







1.python常见的开源库介绍
1.1numpy
一个运行速度非常快的数学库,主要用于数组计算
1.2pandas
一个强大的“分析结构化数据”的工具集,底层依赖numpy
用于数据挖掘和数据分析,同时也提供数据清洗功能
pandas主要有两种数据结构:Series和Dataframe
Series 类似于一维数组,主要用于表示某行或者某列
Dataframe是pandas中一种表格型的数据结构
1.3Matplotlib
一个功能强大的数据可视化开源工具
python中使用最多的图形绘图库
1.4Seaborn
一个python数据可视化开源库,建立在Matplotlib之上
1.5Sklearn
基于python语言的机器学习工具,主要用于数据挖掘和数据分析
1.6 Jupyter Notebook
是进行数据分析学习和开发的首选开发环境
2.Numpy
2.1概述
numpy是python数据分析必不可少的第三方库
2.2Ndarray
numpy的数组类被称为ndarray,通常被称作数组
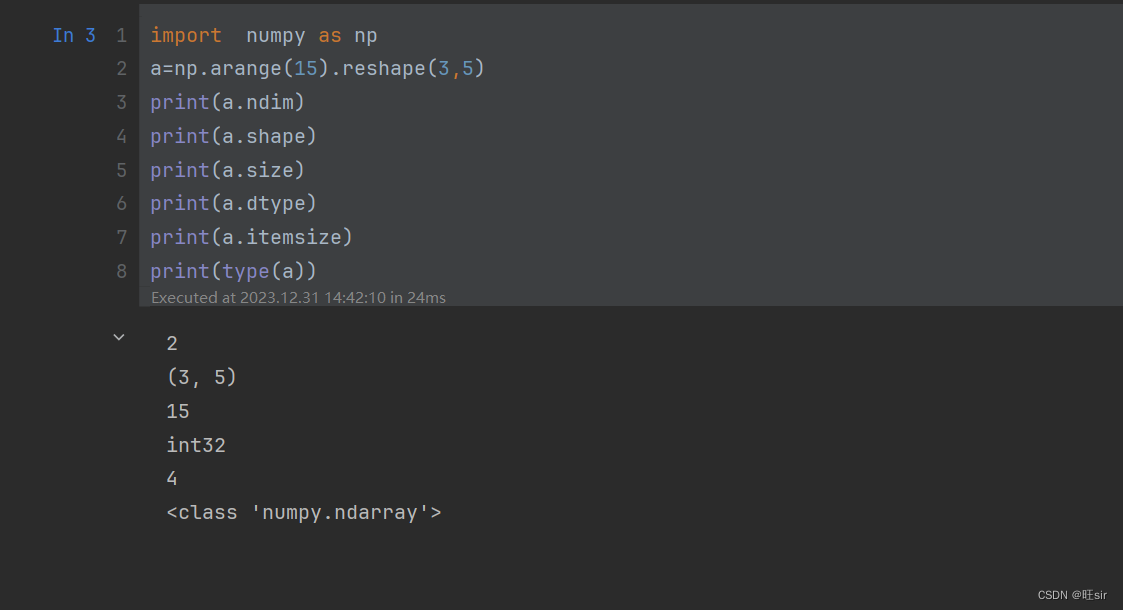
ndarray的属性有:
ndarray.ndim 数组是几维的
ndarry.shape 数组有几行几列
ndarray.size 数组中的元素个数
ndarray.dtype 数组中的元素类型
ndarray.itemsize 数组中每个元素的字节大小
运行代码
2.3创建ndarray数组
方式1:a=np.array([1,2,3,4,5])
方式2: a=ones((2,3)) /a=zeros((2,3)) 创建全是1的数组或者全是0的数组
方式3: a=np.arange(10,20,2,dtype=int) 创建起点为10,终点为20,步长为2,数据类型为int的数组
2.4创建ndarray随机数组
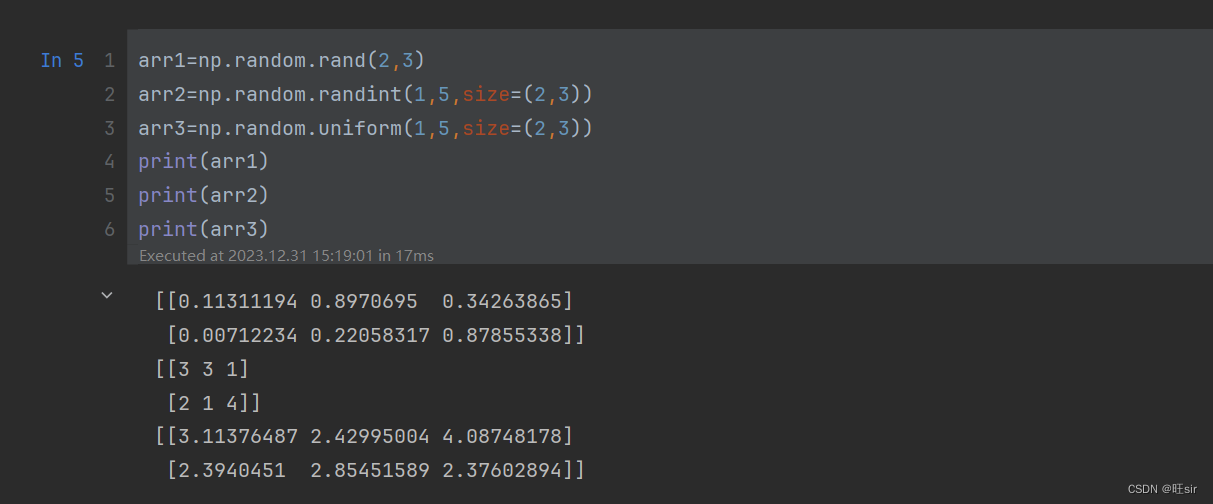
以下的范围都是包左不包右
arr1=np.random.rand(2,3) 生成一个二行三列的数组,每个元素都是从0到1的小数
arr2=np.random.randint(1,5,size=(2,3)) 生成一个二行三列的数组,每个元素都是从1到5的整数
arr3=np.random.uniform(1,5,size=(2,3)) 生成一个二行三列的数组,每个元素都是从1到5的小数
2.5matrix函数
matrix函数用于创建二维数组
arr1=np.mat('1 2;3 4')
arr2=np.matrix('1,2;3,4')
arr3=np.matrix([[1,2,3],[4,5,6]])
2.6创建等比数组
arr1=np.logspace(1,3,5) #创建从10到1000的等比数列,元素个数为5个
arr2=np.logspace(1,2,5,base=3,endpoint=True)#创建从3到9的等比数列,元素个数为5个并且包含9
2.7创建等差数列
arr1=np.linspace(1,5,3,endpoint=False) #创建从1到5的等差数组,不包含5,元素个数为3
2.8Numpy的数据类型转化
dtype 指定数据的类型
astype 转化数据的类型
arr1=np.array([1.2,1.3,1.4]ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









