



关于最新的基座模型:

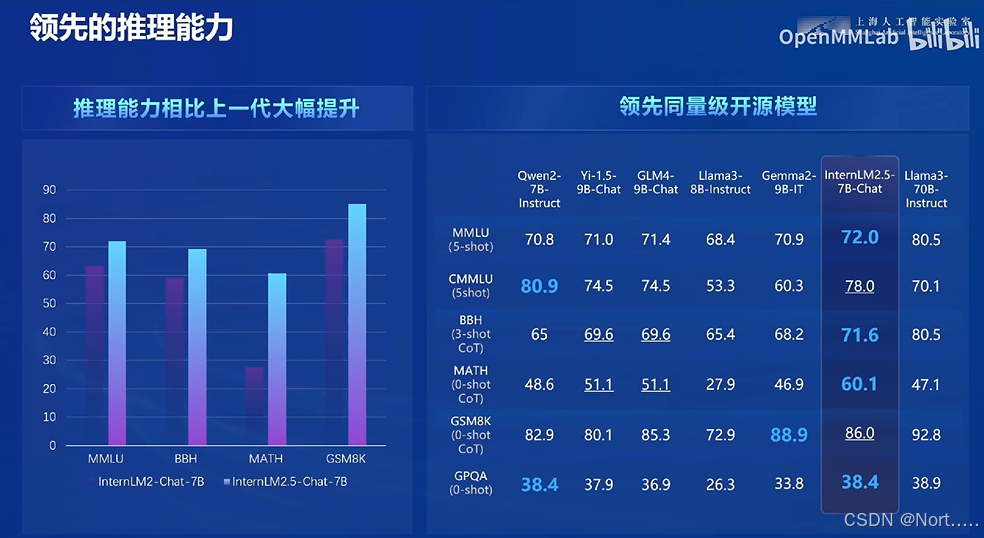
最新版本的模型相比上一个版本的性能提升20%
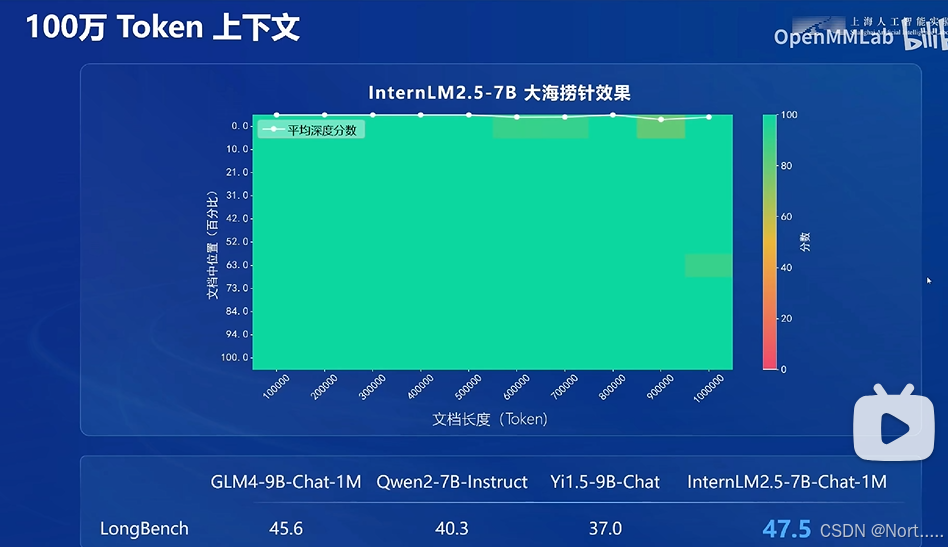
现在最新模型可以支持长文本的输入并且它在大海捞针实验中取得了不错的表现:
大海捞针实验(Needle In A Haystack)是一种评估大型语言模型(LLM)在长文本中寻找关键信息能力的测试方法。 该实验由Greg Kamradt设计,通过在一段长文本中随机插入关键信息(“针”),并测试模型是否能准确地从大量无关信息中提取出关键信息。
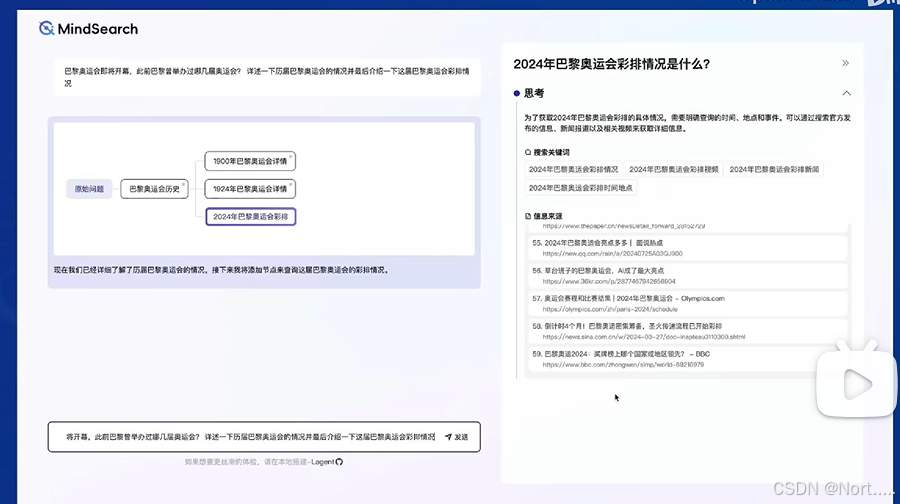
可以借用MindSearch对任务进行规划和拆解,并通过搜索解决一些复杂的问题:
目前最新的几种不同量级的基座模型

InterLM全链条初步介绍

书生万卷语料库
InterLM的多模态语料库,里面包含了视频,图片,文本,3D模型,下面附有链接

GitHub - opendatalab/WanJuan1.0: 万卷1.0多模态语料
数据处理工具箱
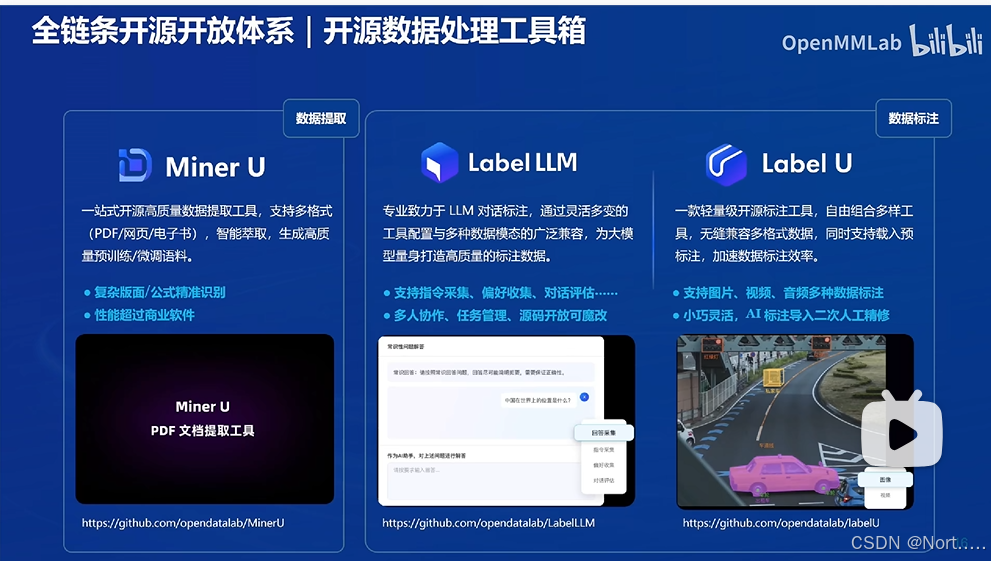
https://github.com/opendatalab/MinerU
A one-stop, open-source, high-quality data extraction tool, supports PDF/webpage/e-book extraction.一站式开源高质量数据提取工具,支持PDF/网页/多格式电子书提取。
https://github.com/opendatalab/LabelLLM
The Open-Source Data Annotation Platform
GitHub - opendatalab/labelU: Data annotation toolbox supports image, audio and video data.
Data annotation toolbox supports image, audio and video data.
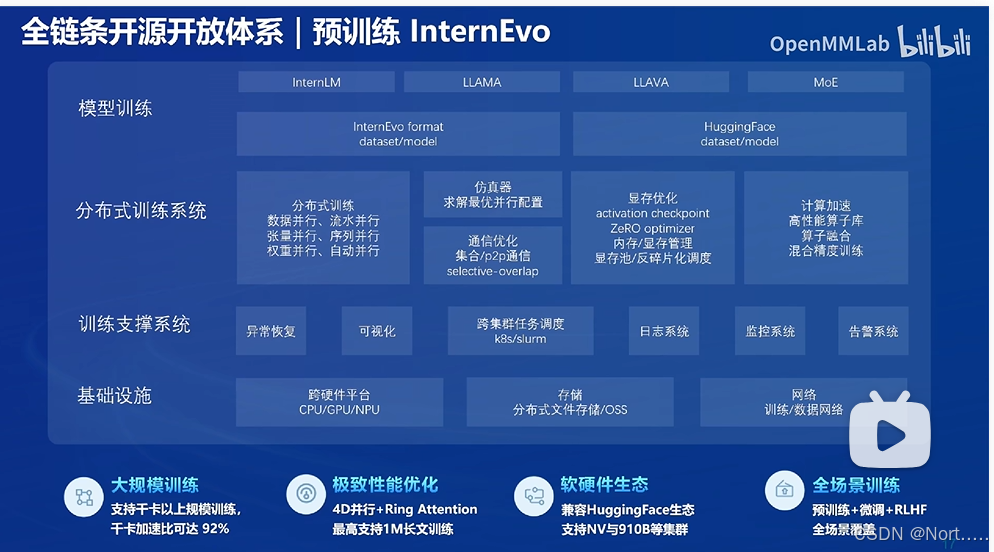
预训练InternEvo
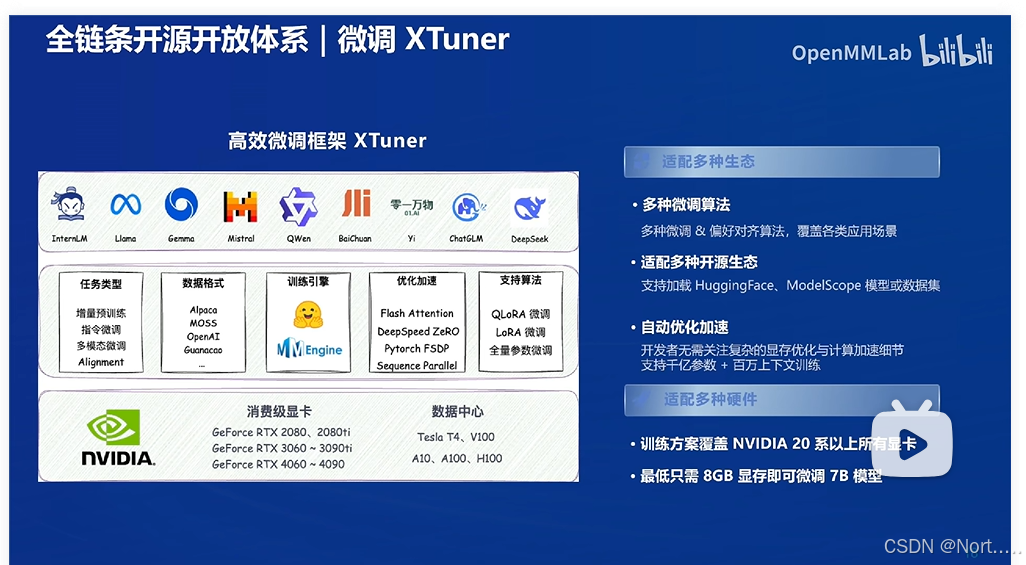
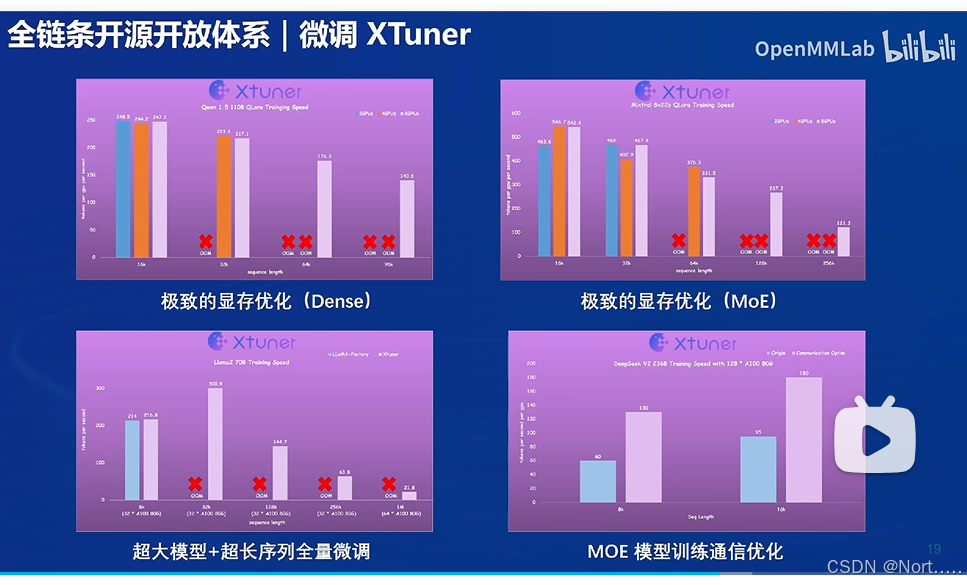
微调XTuner
中文评测体系(OpenCompass)

CompassRank 系统进行了重大革新与提升,现已成为一个兼容并蓄的排行榜体系,不仅囊括了开源基准测试项目,还包含了私有基准测试。此番升级极大地拓宽了对行业内各类模型进行全面而深入测评的可能性。
CompassHub 创新性地推出了一个基准测试资源导航平台,其设计初衷旨在简化和加快研究人员及行业从业者在多样化的基准测试库中进行搜索与利用的过程。为了让更多独具特色的基准测试成果得以在业内广泛传播和应用,我们热忱欢迎各位将自定义的基准数据贡献至CompassHub平台。只需轻点鼠标,通过访问这里,即可启动提交流程。
CompassKit 是一系列专为大型语言模型和大型视觉-语言模型打造的强大评估工具合集,它所提供的全面评测工具集能够有效地对这些复杂模型的功能性能进行精准测量和科学评估。在此,我们诚挚邀请您在学术研究或产品研发过程中积极尝试运用我们的工具包,以助您取得更加丰硕的研究成果和产品优化效果。
部署LMDeploy
GitHub - InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.

应用
智能体Lagent
GitHub - InternLM/lagent: A lightweight framework for building LLM-based agents

MindSearch(Planning+Searching+Integration)
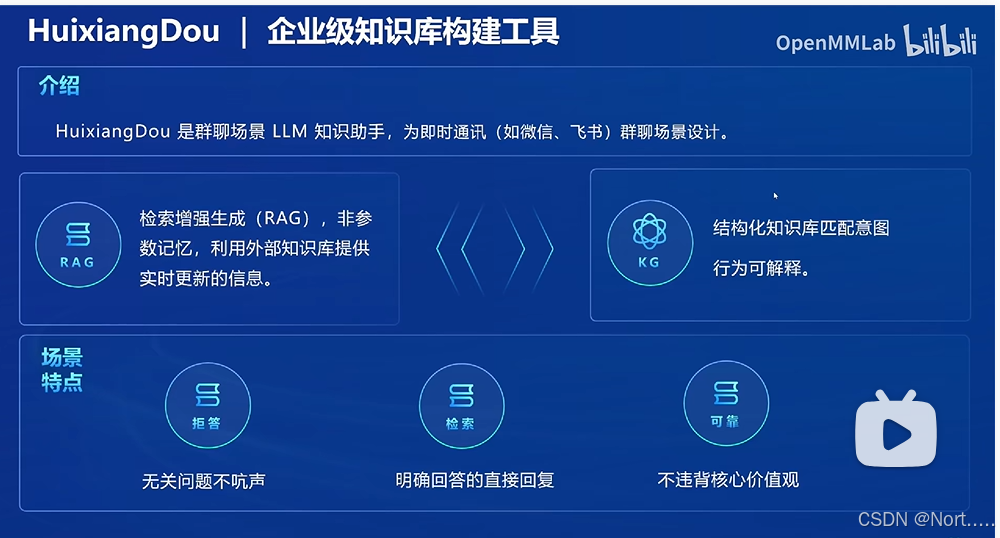
RAG

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









