






 本文介绍了如何在ClickHouse中使用ReplacingMergeTree和MergeTree引擎处理数据表的去重问题,包括针对字段多和少的情况,并提及了如何在生产环境中处理数据更新时保留最新值的方法。
本文介绍了如何在ClickHouse中使用ReplacingMergeTree和MergeTree引擎处理数据表的去重问题,包括针对字段多和少的情况,并提及了如何在生产环境中处理数据更新时保留最新值的方法。
一.数据表数据一致且翻倍
这里准备了两个测试表,表一为原表,表二为重复表
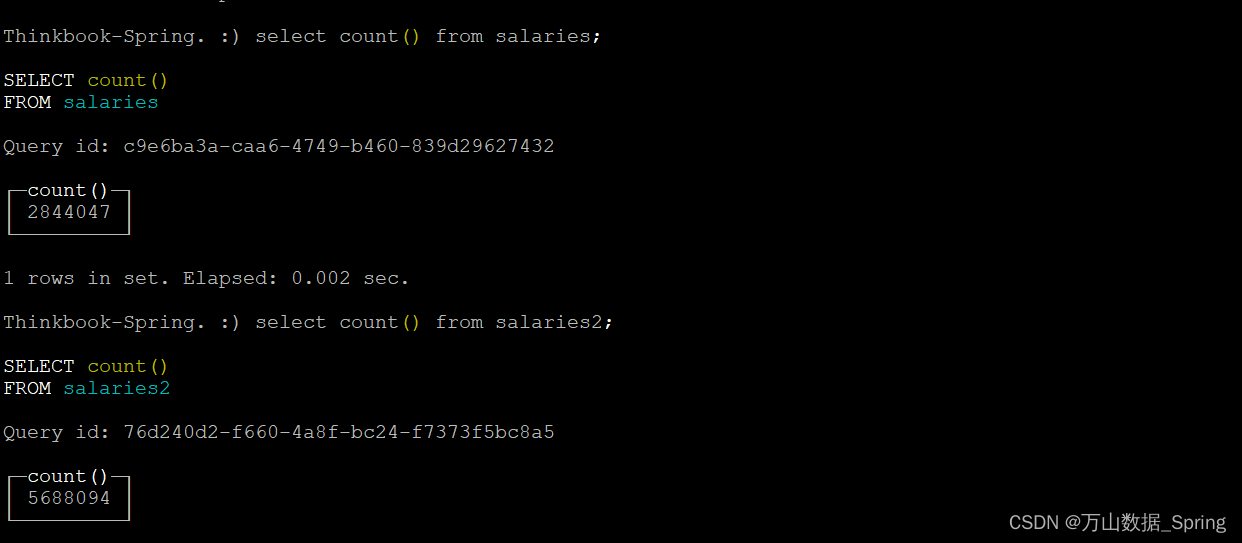
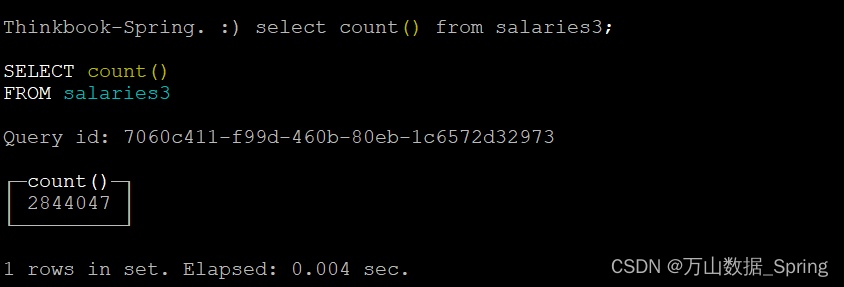
#1.ReplacingMergeTree引擎去重
CREATE TABLE salaries3
ENGINE = ReplacingMergeTree
ORDER BY (emp_no, salary, from_date, to_date) AS
SELECT *
FROM salaries2
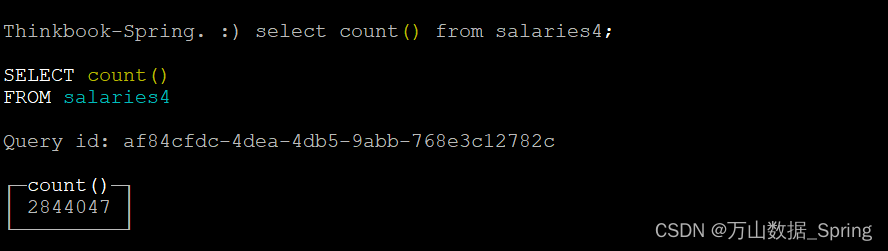
#2.聚合去重,可以适用于字段较少的表
CREATE TABLE salaries4
ENGINE = MergeTree
ORDER BY emp_no AS
SELECT
emp_no,
salary,
from_date,
to_date
FROM salaries2
GROUP BY
emp_no,
salary,
from_date,
to_date
一般生产环境的表都会有更新字段,数据更新的话,如何去掉老数据可以参考我的另一篇

















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









