




 本文记录了使用Python进行网络爬虫,抓取笔趣阁小说网站内容的过程。首先找到小说页面URL,然后通过浏览器开发者工具获取网页内容范围。接着,利用XPath解析网页,提取出标题和文章内容。
本文记录了使用Python进行网络爬虫,抓取笔趣阁小说网站内容的过程。首先找到小说页面URL,然后通过浏览器开发者工具获取网页内容范围。接着,利用XPath解析网页,提取出标题和文章内容。
- 找到笔趣阁的小说对应地址,比如:https://www.biquge7.com/book/6330/

- 刷新网页,F12拿到当前网页的范围内容
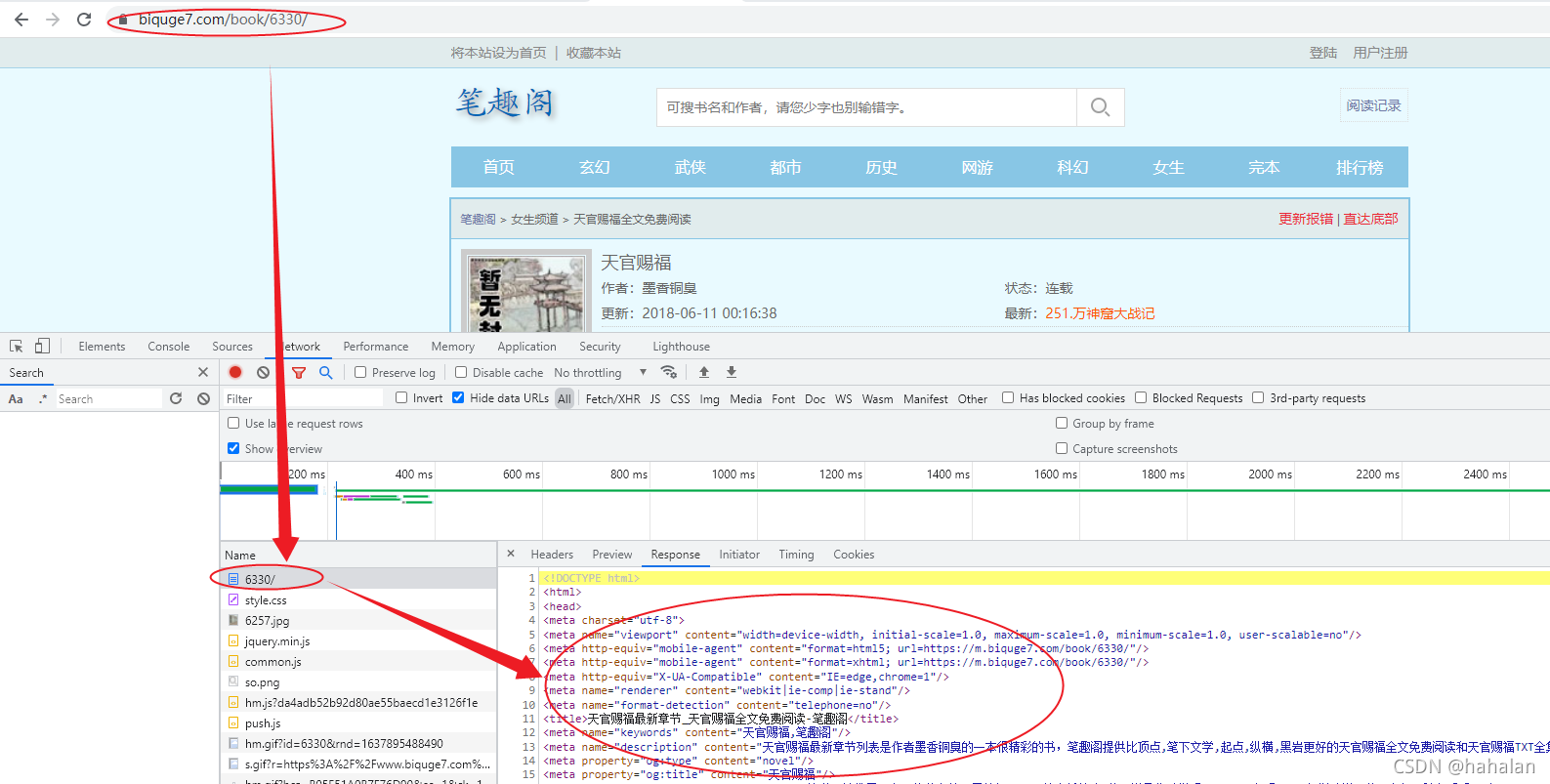
- 开始代码爬取:
import requests
from bs4 import BeautifulSoup
import re
from lxml import etree
# 手动输入:小说名+地址
bigTitle = '天官赐福'
url = 'https://www.biquge7.com/book/6330/'
# 获取当前url内容
webSideHtml = requests.get(url)
soup = BeautifulSoup(webSideHtml.text, 'lxml')
# 剔除页面上“最新”的那一章,防止拿到的url重复:找到“最新”章对应的class
for span in soup. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









