






 文章介绍了两种处理数据库中ID重复的方法:一是通过IN操作符结合MAX函数选取每个ID的最新记录;二是使用窗口函数ROW_NUMBER配合PARTITIONBY和ORDERBY获取每个ID的最新更新。这两种方法都能确保保留每个ID的最新数据。
文章介绍了两种处理数据库中ID重复的方法:一是通过IN操作符结合MAX函数选取每个ID的最新记录;二是使用窗口函数ROW_NUMBER配合PARTITIONBY和ORDERBY获取每个ID的最新更新。这两种方法都能确保保留每个ID的最新数据。
当数据入库时,可能存在ID重复的情况,可能时明细层去重不彻底,或者时进行数据治理时,join时产生重复数据,我需要对这些ID进行去重,并保证最后进入实体表的数据时是不重复的
1.使用in配合max取时间
- 先使用测试数据生成一张表测试
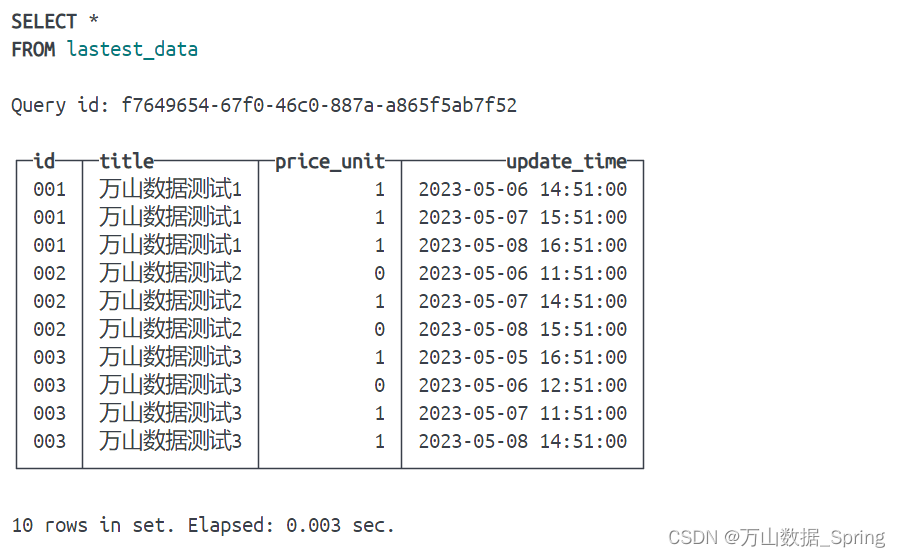
- 使用更新时间确定时间是最新的在对id进行分组,使用id和更新时间同时满足id和最大时间取出最新数据
SELECT *
FROM lastest_data
WHERE (id, update_time) IN (
SELECT
id,
max(update_time)
FROM lastest_data
GROUP BY id
)
Query id: 0671f361-c099-4032-9c15-8db0391c93b8
┌─id──┬─title─────────┬─price_unit─┬─────────update_time─┐
│ 001 │ 万山数据测试1 │ 1 │ 2023-05-08 16:51:00 │
│ 002 │ 万山数据测试2 │ 0 │ 2023-05-08 15:51:00 │
│ 003 │ 万山数据测试3 │ 1 │ 2023-05-08 14:51:00 │
└─────┴───────────────┴────────────┴─────────────────────┘
2.使用开窗函数
- 我之前使用过开窗函数做id去重,但考虑到性能的问题,后期会使用in来代替开窗
SELECT t.*
FROM
(
SELECT
*,
row_number() OVER (PARTITION BY id ORDER BY update_time DESC) AS ss
FROM default.lastest_data
) AS t
WHERE ss = 1
Query id: 55b784e3-8c36-499e-a382-aa460ae9e1db
┌─id──┬─title─────────┬─price_unit─┬─────────update_time─┬─ss─┐
│ 001 │ 万山数据测试1 │ 1 │ 2023-05-08 16:51:00 │ 1 │
│ 002 │ 万山数据测试2 │ 0 │ 2023-05-08 15:51:00 │ 1 │
│ 003 │ 万山数据测试3 │ 1 │ 2023-05-08 14:51:00 │ 1 │
└─────┴───────────────┴────────────┴─────────────────────┴────┘
- 可以看到使用开窗和in的效果是一样的
- 这是一个简单的去重小技巧,去重需要满足ID是主键,并且有更新时间字段,当然有别的时间字段做参考也是可以的

















 3324
3324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









