






补充:
在双向链表的销毁时,普通的销毁链表传递参数是指向链表的指针:
void destroy_doulink(DLink_t *pdlink)
{
while (!is_empty_doulink(pdlink))
{
delete_doulink_head(pdlink);
}
free(pdlink);
pdlink = NULL;
}
(完整代码见二十课)
在这个代码里,我们释放链表对象空间后,给指向链表对象的指针pdlink置NULL,但此时,pdlink本身的值并没有被置NULL,此时指针也是值传递;为了改变指针本身,我们要用二级指针传递;
void destroy_doulink(DLink_t **ppdlink)
{
while (!is_empty_doulink(*ppdlink))
{
delete_doulink_head(*ppdlink);
}
free(*ppdlink);
*ppdlink = NULL;
}
在主函数调用的时候:
destroy_doulink(&pdlink);
记得传递指针的地址;
此处再补充一下二级指针:
二级指针:
1. 在被调函数中,想要修改主调函数中的指针变量,需要传递该指针变量的地址,形参用二级指针接收。
2.指针数组的数组名是一个二级指针,指针数组的数组名作为参数传递时,可用二级指针接收。
内核链表
内核链表是一个双向循环链表,但是它不再将数据存储在链表节点中,而是将结点嵌入到存储的数据中。
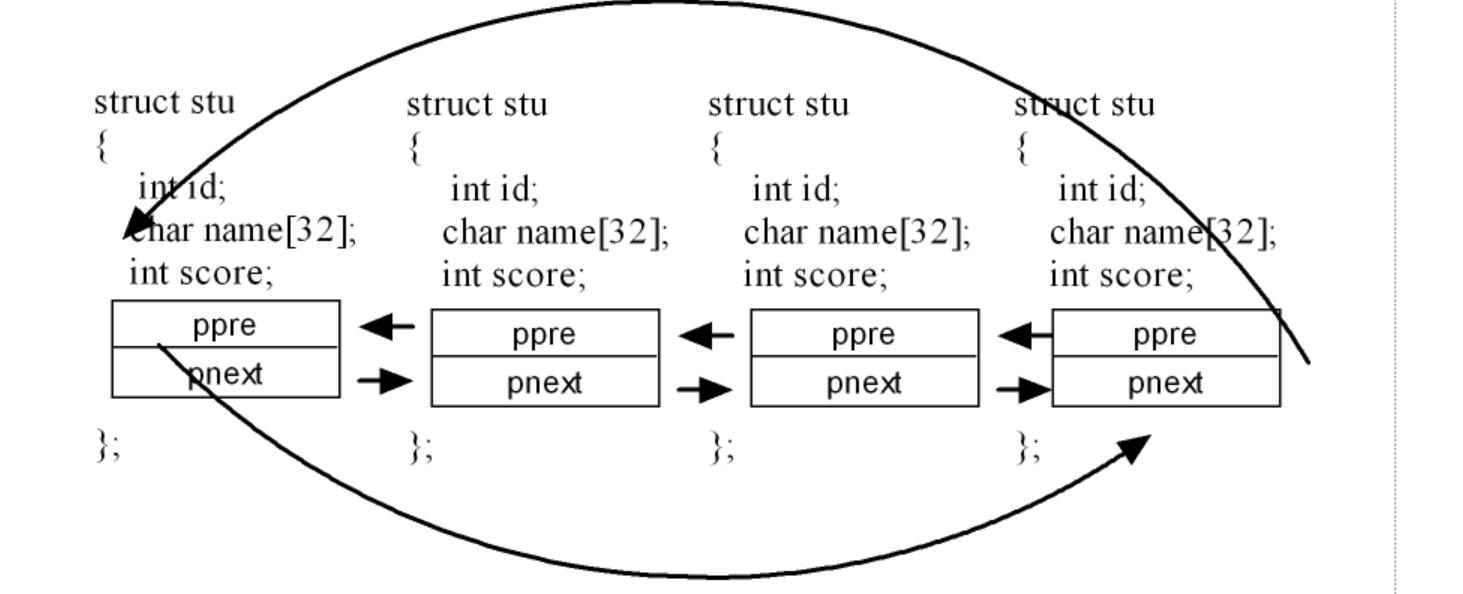
这个数据结构在使用的时候,要定义两个宏,分别是offset_of 和 container_of
offset_of : 获取内核链表中链表结点到结构体起始位置的偏移量。
container_of:通过偏移量,获取结构体的首地址(结点首地址-偏移量)。
在使用时,通过两个宏就可以进行使用这个链表;
此处只做了解即可。
栈结构
系统栈
在讲解数据结构之前,我们先回顾一下之前的内容:
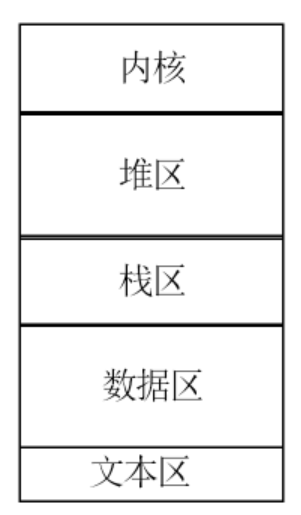
系统内存分为以上五个区,在主调函数调用函数时,在栈区依次存放返回地址,以便在调用函数结束后还能回到原函数继续运行接下来的代码。
故函数根据返回地址,返回原函数时,也要依次从栈顶取出地址返回;
通过以上回顾,栈区的一大特点就是先进后出。
数据结构栈
根据以上讲解,举一反三,栈结构即是只允许从一端进行数据的插入和删除的线性存储结构,它的特点也是先进后出(FILO(first in last out))。
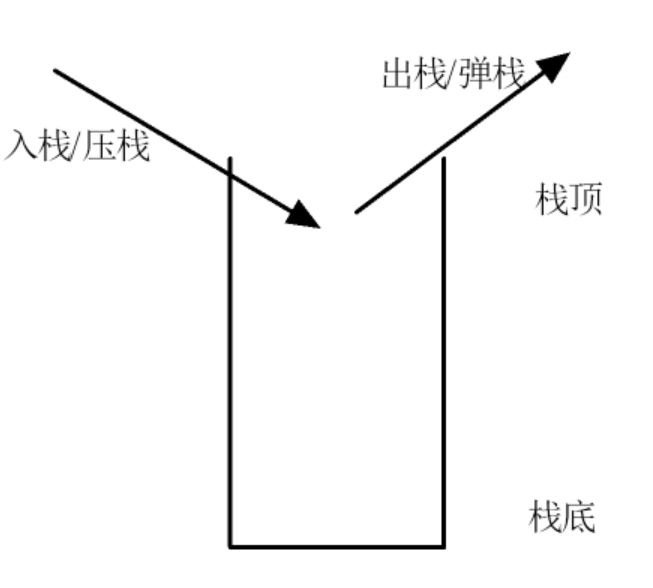
顺序栈【顺序表(数组)】
顺序栈即是以数组形式入栈的数据结构,内存是连续的。
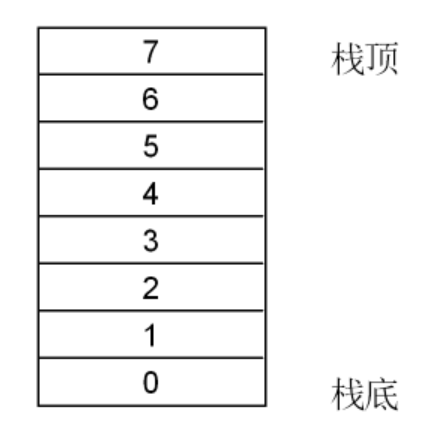
顺序栈分为四种:
1.满增栈;2.满减栈;3.空增栈;4.空减栈
实际上,区分的标准只有两条:
满栈、空栈:栈顶所在位置是否存在数据
增栈、减栈:按照栈的生长方向区分
满栈与空栈
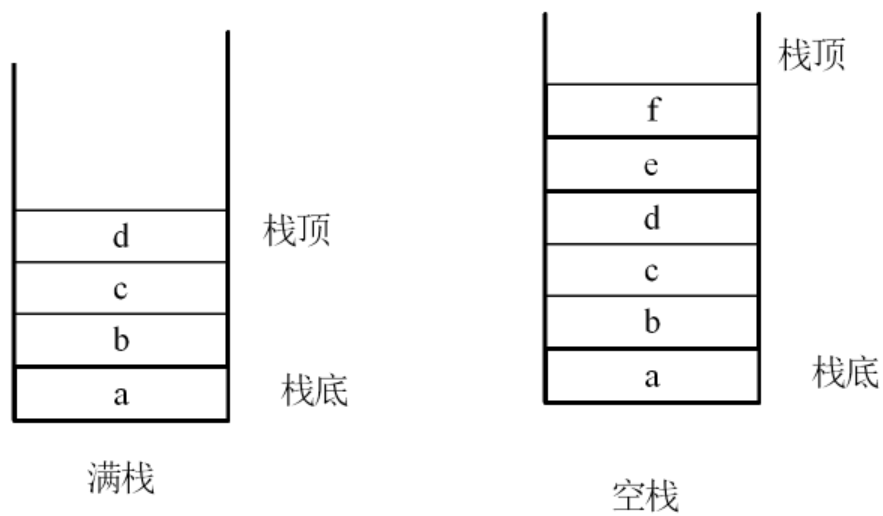
如图:满栈的栈顶指向栈上最后存放的数据,而空栈的栈顶指向栈上最后存放的数据的后一位;这个性质也导致二者不同的入栈、出栈方式(数据存储和移除都要靠栈顶的指针指向位置):
入栈:
满栈:先移栈顶,再入栈;
空栈:先入栈,再移栈顶;
出栈:
满栈:先出栈,再移栈顶
空栈:先移栈顶,再出栈
增栈与减栈
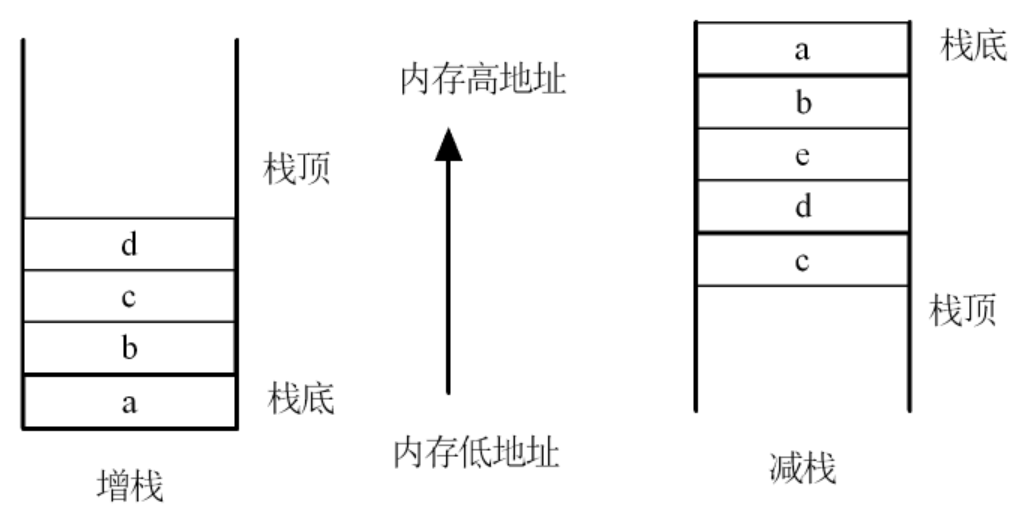
增栈与减栈实际上就是入栈的位置不同:增栈是从低地址存向高地址;减栈是由高地址存向低地址。
同上,不同的存放方式也造就了出栈和入栈方式的不同:
入栈:
增栈:栈顶从低内存向高内存移
减栈:栈顶从高内存向低内存移
出栈:
增栈:栈顶从高内存向低内存移
减栈:栈顶从低内存向高内存移
链式栈
链式栈和单向链表类似,但是它只可以从头进行出栈(删除结点),从头进行入栈(添加结点)(栈结构的先进后出特点)
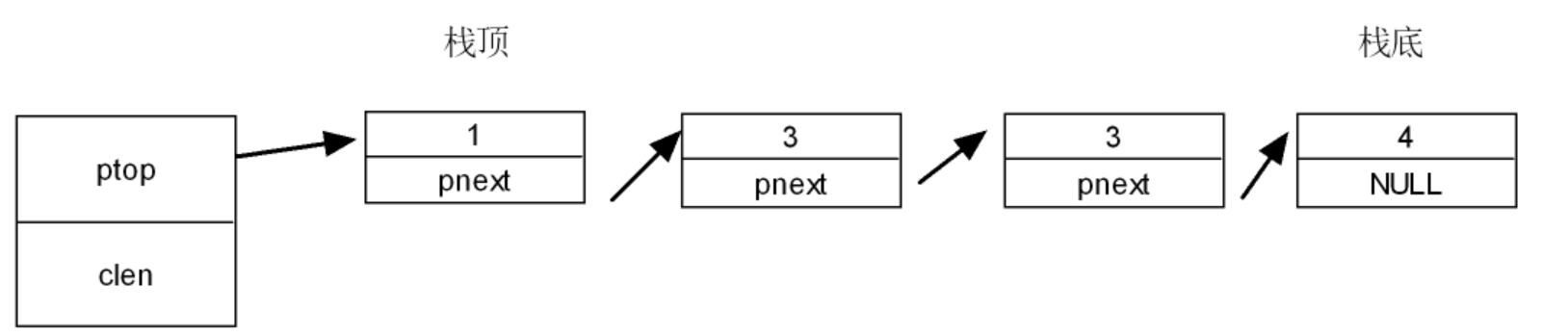
故我们在创建链式栈的时候,需要注意入栈和出栈的操作:
1.创建链式栈
先声明结构体:
#ifndef __STACK_H__
#define __SATCK_H__
typedef int Data_type_t;
typedef struct stnode
{
Data_type_t data;
struct stnode *pnext;
}STNode_t;
typedef struct stack
{
STNode_t *ptop;
int clen;
}Stack_t;
#endif
在函数体编写创建函数:
#include "stack.h"
#include <stdio.h>
#include <stdlib.h>
Stack_t *create_stack()
{
Stack_t *pstack = malloc(sizeof(Stack_t));
if (NULL == pstack)
{
printf("malloc error\n");
return NULL;
}
pstack->ptop = NULL;
pstack->clen = 0;
return pstack;
}
和单向链表的创建基本一致,故此处不再过多赘述;
2.入栈
int push_stack(Stack_t *pstack, Data_type_t data)
{
STNode_t *pnode = malloc(sizeof(STNode_t));
if (NULL == pnode)
{
printf("malloc error\n");
return -1;
}
pnode->data = data;
pnode->pnext = NULL;
pnode->pnext = pstack->ptop;
pstack->ptop = pnode;
return 0;
}
不论链式栈此时是否为一个空栈,我们都可以直接进行头插;
3.出栈
int pop_stack(Stack_t *pstack, Data_type_t *pdata)
{
if (is_empty_stack(pstack))
{
return -1;
}
STNode_t *pdel = pstack->ptop;
pstack->ptop = pdel->pnext;
if (pdata != NULL)
{
*pdata = pdel->data;
}
free(pdel);
pstack->clen--;
return 0;
}
在编写函数的时候注意,要设计一个Data_type_t的形参用来传输出栈的数据;返回值用来判断是否出栈成功
4.获取栈顶的元素
int is_empty_stack(Stack_t *pstack)
{
return NULL == pstack->ptop;
}
int get_top_stack(Stack_t *pstack, Data_type_t *pdata)
{
if (is_empty_stack(pstack))
{
return -1;
}
if (NULL == pdata)
{
return -1;
}
*pdata = pstack->ptop->data;
return 0;
}
同样的:设计形参pdata用来保存栈顶数据的空间地址;返回值用来判断是否存在栈顶元素
5.销毁栈
void destroy_stack(Stack_t **ppstack)
{
while (!is_empty_stack(*ppstack))
{
pop_stack(*ppstack, NULL);
}
free(*ppstack);
*ppstack = NULL;
}
6.遍历栈
void stack_for_eack(Stack_t *pstack)
{
STNode_t *ptmp = pstack->ptop;
while (ptmp)
{
printf("%d ", ptmp->data);
ptmp = ptmp->pnext;
}
printf("\n");
}
栈的应用
栈可以在应用程序需要撤销和前进的时候使用:
栈也可以在递归的时候使用;
队列
队列就是允许从一端进行数据的插入,另一端进行数据删除的线性存储结构,也称为队列结构:
插入操作:也叫入队操作,插入的这端称为队列的队尾;
删除操作:也叫出队操作,删除的这端称为队列的队头。

它的特点是先进先出(FIFO(first in first out))
通常,这个数据结构会在缓冲区使用;
缓冲区:高速设备将数据传向低速设备的中间区域;
顺序队列
通过顺序表实现的队列就是顺序队列,顾名思义是由数组组成的:
入队时:
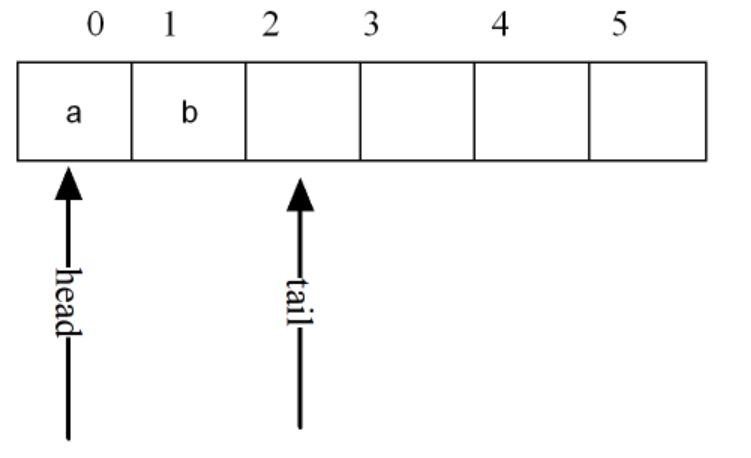
指针tail指向下一个要入队的地址,指针head永远指向队头的位置;
出队时:
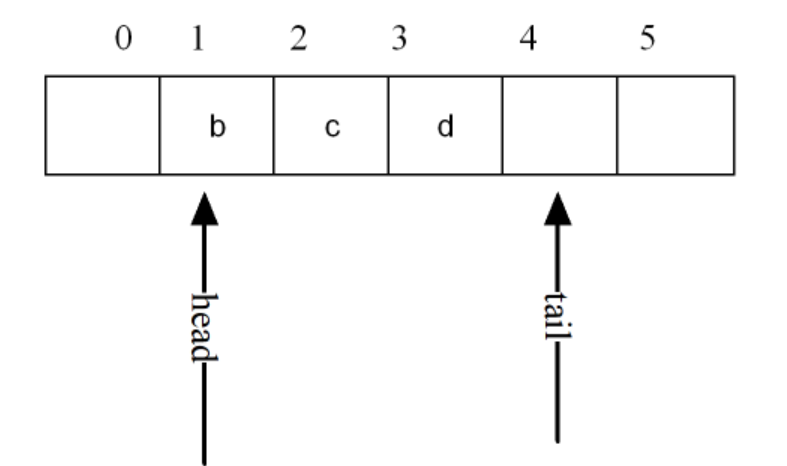
在出队时,指针head向后指向此时的队头;
基于这种情况,当队列开始陆续有数据入队出队的话:
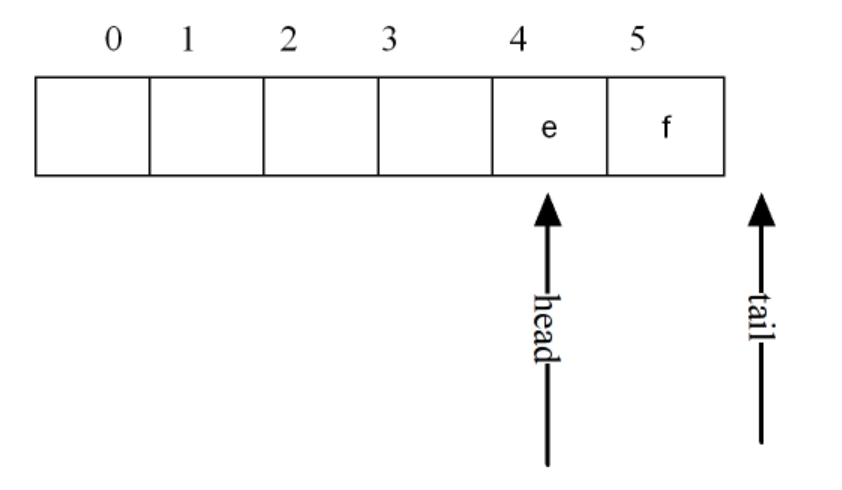
此时,tail指针指向NULL,会误导用户认为此时队列已满,但实际上这个队列还有很多空位,我们称这种情况叫“假溢出”。
为了防止这种情况,我们使用循环队列:
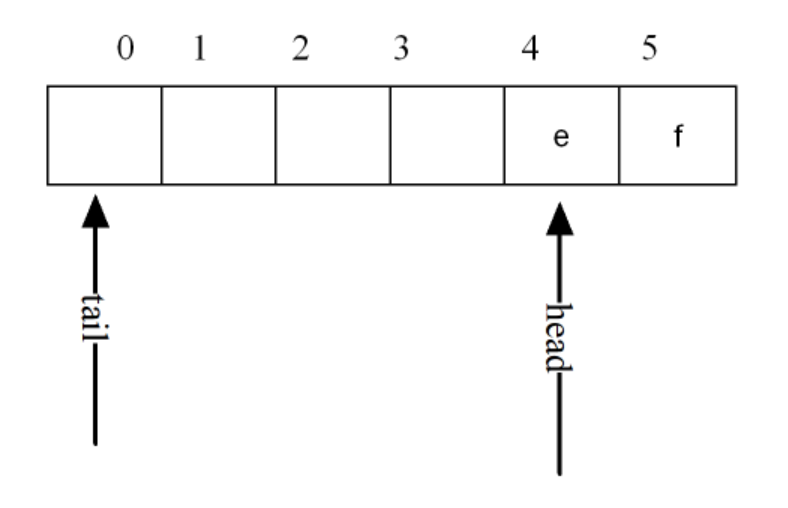
这样的话指针tail不为空,就可以继续入队了;
可是我们应该如果判断循环队列是否为空、是否为满呢?
循环顺序队列的空满判定
很多同学可能会想,当tail 和 head指向同一个位置不就为空吗?
但如果出现这种情况呢?
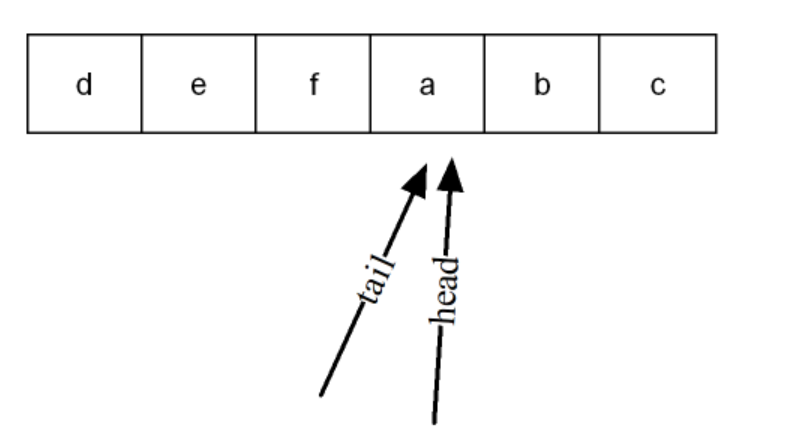
此时为了正确判断这两种情况,我们在队列里牺牲一个空间(少存一个数据),来对tail和head的位置进行判断:
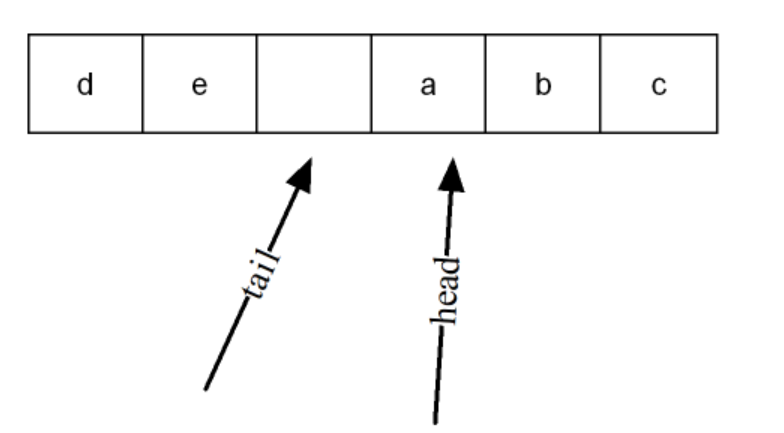
如果tail + 1 == head,那此时队列已满;
同样的,如果tail == head,此时队列为空;
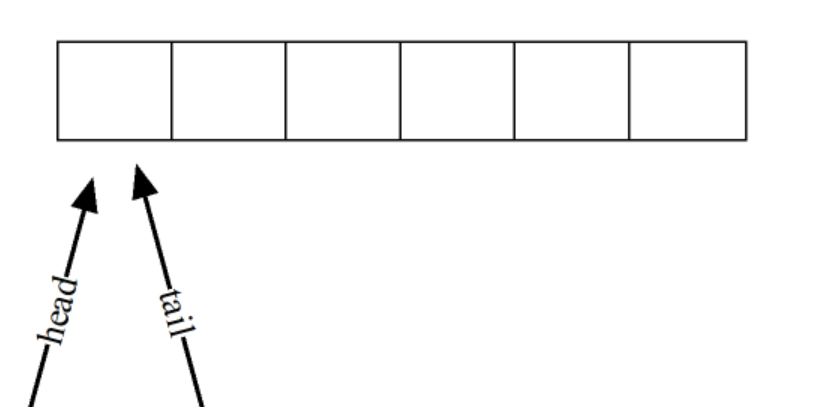
越界问题
为了避免head和tail在移动时超过队列的位置,使用:
(head+1)%len
(tail+1)%len
# len 指的是顺序表(数组)的长度
顺序队列的程序结构
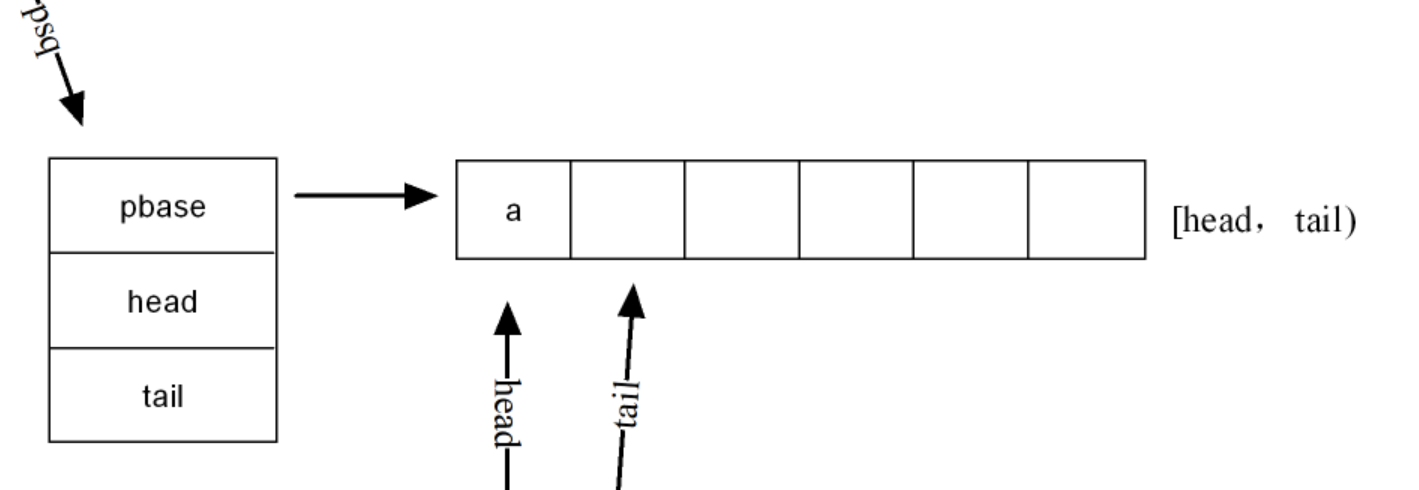
队列对象phase指向整个数组;
创建队列:
声明结构体:
#ifndef __SEQQUE_H__
#define __SEQQUE_H__
#define SEQQUE_MAX_LEN 10
typedef int Data_type_t;
typedef struct seqque
{
Data_type_t *pbase;
int head;
int tail;
}Seqque_t;
#endif
在宏定义数组长度;
编写函数:
#include "seqque.h"
#include <stdio.h>
Seqque_t *create_seqque()
{
Seqque_t *psq = malloc(sizeof(Seqque_t));
if (NULL == psq)
{
printf("malloc error\n");
return NULL;
}
psq->head = 0;
psq->tail = 0;
psq->pbase = malloc(sizeof(Data_type_t) * SEQQUE_MAX_LEN);
if (NULL == psq->pbase)
{
printf("malloc error\n");
return NULL;
}
return psq;
}
判断空队和满队
int is_full_seqque(Seqque_t *psq)
{
if ((psq->tail+1)%SEQQUE_MAX_LEN == psq->head)
{
return 1;
}
return 0;
}
int is_empty_seqque(Seqque_t *psq)
{
if (psq->head == psq->tail)
{
return 1;
}
return 0;
}
入队
int push_seqque(Seqque_t *psq, Data_type_t data)
{
if (is_full_seqque(psq))
{
printf("seqque is full\n");
return -1;
}
psq->pbase[psq->tail] = data;
psq->tail = (psq->tail+1) % SEQQUE_MAX_LEN;
return 0;
}
出队
int push_seqque(Seqque_t *psq, Data_type_t data)
{
if (is_full_seqque(psq))
{
printf("seqque is full\n");
return -1;
}
psq->pbase[psq->tail] = data;
psq->tail = (psq->tail+1) % SEQQUE_MAX_LEN;
return 0;
}
遍历
void seqque_for_each(Seqque_t *psq)
{
for (int i = psq->head; i < psq->tail; i = (i+1)%SEQQUE_MAX_LEN)
{
printf("%d ", psq->pbase[i]);
}
printf("\n");
}
链式对立
由链式表实现的队列成为链式队列;
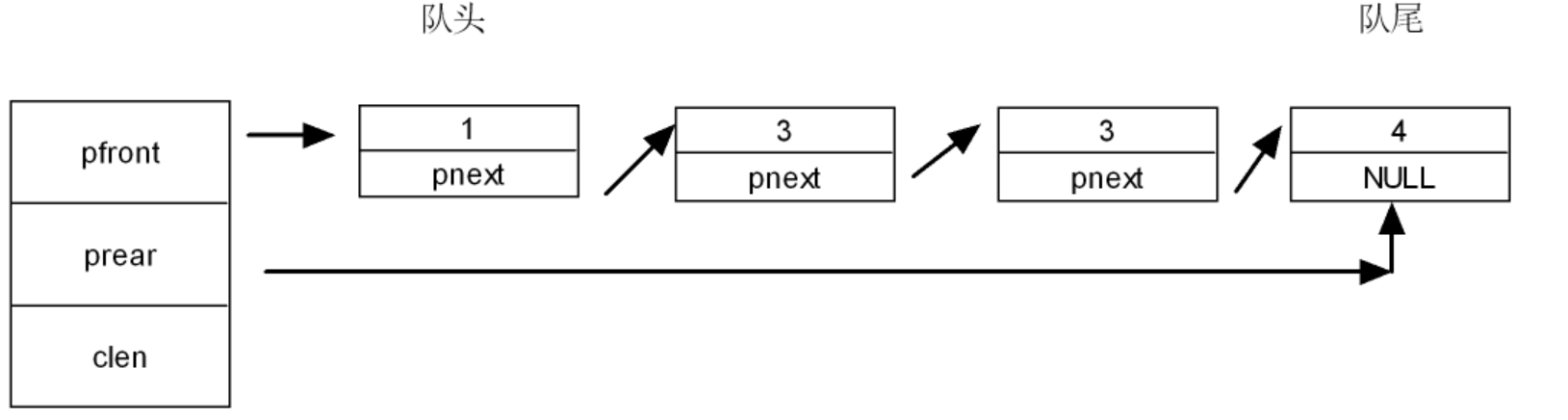
和单向链表类似,不过入队只能从队尾进入(尾插),出队只能从队头出(头删);
具体应用因篇幅原因不再过多赘述,同学可以尝试自己编写一下,具体的应用如下,在二十二课会进行更新(8.7)
1. 创建链式队列
2. 入队操作(尾插)
3. 出队操作(头删)
4. 判空
5. 获取队头元素
6. 销毁队列
7. 遍历队列
以上就是今天和大家分享的所有内容!!!!感谢你的阅读!!!如果有疑问和错漏欢迎评论区评论哦!!!!!

















 38
38

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









