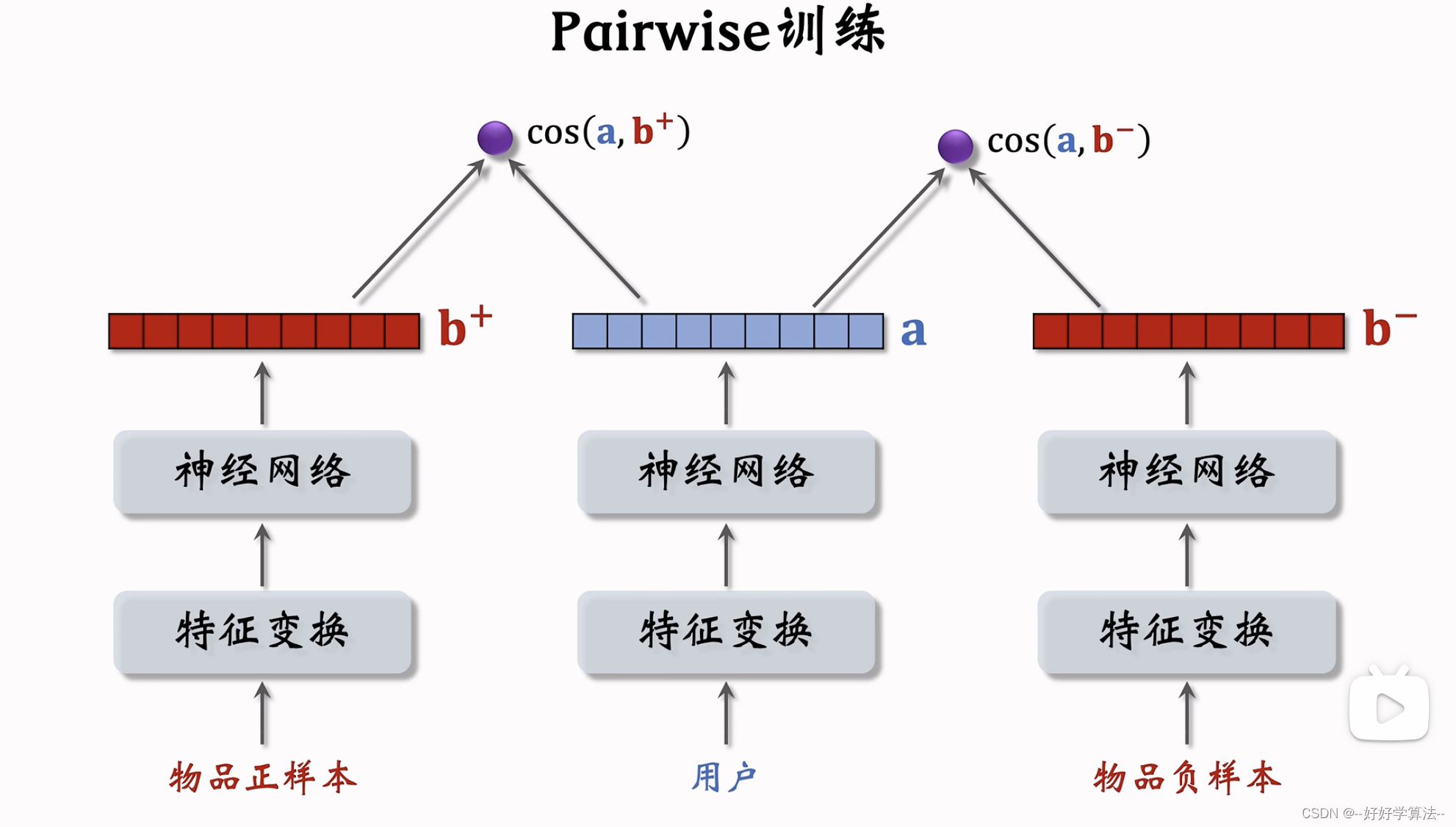
损失:鼓励cos(a,b+)大于cos(a,b-)
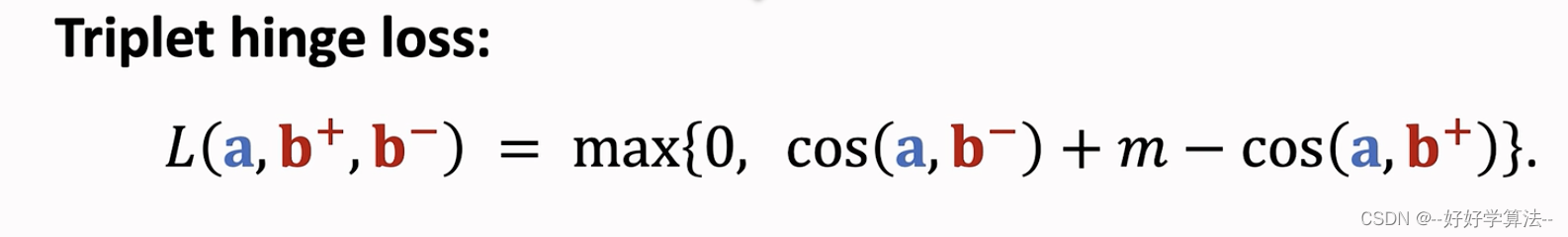
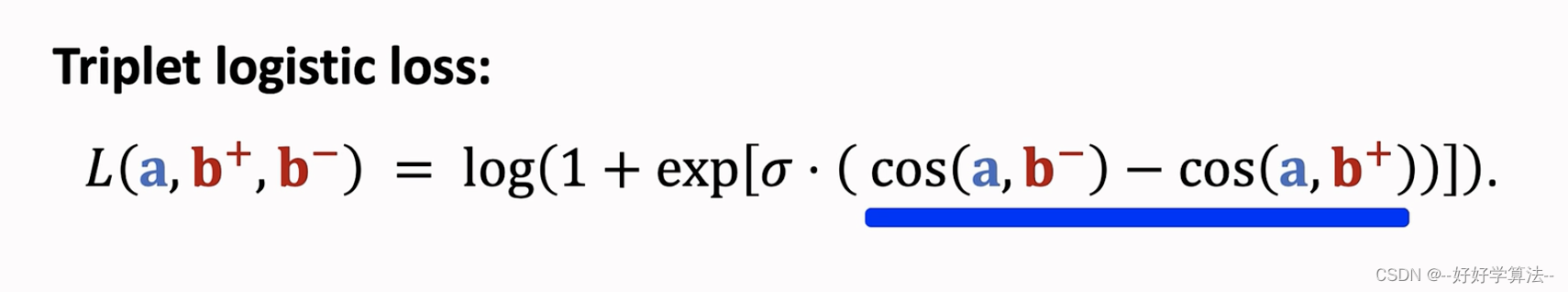
listwise训练
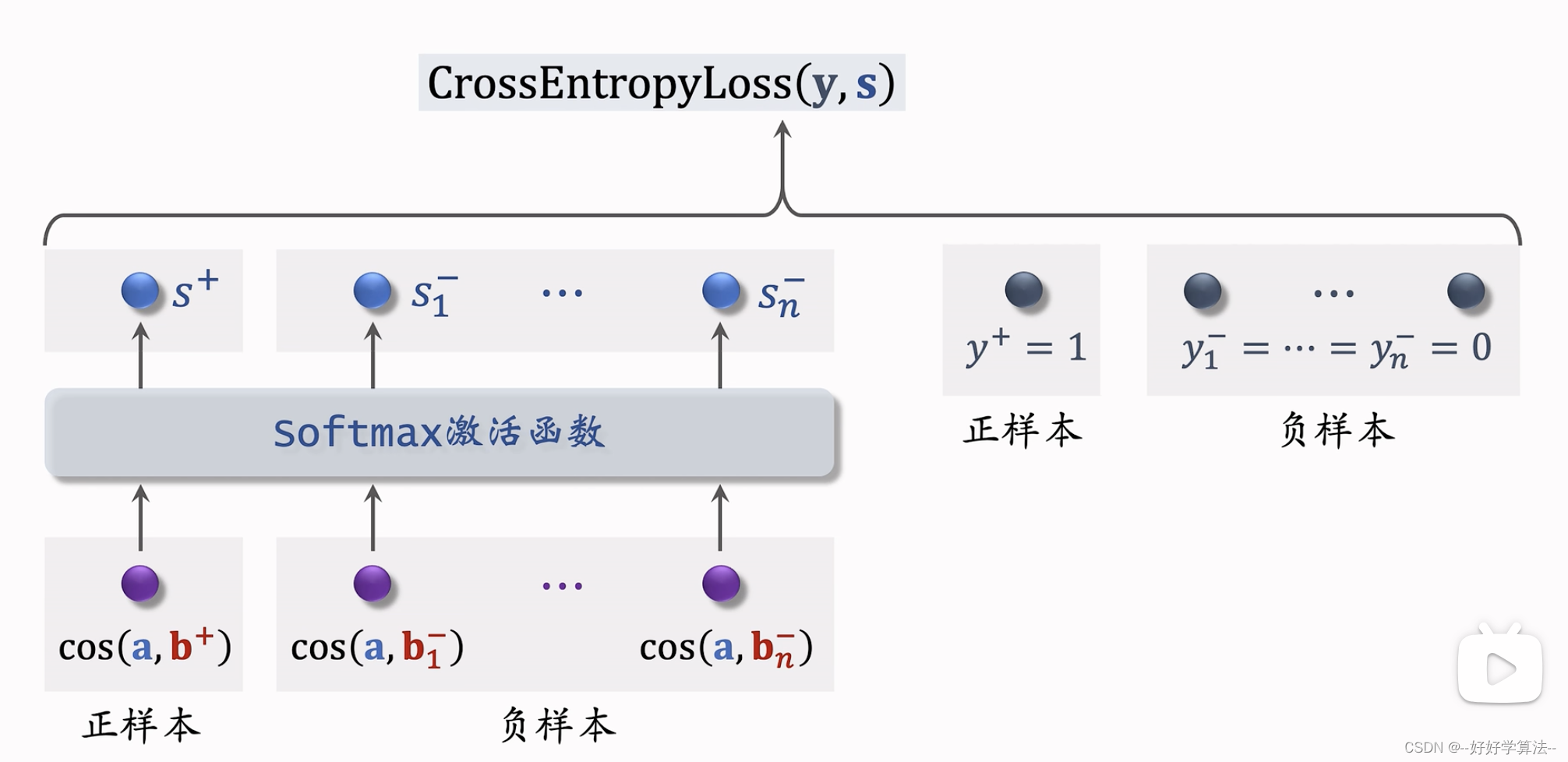
最小化交叉熵
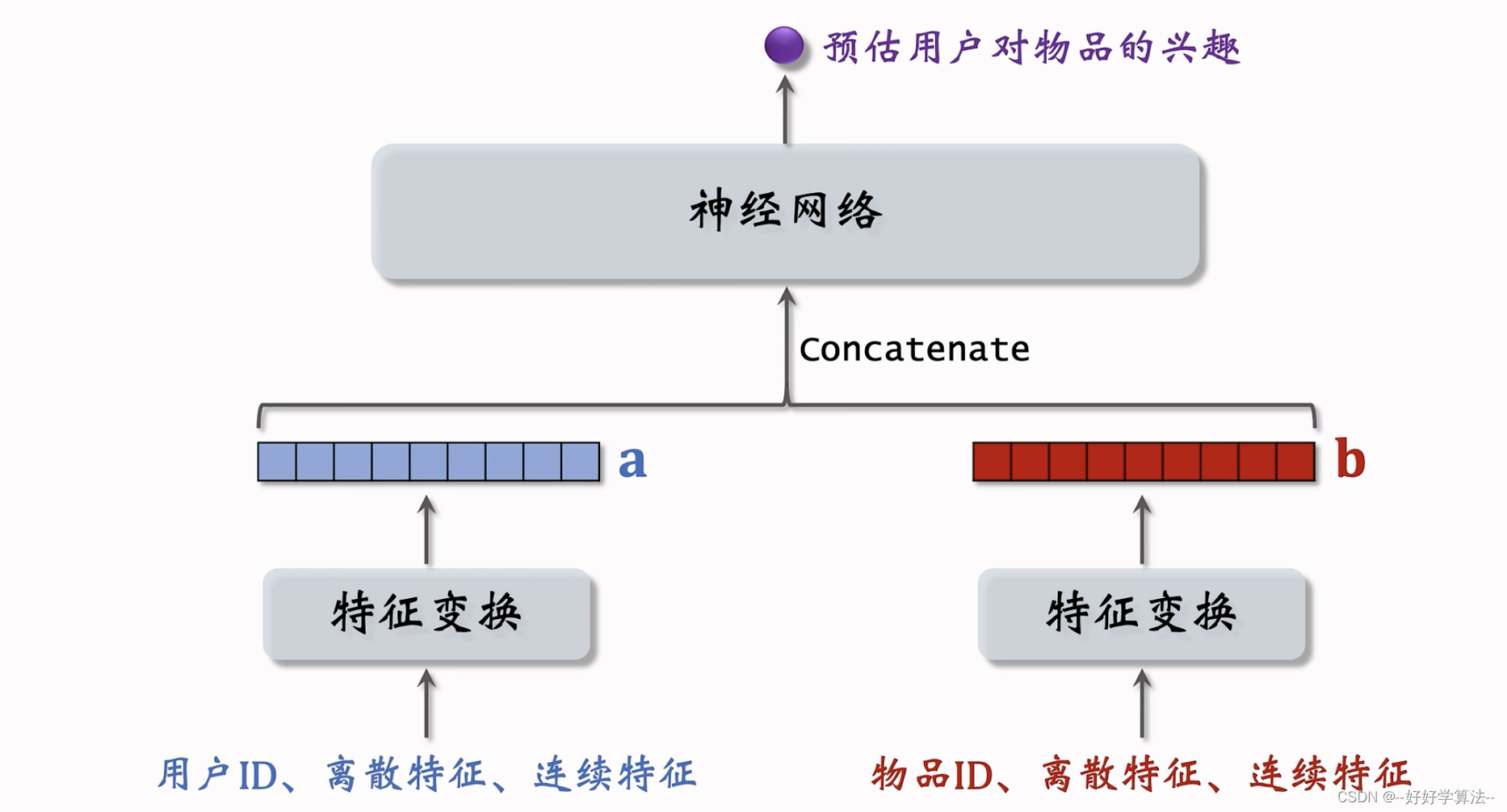
错误设计:下面的模型不用于召回,前期融合(进入神经网络前就融合了),不是双塔模型,可以用作精排和粗排,计算量不会太大,召回只能用后期融合(神经网络之后)的模型
正负样本的选取
选对正负样本的效果要大于模型结构
正样本:曝光且点击的用户-物品二元祖
问题:二八法则,过多热门物品,热门更热
解决:对冷门做过采样,一个样本出现多次;对热门降采样,一定概率抛弃热门,概率与点击次数正相关
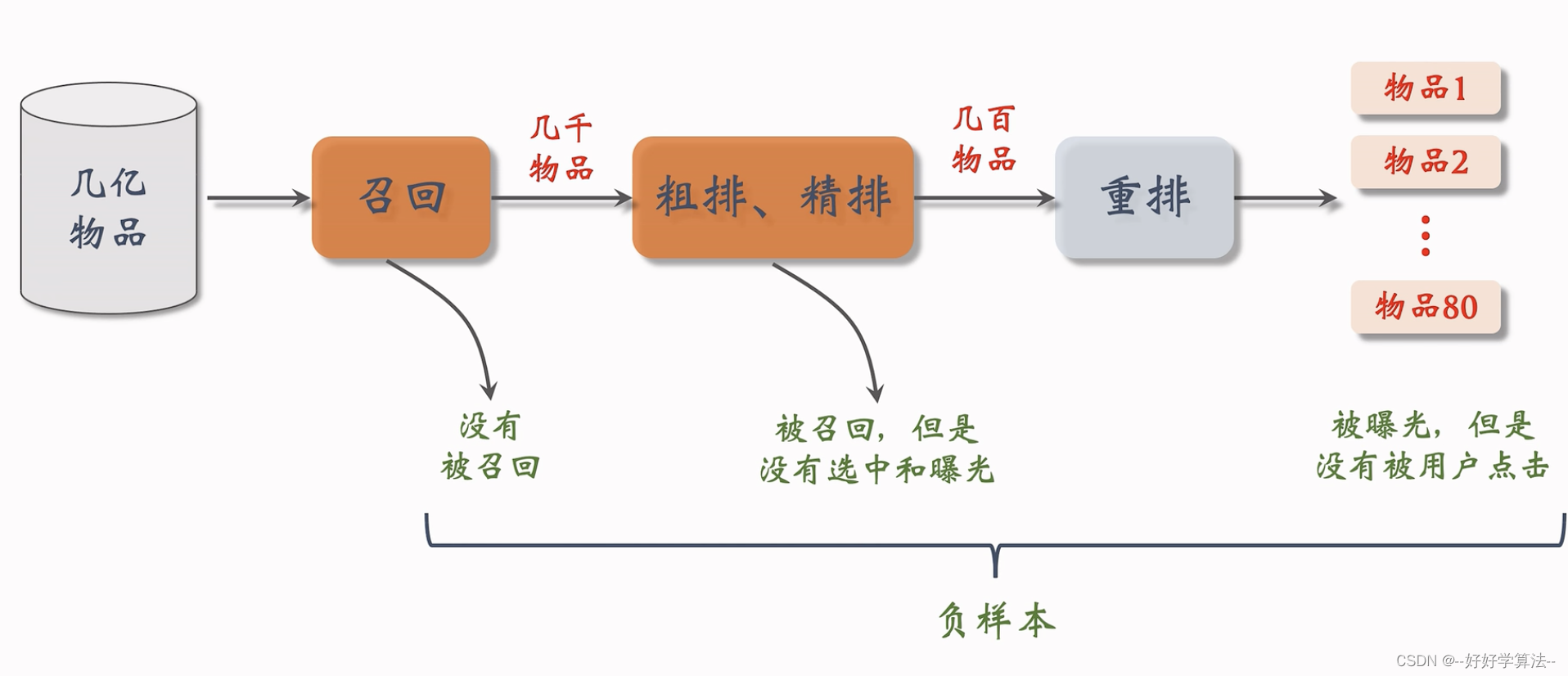
召回:从上亿笔记取回几千篇
粗排,精排:打分
重排:多样性采样,规则调整
负样本:
链路上每一步被淘汰的物品
简单负样本
未被召回的物品 约等于 全体物品,对全体物品随机抽样即可
如何抽样:
❌均匀:对冷门不公平,少部分占据大多点击,负样本大部分都是冷门
✔️随机非均匀:与热门程度正相关(点击次数),约热门越容易被当成负样本

0.75是经验值
batch内负样本
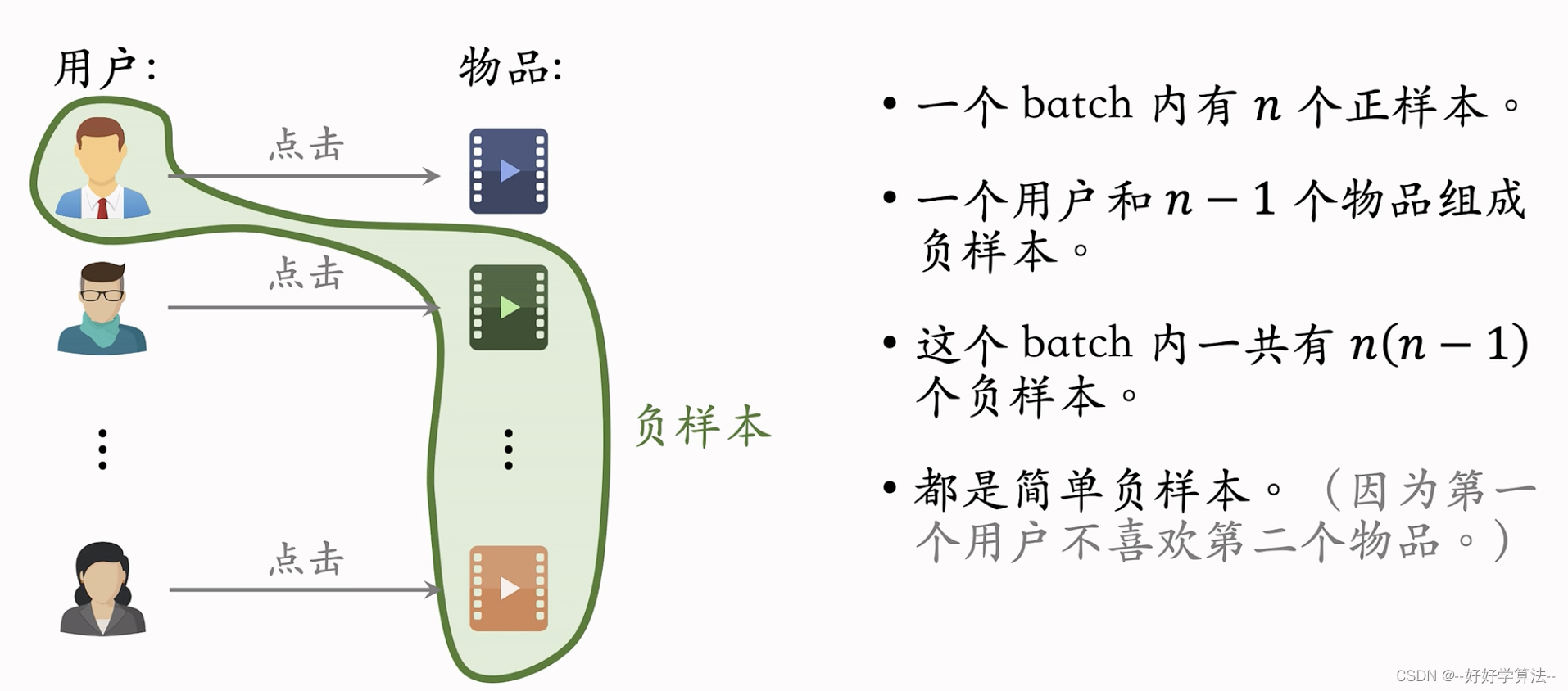
问题:
物品出现在batch内出现的概率正比于它的热门程度,如果batch内负采样,正比于1次方,但本应该是0.75次方,热门成为负样本的概率过大,模型对它打压过大,需要修正偏差。

线上召回不用调整,依旧是余弦相似度
困难负样本
被粗排精排淘汰的样本,因为这些样本已经比较符合用户兴趣--容易分错
双塔--二元分类任务
常见的错误❌
曝光但未点击的作为负样本,效果会变差,排序可以用,召回不可以用
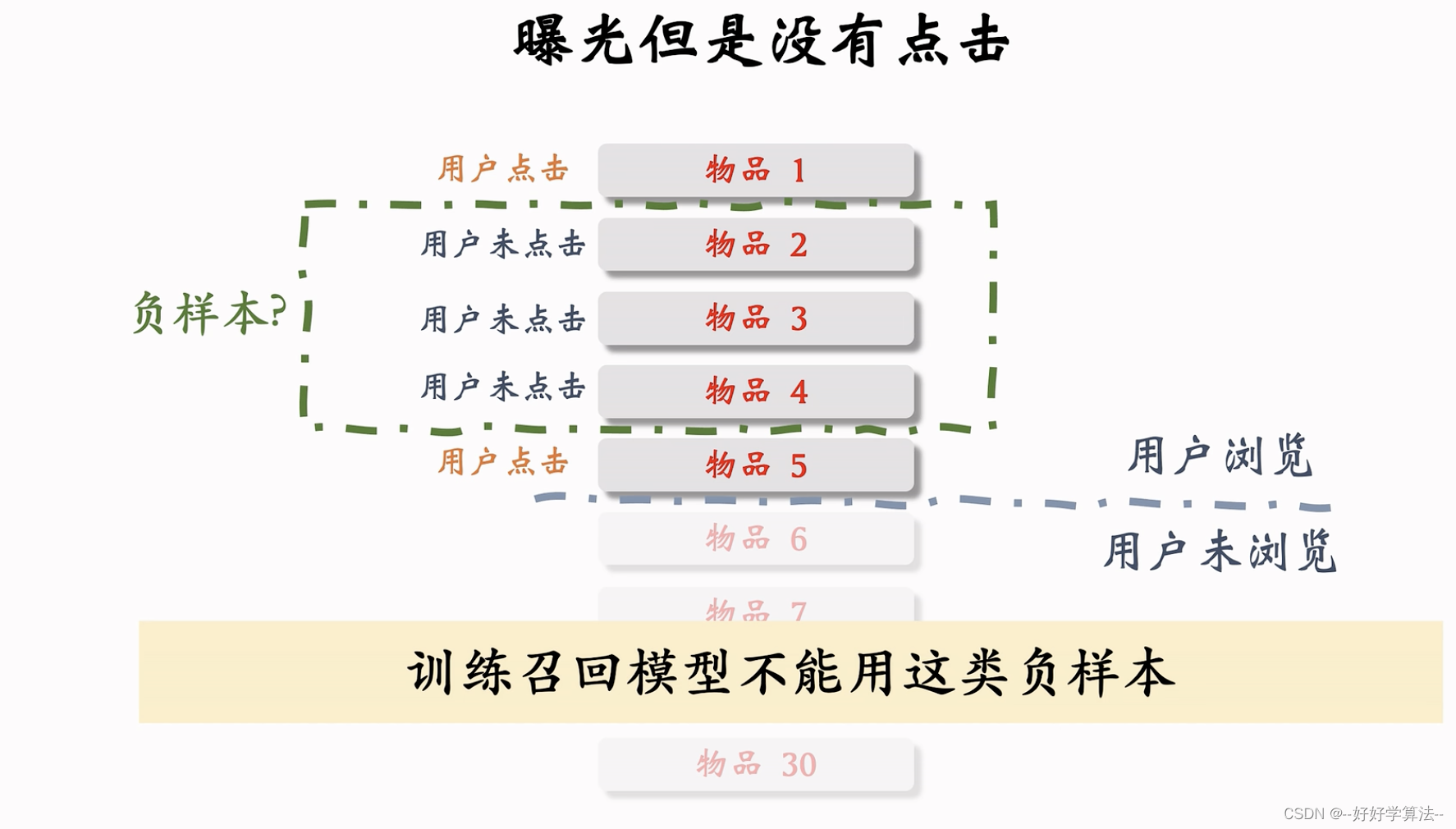
召回目的:快速找到可能感兴趣的物品
召回:区分不感兴趣和比较感兴趣,排序:区分比较感兴趣和非常感兴趣

总结:
线上召回和更新
训练好之后就可以部署了
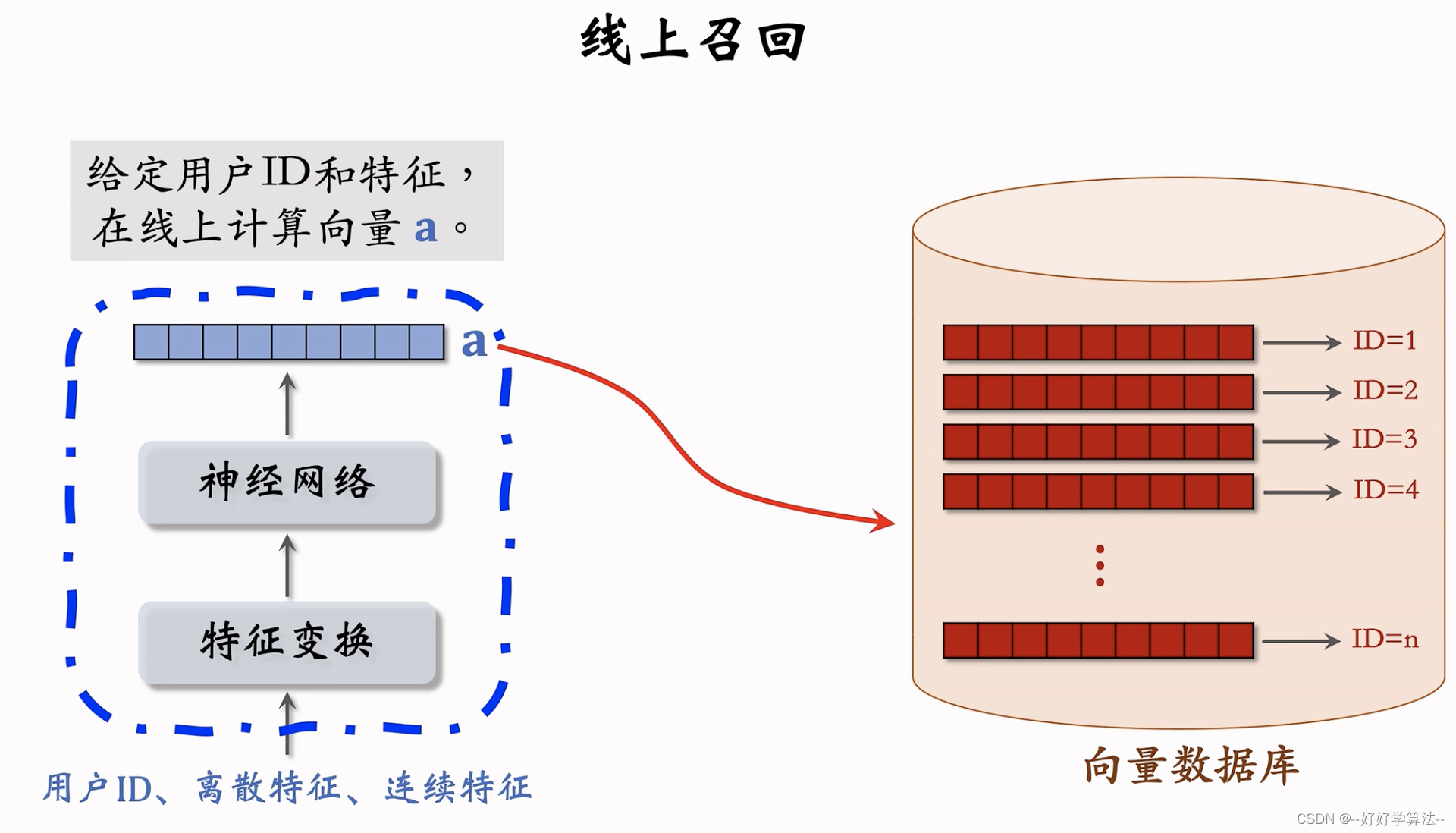
离线计算物品特征向量b,用户向量a是线上计算的,作为query,检索,k近邻召回笔记


为什么事先存b,而线上计算a?
每次召回只用一次用户向量a,计算量不大,但是几亿个物品向量计算量太大,负担大。
离线计算a,不利于推荐效果,用户兴趣点会变化,但物品特征短期稳定,不变化
模型更新
全量更新:每天凌晨用昨天的数据训练,在前一天的参数基础上训练

增量更新:
online更新,用户兴趣随时会变化,产生新的兴趣点

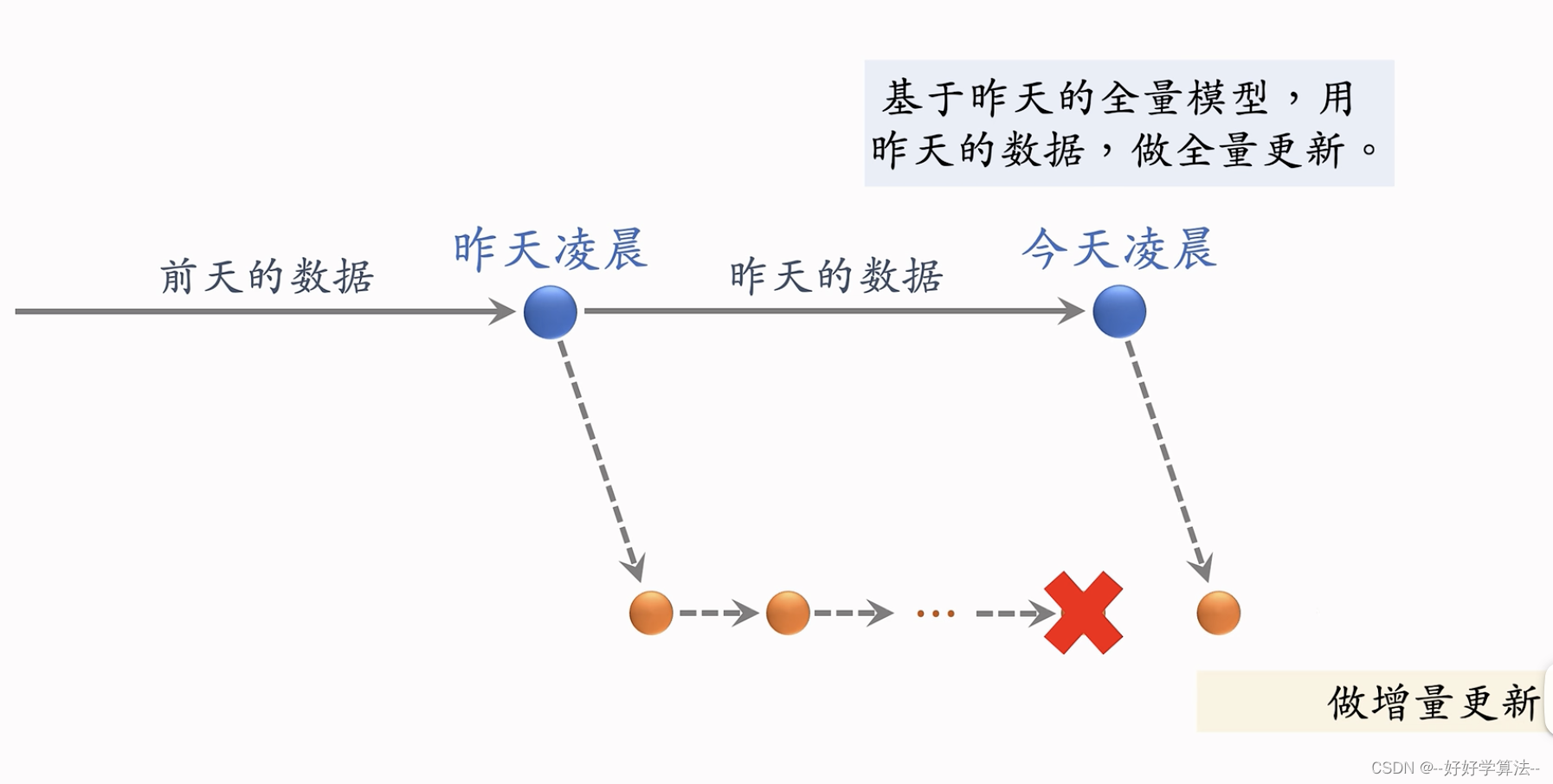
问题:能不能只做增量不做全量?

全量效果更好

















 4061
4061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









