 Java爬虫技术实现笔趣阁小说抓取
Java爬虫技术实现笔趣阁小说抓取





 本文介绍如何使用Java爬虫技术,详细解析爬取笔趣阁网站小说的步骤和方法,涵盖网络请求、HTML解析、数据提取等关键环节。
本文介绍如何使用Java爬虫技术,详细解析爬取笔趣阁网站小说的步骤和方法,涵盖网络请求、HTML解析、数据提取等关键环节。
java爬虫爬取笔趣阁小说


package novelCrawler;
import org.jsoup.Connection;
import org.jsoup.HttpStatusException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import ui.DownMsgUI;
import ui.crawlerUI;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.util.Timer;
import java.util.TimerTask;
import javax.sound.sampled.AudioFormat.Encoding;
import javax.swing.JFrame;
import javax.swing.JOptionPane;
import javax.swing.JProgressBar;
public class biquge {
public biquge(String nn,String start,JProgressBar jpbVal,JProgressBar jpb2) {
long t1 = System.currentTimeMillis();
//查找小说
Connection connection1 = Jsoup.connect("http://www.xbiquge.la/xiaoshuodaquan/");
Document document1 = null;
try {
document1 = connection1.get();
} catch (IOException e2) {
// TODO 自动生成的 catch 块
e2.printStackTrace();
}
Elements elementsLis1=null;
try {
Element elementUL1 = document1.select("[class=novellist]").first();
elementsLis1 = elementUL1.select("li");
} catch (Exception e1) {
// TODO 自动生成的 catch 块
e1.printStackTrace();
}
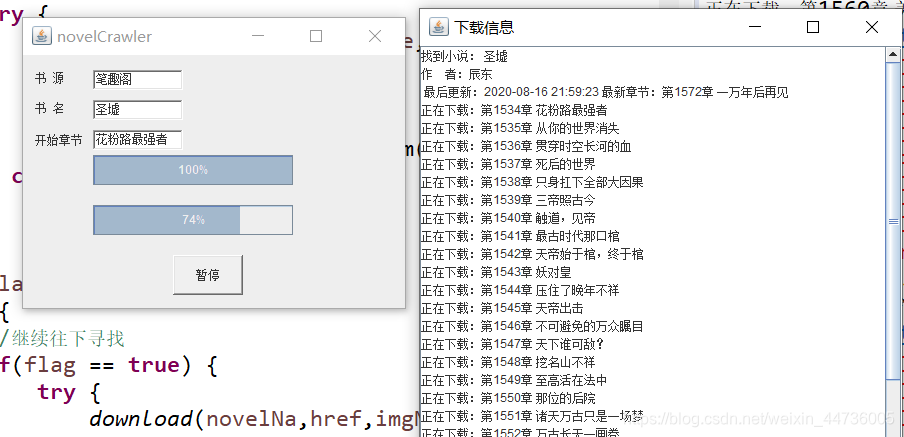
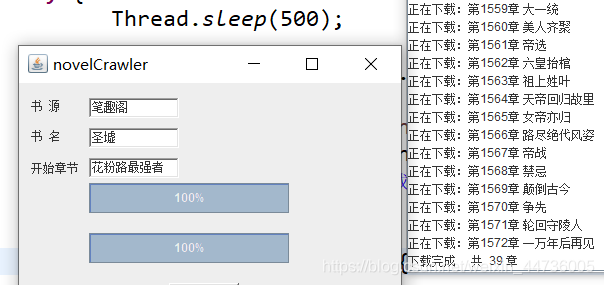
jpbVal.setVisible(true);
int count = 0;
DownMsgUI dmu = new DownMsgUI();//消息框
//巡官遍历获取到的整个elementsLis集合
for(Element elementLi1 : elementsLis1){
try {
Thread.sleep(200);
} catch (InterruptedException e1) {
// TODO 自动生成的 catch 块
e1.printStackTrace();
}
Element elementA1 = elementLi1.select("a").first();
String href = elementA1.attr("href");//获取标签中的属性值(它这里采用的是相对路径的写法
String novelNa = elementA1.text();//小说名
jpbVal.setMaximum(elementsLis1.size());
int result1 = novelNa.indexOf(nn);//匹配小说名
if(result1 != -1){
//跟进小说
jpbVal.setValue(elementsLis1.size());
//JOptionPane msg = new JOptionPane();
//msg.setBounds(100, 100, 100, 100);
//JOptionPane.showMessageDialog(jpb2,"已找到小说:"+novelNa);
dmu.ta.append("找到小说: "+novelNa+"\n");
connectNovel(novelNa,href,start,jpb2,dmu);
break;
}else{
//继续往下寻找
//System.out.println("未找到小说!");
jpbVal.setValue(count);
}
count++;
if(count>=elementsLis1.size()) {
System.out.println("未找到小说!");
}
}
}
/////////////////////////////////////////////////////////////////////////////////////
public void connectNovel(String novelNa,String h,String start,JProgressBar jpb2,DownMsgUI dmu) {
//1.与我们要爬取数据的页面建立连接
Connection connection = Jsoup.connect(h);
jpb2.setVisible(true);
Document document = null;
try {
document = connection.get();
} catch (IOException e2) {
// TODO 自动生成的 catch 块
e2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









