






参考文章:https://blog.youkuaiyun.com/weixin_37354464/article/details/115551763?spm=1001.2014.3001.5502
卫星定位系统在室内环境或高层建筑密集地区无法检测到卫星信号,无法满足人们对于定位精度的要求。Wi-Fi通信模块在移动终端上的广泛应用,使得WIFI无线定位转变成一种低成本和已于实现的技术。
1. 数据预处理
数据集信息
trainingData2.csv 结构
| WAP001~ WAP520 | 无线应用协议 |
|---|---|
| LONGITUDE | 经度 |
| LATITUDE | 纬度 |
| FLOOR | 楼层 |
| BUILDINGID | 建筑标识 |
| SPACEID | 空间ID |
| RELATIVEPOSITION | 相对位置 |
| USERID | 用户ID |
| PHONEID | 手机号码 |
| TIMESTAMP | 时间戳 |
导入需要的包
import argparse #命令行选项、参数和子命令解释器;编写用户友好的命令行接口,程序定义它需要的参数,可以清晰sys.argv解析的参数;会自动生成帮助和使用手册,并在用户在程序传入无效参数时报出错误信息
import datetime #处理时间型数据
import os #在python环境下对文件,文件夹执行操作的一个模块
import math #提供了对浮点数的数学运算函数,返回值均为浮点数,除非另有明确说明
import numpy as np #数据计算库
import pandas as pd #数据分析包
import sys #包含了与python解释器和它环境有关的函数
from sklearn.preprocessing import scale #sklearn.preprocessing提供几种常用的效用函数及转换器类,用于更改原始特征向量表示形式 将给定数据进行标准化
from timeit import default_timer as timer #测试代码的运行时间
定义训练集和验证集,输出路径
path_train = 'G:/PycharmProjects/indoor_localization/data/UJIIndoorLoc/trainingData2.csv' # '-110' for the lack of AP.
path_validation = 'G:/PycharmProjects/indoor_localization/data/UJIIndoorLoc/validationData2.csv' # ditto
path_base = 'G:/PycharmProjects/indoor_localization/my_model/'
path_out = path_base + 'out'
path_sae_model = path_base + 'sae_model.hdf5'
读取数据集
train_df = pd.read_csv(path_train, header=0) # pass header=0 to be able to replace existing names(path_train为训练集路径,header=0,读取表头数据)
test_df = pd.read_csv(path_validation, header=0)
print(train_df)
print(test_df)
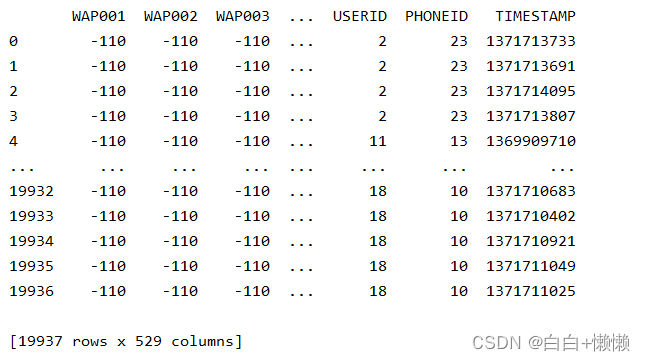

数据集trainingData2.csv 中共包括 529 个属性,19937 行数据。
| WAP001~ WAP520 | 无线接入点(WAP) | (RSSI范围)-104dBm~0dBm |
|---|---|---|
| LONGITUDE | 经度 | -7695.9388 ~ -7299.7865 |
| LATITUDE | 纬度 | 4864745.7450 ~ 4865017.3647 |
| FLOOR | 建筑物内楼层的高度 | 0 ~ 4 |
| BUILDINGID | 三栋楼 | 0~2 |
| SPACEID | 用于识别位置空间(办公室、走廊、教室)的内部ID | |
| RELATIVEPOSITION | 相对于位置空间的相对位置 | 1-门内 2-门外 |
| USERID | 用户ID | |
| PHONEID | 手机号码 | |
| TIMESTAMP | 时间戳 |
在本实验中,为了方便以后的归一化,使用负值-110表示未检测到WAP。实验中使用520个WiFi指纹、LONGITUDE 、LATITUDE、FLOOR、BUILDINGID、SPACEID、RELATIVEPOSITION共 526 个属性。
预处理数据
# convert integer to float and scale jointly (axis=1)
train_AP_features = scale(np.asarray(train_df.iloc[:,0:520]).astype(float), axis=1) #iloc[:,0:520]).astype(float)提取全部的行,0~520列的数据,并将整数型转化为浮点型数据,axis=1代表行
# add a new column(增加新的一列)
train_df['REFPOINT'] = train_df.apply(lambda row: str(int(row['SPACEID'])) + str(int(row['RELATIVEPOSITION'])), axis=1) #REFPOINT参考资料 SPACEID空间id RELATIVEPOSITION相对位置
blds = np.unique(train_df[['BUILDINGID']]) #BUILDINGID建筑标识 对于一维数组或列表,unique函数去除其中重复的元素,并按照元素由大到小返回一个无元素重复的元组或列表
flrs = np.unique(train_df[['FLOOR']])
print('train_AP_features')
print(train_AP_features)
print('train_df_REFPOINT')
print(train_df['REFPOINT'])
print('blds')
print(blds)
print('flrs')
print(flrs)
train_AP_features:取出样本中520个WiFi指纹,使用scale函数进行预处理,将其转换成float类型的数组。对每一行的数据进行标准化的处理。
**train_df[‘REFPOINT’]:**添加的新列,spaceID和relativepolisition的组合。因为后面需要对楼层的参考点进行编号,REFPOINT在一个楼层中将出现不同的参考点(SpaceID,RelativePosition)

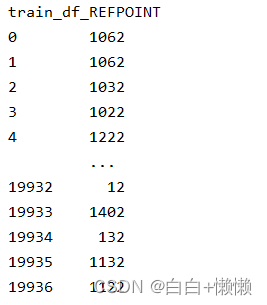

通过查看bldr,flrs可知数据集中一共有三栋楼、五个楼层。
映射参考点
x_avg = {}
y_avg = {}
for bld in blds:
for flr in flrs:
# map reference points to sequential IDs per building-floor before building labels(在建筑标签之前,将参考点映射到每个建筑物楼层的顺序ID)
cond = (train_df['BUILDINGID']==bld) & (train_df['FLOOR']==flr) #cond代表当前选择的楼层
_, idx = np.unique(train_df.loc[cond, 'REFPOINT'], return_inverse=True) # return_inverse=True返回旧列表元素在新列表中的位置,并以列表形式存储在idx中
train_df.loc[cond, 'REFPOINT'] = idx #选取当前楼层的所有参考点的值,此时得到的idx代表的就是该楼层每一个参考点编号的id值
# calculate the average coordinates of each building/floor (计算每个建筑物/楼层的平均坐标)
x_avg[str(bld) + '-' + str(flr)] = np.mean(train_df.loc[cond, 'LONGITUDE']) #LONGITUDE经度
y_avg[str(bld) + '-' + str(flr)] = np.mean(train_df.loc[cond, 'LATITUDE']) #LATITUDE纬度
print("_")
print(_)
print("idx")
print(idx)
print("x_avg")
print(x_avg)
print("y_avg")
print(y_avg)
将参考点映射到每个楼层,用到了前面的REFPOINT,每个楼层的不同参考点用不同的id进行标记。计算各楼层的平均坐标,后面进行使用。cond是当前选择的楼层。train_df.loc[cond, ‘LONGITUDE’]是当前选择楼层的所有参考点的值,此时的到的idx代表的就是该楼层每一个参考点的id值。



多分类构建标签
len_train = len(train_df)
# for consistency in one-hot encoding for both dataframes(确保两个数据帧的独热编码一致性)
blds_all = np.asarray(pd.get_dummies(pd.concat([train_df['BUILDINGID'], test_df['BUILDINGID']])))
flrs_all = np.asarray(pd.get_dummies(pd.concat([train_df['FLOOR'], test_df['FLOOR']]))) # ditto(同上)
blds = blds_all[:len_train]
flrs = flrs_all[:len_train]
rfps = np.asarray(pd.get_dummies(train_df['REFPOINT'])) #get_dummies实现独热编码的函数
train_labels = np.concatenate((blds, flrs, rfps), axis=1) #将两个或者多个文本字符串联成一个字符串
"""
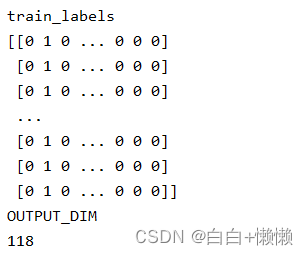
# labels is an array of 19937 x 118 标签是199937*118的数组
# - 3 for BUILDINGID
# - 5 for FLOOR,
# - 110 for REFPOINT
"""
OUTPUT_DIM = train_labels.shape[1] #输入数据的维度,这一行数据是有多少个元素组成的
对于每一组数据,一共有520个WiFi指纹数据,对应的标签就是建筑、楼层、参考点三个id,将三个标签转换成一个标签(独热编码)使用pd.get_dummies得到相应的独热编码,将三个id合并成118位的label。
| 前三位 | 五位 | 110位 |
|---|---|---|
| 建筑 | 楼层 | 参考点 |
划分训练集和测试集
train_val_split = np.random.rand(len(train_AP_features)) < training_ratio #np.random.rand返回一个或一组服从“0-1”均匀分布的随机样本值,随机样本取值范围是[0,1]
x_train = train_AP_features[train_val_split] #输出是(17955,520)
y_train = train_labels[train_val_split] #输出是(17955,118)
x_val = train_AP_features[~train_val_split] #输出是(1982,520)
y_val = train_labels[~train_val_split] #输出是(1982,118)
print("x_train \n", x_train)
print("y_train \n", y_train)
print("x_val \n", x_val)
print("y_val \n", y_val)
training_ratio表示训练数据与整体数据的比率,默认是0.9

验证集标准化(用于测试模型)
test_AP_features = scale(np.asarray(test_df.iloc[:,0:520]).astype(float), axis=1) # convert integer to float and scale jointly (axis=1)
x_test_utm = np.asarray(test_df['LONGITUDE'])
y_test_utm = np.asarray(test_df['LATITUDE'])
blds = blds_all[len_train:]
flrs = flrs_all[len_train:]
本次测试集使用的是数据中的验证集,对验证集中的WiFi指纹数据也需要进行相应的标准化。
数据处理完成!
| WiFi指纹大小 | 标签大小 | |
|---|---|---|
| 训练集 | (17955, 520) | (17955, 118) |
| 验证集 | (1982, 520) | (1982, 118) |
| 测试集 | (1111, 520) |
评估模型的性能时,对于预测得到的标签通过训练集转换标签的对应关系得到对应预测的建筑、楼层、参考点(可以对应经纬度坐标)与真实的相比较,评估模型的性能。
2. 模型选择
实验使用的框架是keras,使用Sequential构架模型。
定义全局变量常量
# general(常量)
INPUT_DIM = 520 # number of APs(接入点数量)
VERBOSE = 1 # 0 for turning off logging(0表示关闭日志记录)
"""
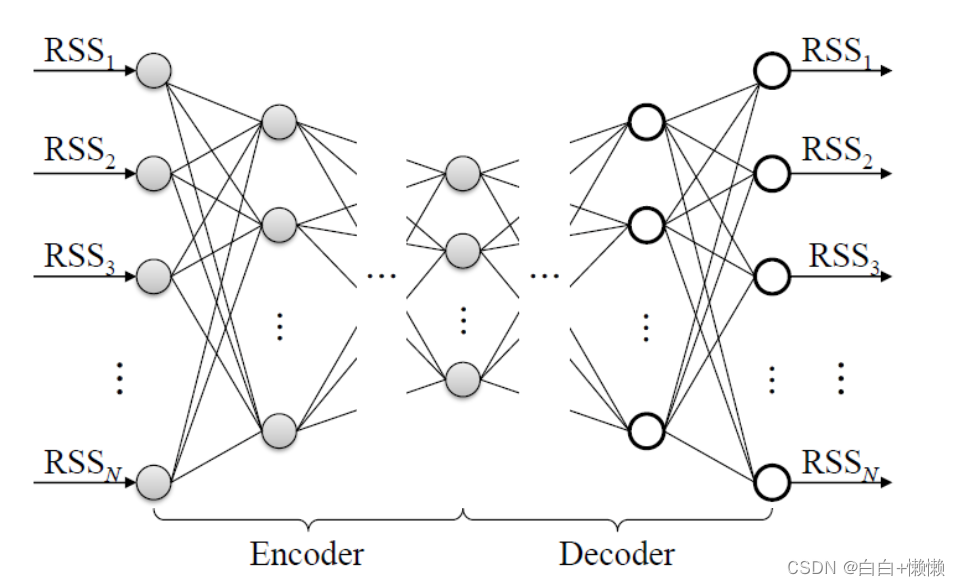
stacked auto encoder (sae)(堆叠式自动编码器)
对自编码网络一种使用方法,是一个由多层训练好的自编码器组成的神经网络
自动编码(AE)一种无监督的含有隐藏神经网络,其中输出层被设置为等于输入层,AE的目的是尽可能的准确地重建原始输入
"""
SAE_ACTIVATION = 'relu'
SAE_BIAS = False
SAE_OPTIMIZER = 'adam'
SAE_LOSS = 'mse'
"""
# classifier
"""
CLASSIFIER_ACTIVATION = 'relu' #分类激活函数为relu
CLASSIFIER_BIAS = False #分类偏差
CLASSIFIER_OPTIMIZER = 'adam' #分类优化器为adam
CLASSIFIER_LOSS = 'binary_crossentropy' #分类损失函数为binary_crossentropy
定义动态参数
if __name__ == "__main__":
parser = argparse.ArgumentParser() #创建解释器,使用argparse的第一步是创建一个ArgumentParser对象
parser.add_argument( #使用add_argument给ArgumentParser对象添加参数
"-G", #加"--"代表参数是可以选择的
"--gpu_id",
help="ID of GPU device to run this script; default is 0; set it to a negative number for CPU (i.e., no GPU)",
default=0,
type=int)
parser.add_argument(
"-R",
"--random_seed",
help="random seed",
default=0,
type=int)
parser.add_argument(
"-E",
"--epochs",
help="number of epochs; default is 20",
default=20,
type=int)
parser.add_argument(
"-B",
"--batch_size",
help="batch size; default is 10",
default=10,
type=int)
parser.add_argument(
"-T",
"--training_ratio",
help="ratio of training data to overall data: default is 0.9",
default=0.9,
type=float)
parser.add_argument(
"-S",
"--sae_hidden_layers",
help=
"comma-separated numbers of units in SAE hidden layers; default is '256,128,256'",
default='256,128,256',
type=str)
parser.add_argument(
"-C",
"--classifier_hidden_layers",
help=
"comma-separated numbers of units in classifier hidden layers; default is '64,128'",
default='64,128',
type=str)
parser.add_argument(
"-D",
"--dropout",
help=
"dropout rate before and after classifier hidden layers; default 0.2",
default=0.2,
type=float)
parser.add_argument(
"-N",
"--neighbours",
help="number of (nearest) neighbour locations to consider in positioning; default is 8",
default=8,
type=int)
parser.add_argument(
"--scaling",
help=
"scaling factor for threshold (i.e., threshold=scaling*maximum) for the inclusion of nighbour locations to consider in positioning; default is 0.2",
default=0.2,
type=float)
args = parser.parse_args() #ArgumentParser 通过 parse_args() 方法解析参数
从args动态的获取参数
gpu_id = args.gpu_id #获取gpu的id
random_seed = args.random_seed #获取随机数种子
epochs = args.epochs #数据被训练的次数
batch_size = args.batch_size #进行神经网络训练时,batch_size是一个必须设置的参数,用于提升训练效果
training_ratio = args.training_ratio #设置训练比例
sae_hidden_layers = [int(i) for i in (args.sae_hidden_layers).split(',')] #设置隐藏层,利用for循环取出值
if args.classifier_hidden_layers == '':
classifier_hidden_layers = ''
else:
classifier_hidden_layers = [int(i) for i in (args.classifier_hidden_layers).split(',')]
dropout = args.dropout #dropout是tensorflow中为了防止过拟合或减轻拟合而使用的函数
N = args.neighbours #找到距离最近的N个点
scaling = args.scaling #特征缩放,特点是不改变数据的分布情况。Normalization会改变数据的分布
构建模型
定义输入层,利用循环根据输入参数定义隐藏层,最后定义输出层。
if os.path.isfile(path_sae_model) and (os.path.getmtime(path_sae_model) > os.path.getmtime(__file__)):
model = load_model(path_sae_model)
else:
# create a model based on stacked autoencoder (SAE) 创建堆叠自动编码器创建模型
model = Sequential() #构建非常复杂的神经网络,包括全连接神经网络,卷积神经网络(CNN),循环神经网络(RNN)
#Dense是Keras定义网络层的基本方法,定义参数的值
model.add(Dense(sae_hidden_layers[0], name="sae-hidden-0", input_dim=INPUT_DIM, activation=SAE_ACTIVATION, use_bias=SAE_BIAS))
for i in range(1, len(sae_hidden_layers)):
model.add(Dense(sae_hidden_layers[i], name="sae-hidden-"+str(i), activation=SAE_ACTIVATION, use_bias=SAE_BIAS))
model.add(Dense(INPUT_DIM, name="sae-output", activation=SAE_ACTIVATION, use_bias=SAE_BIAS))
model.compile(optimizer=SAE_OPTIMIZER, loss=SAE_LOSS) #用于配置训练方法时,告知训练时使用的优化器,损失函数和准确率评测标准
使用的是全连接层,激活函数是"relu",没有偏置。
使用优化器adam和损失函数mse对模型进行编译,最后对模型进行训练。此时输入输出都是520维的WiFi指纹数据,网络也是对称的,进而达到编码的目的(SAE)。
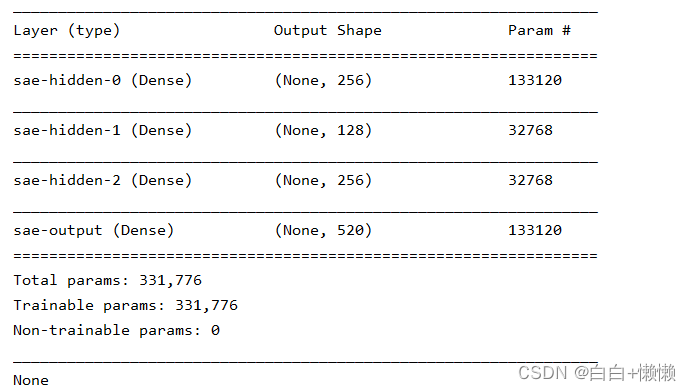
假设使用的是默认的sae_hidden_layers,可以看到模型的结构如下,可以看到feature map大小。
例如,第一层的输出为(None, 256),其中None表示运行后的大小,网络模型中需要训练和更新的参数有331776个。
训练模型
model.fit(x_train, x_train, batch_size=batch_size, epochs=epochs, verbose=VERBOSE)
训练完成后,我们需要去掉SAE的解码器部分,添加分类器来估计建筑、楼层和位置。
在这里插入图片描述
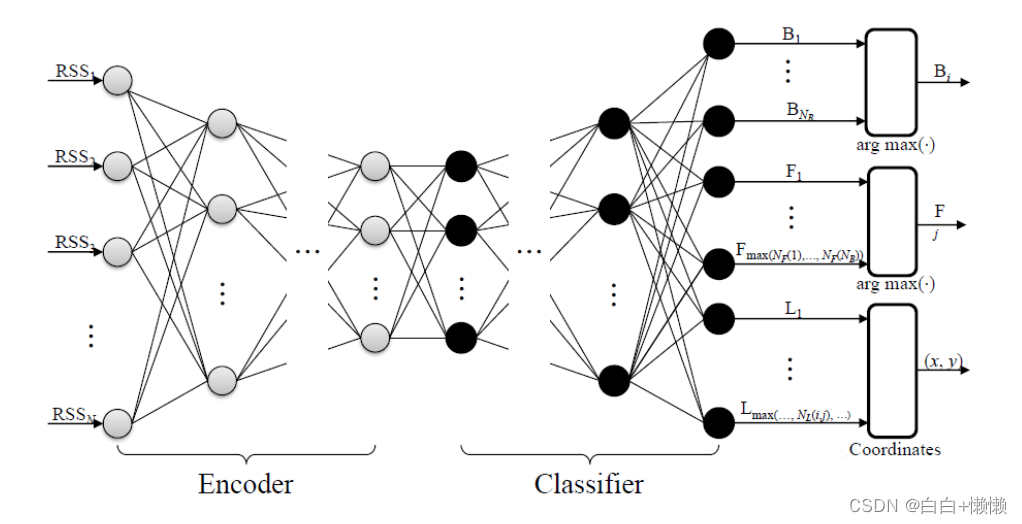
删除解码器
代码如下:
num_to_remove = (len(sae_hidden_layers) + 1) // 2
for i in range(num_to_remove):
model.pop()
model.save(path_sae_model)
添加分类器
model.add(Dropout(dropout)) #将一些网络层通过add进行叠加
for i in range(len(classifier_hidden_layers)):
model.add(Dense(classifier_hidden_layers[i], name="classifier-hidden"+str(i), activation=CLASSIFIER_ACTIVATION, use_bias=CLASSIFIER_BIAS))
model.add(Dropout(dropout))
model.add(Dense(OUTPUT_DIM, name="activation-0", activation='sigmoid', use_bias=CLASSIFIER_BIAS)) # 'sigmoid' for multi-label classification
model.compile(optimizer=CLASSIFIER_OPTIMIZER, loss=CLASSIFIER_LOSS, metrics=['accuracy'])
在使用上述编码器后,增加了激活函数为“relu”的全连接层,且五偏执,再没和全连接层增加了dropout层,防止模型过拟合。输出层也是全连接层,此时的激活函数为“sigmoid”无偏执。
使用优化器“adam”和损失函数“binary_ceossenropy”编译模型,最后对模型进行训练。
需要注意的是这里使用了多标签分类器,结合sigmoid激活函数和二进制交叉熵损失来实现该方法。
此时输入520维Wi-Fi指纹,输出118维,其中0-2代表建筑物的标签,3-7代表楼层的标签,8-117代表位置的标签。
训练模型(添加分类器)
startTime = timer()
model.fit(x_train, y_train, validation_data=(x_val, y_val), batch_size=batch_size, epochs=epochs, verbose=VERBOSE)
elapsedTime = timer() - startTime
print("Model trained in %e s." % elapsedTime)
3. 模型预测与评估
建筑预测与评估
preds = model.predict(test_AP_features, batch_size=batch_size)
n_preds = preds.shape[0]
blds_results = (np.equal(np.argmax(blds, axis=1), np.argmax(preds[:, :3], axis=1))).astype(int)
acc_bld = blds_results.mean()
使用函数,得到预测的多标签结果。然后取下前0-2个标签,表示建筑物的预测标签。
然后使用函数获取最大值的索引,即为预测的建筑。最后,计算所有建筑预测结果的准确率。
楼层的预测与评估
flrs_results = (np.equal(np.argmax(flrs, axis=1), np.argmax(preds[:, 3:8], axis=1))).astype(int)
acc_flr = flrs_results.mean()
取模型预测结果的3-7位的值,然后使用函数得到索引的最大值,最后我们可以得到楼层的结果,并计算所有楼层预测结果的准确率
建筑–楼层预测与评估
acc_bf = (blds_results*flrs_results).mean()
将建筑和楼层的预测结果结合起来,就可以得到最终的结果
位置预测与评估
mask = np.logical_and(blds_results, flrs_results) # mask index array for correct location of building and floor用于正确定位建筑物和楼层
x_test_utm = x_test_utm[mask]
y_test_utm = y_test_utm[mask]
blds = blds[mask]
flrs = flrs[mask]
rfps = (preds[mask])[:, 8:118]
测试位置是一个任意的位置,可能与训练集中给出的位置不同,我们不能直接取最大值的索引作为预测的结果。
mask代表的是所有建筑-楼层都预测正确的索引,即mask是bool型的数组,预测正确的为TRUE。通过mask取出测试数据对应的真实的经纬度坐标,建筑和楼层,以及预测的参考点的标签
n_success = len(blds) # number of correct building and floor location(正确的建筑物和楼层位置的数量)
n_loc_failure = 0
sum_pos_err = 0.0
sum_pos_err_weighted = 0.0
idxs = np.argpartition(rfps, -N)[:, -N:] # (unsorted) indexes of up to N nearest neighbors
threshold = scaling*np.amax(rfps, axis=1)
取出每个测试数据对应的预测参考点标签的最大的N个值。
通过变量计算预测参考点标签的阈值,即一个预测参考点标签的最大值乘为阈值,前N个值只有大于阈值才认为有效。
idxs是前N个值的索引,需要注意的是idxs的行数代表的是成功预测建筑-楼层的数量,列数代表前N个值的索引。
for i in range(n_success):
xs = []
ys = []
ws = []
for j in idxs[i]:
rfp = np.zeros(110)
rfp[j] = 1
rows = np.where((train_labels == np.concatenate((blds[i], flrs[i], rfp))).all(axis=1)) # tuple of row indexes
if rows[0].size > 0:
if rfps[i][j] >= threshold[i]:
xs.append(train_df.loc[train_df.index[rows[0][0]], 'LONGITUDE'])
ys.append(train_df.loc[train_df.index[rows[0][0]], 'LATITUDE'])
ws.append(rfps[i][j])
对于每一个预测成功的建筑-楼层,取出预测参考点标签最大的前N个值,并且分别假设每一个值为最大值时对应的参考点标签,取出该建筑-楼层-参考点在对应的训练集中的经纬度坐标,即代表对应的预测经纬度值。当大于阈值时,则取出预测参考点对应的经纬度坐标,加入到, 中,其本身的预测值加入到中。
if len(xs) > 0:
sum_pos_err += math.sqrt((np.mean(xs)-x_test_utm[i])**2 + (np.mean(ys)-y_test_utm[i])**2)
sum_pos_err_weighted += math.sqrt((np.average(xs, weights=ws)-x_test_utm[i])**2 + (np.average(ys, weights=ws)-y_test_utm[i])**2)
else:
n_loc_failure += 1
key = str(np.argmax(blds[i])) + '-' + str(np.argmax(flrs[i]))
pos_err = math.sqrt((x_avg[key]-x_test_utm[i])**2 + (y_avg[key]-y_test_utm[i])**2)
sum_pos_err += pos_err
sum_pos_err_weighted += pos_err
mean_pos_err = sum_pos_err / n_success
mean_pos_err_weighted = sum_pos_err_weighted / n_success
# rate of location estimation failure given that building and floor are correctly located
#在建筑物和楼层位置正确的情况下,位置估计失败率
loc_failure = n_loc_failure / n_success
将每个测试Wi-Fi指纹预测的N个坐标取平均值(np.mean(xs)),即预测的坐标结果。平均位置误差表示为平均坐标与实际坐标之间的欧氏距离。
N个预测参考点坐标也被加权平均(以元素的值作为权重,np.mean(xs, weights=ws)),计算到真实坐标的欧氏距离作为加权平均位置误差。
对于定位失败的点,我们用当前楼层的平均坐标和实际坐标计算欧式距离作为误差。
最后,计算所有试验数据的平均位置误差(mean_pos_err)、加权平均位置误差(mean_pos_err _weighted)、正确预测建筑物和楼层时定位的失败率(loc_failure)。
定位完成,关于可视化使用的是streamlit,将在下一章进行讲解!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









