







 文章介绍了MobileNet系列网络,包括MobileNetV1、V2和V3的设计亮点,如深度可分离卷积、倒残差结构、线性瓶颈和SE模块,旨在减少计算量和参数,提高在移动设备和嵌入式设备上的运行效率。MobileNetV2通过InvertedResiduals和LinearBottlenecks提升了准确率,V3则引入了SE模块和h-swish激活函数优化性能。
文章介绍了MobileNet系列网络,包括MobileNetV1、V2和V3的设计亮点,如深度可分离卷积、倒残差结构、线性瓶颈和SE模块,旨在减少计算量和参数,提高在移动设备和嵌入式设备上的运行效率。MobileNetV2通过InvertedResiduals和LinearBottlenecks提升了准确率,V3则引入了SE模块和h-swish激活函数优化性能。
传统卷积神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行
比如VGG-16的权重文件大小就有490M,ResNet 50 权重有944M。

MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%但模型参数只有VGG的1/32)

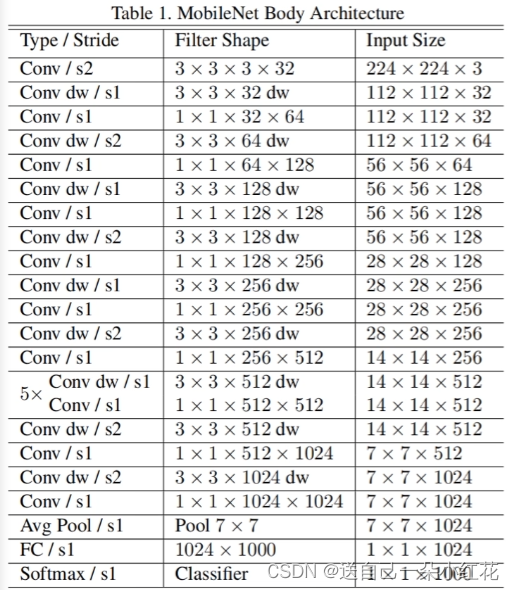
网络结构
网络亮点:
1 Depthwise Convolution(大大减少运算量和参数)
2 增加超参数α,β (α控制卷积层卷积核个数的参数,β控制输入图像大小,这两个是自己学)
Depthwise Convolution:
让每一个卷积核负责卷积一个输入feature map的channel。
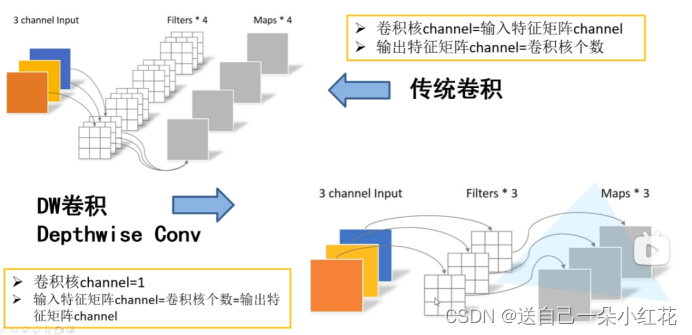
Depthwise Separable Convolution:
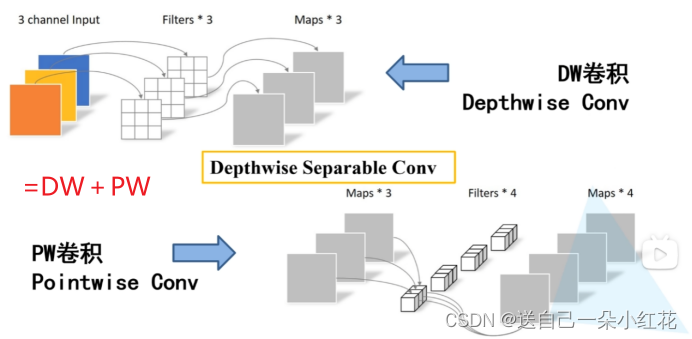
DW+PW卷积相组合就是一种普通卷积,看图。
其中PW卷积就是卷积核大小为1x1的卷积操作。
为何使用DWPW卷积:减少计算量
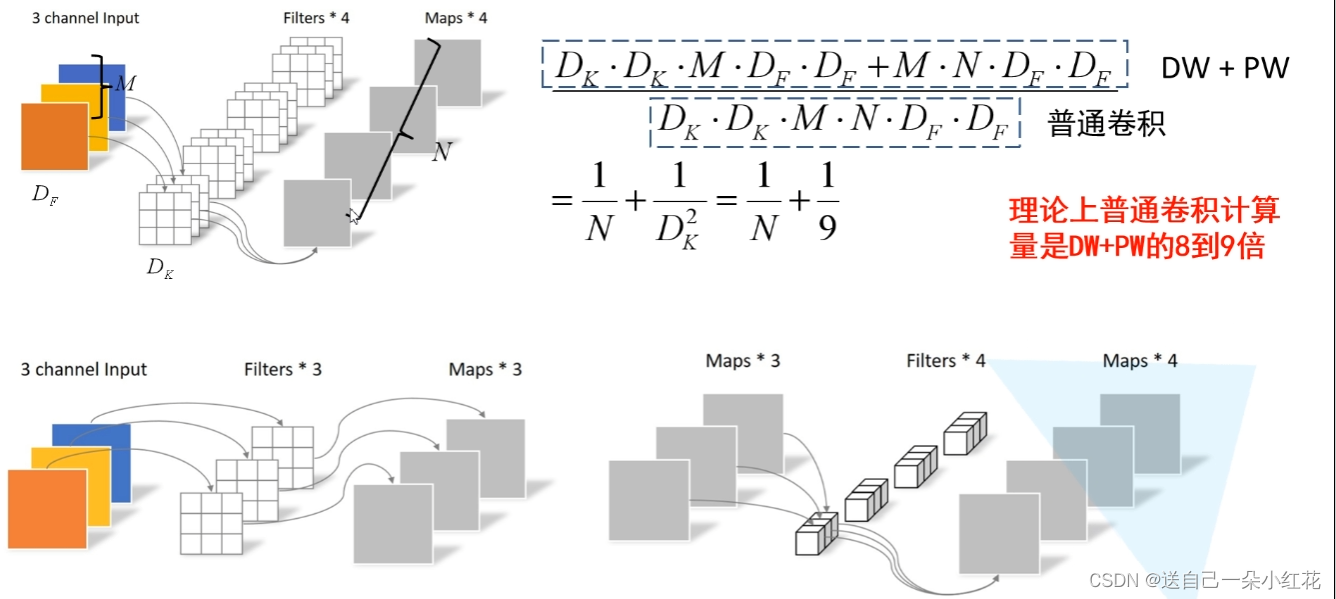
论文中显示我们MobileNet的准确率降低了一个点左右,但是我们的参数却少了134Million parameters。
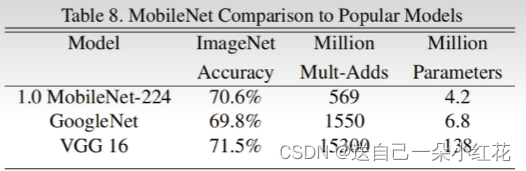
对应α的变化,准确率和参数。

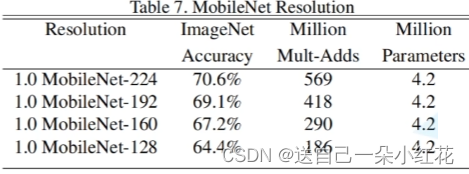
对应β(输入图像大小)对应的计算量和参数
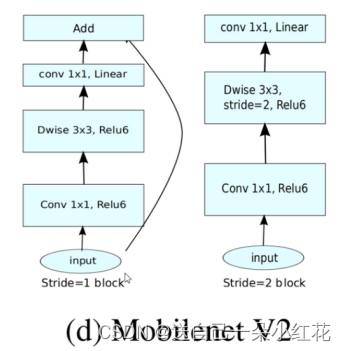
MobileNet V2:针对v1版本中depthwise 部分的卷积核很容易废掉,即卷积核参数大部分为0.
MobileNet v2网络是由google团队在2018年(间隔1年)提出的,相比MobileNet V1网络,准确率更高,模型更小。

亮点:
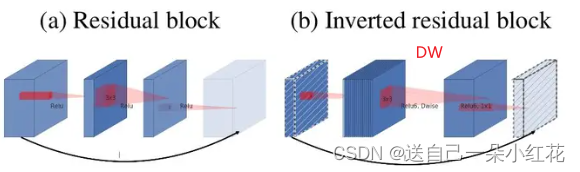
1 Inverted Residuals(倒残差结构)
2 Linear BottleNecks
Inverted Residuals(倒残差结构):
residual block 是残差结构,可以理解它是用来中间细两头粗的结构,而Inverted Residuals可以理解为中间粗两头细的结构。注意:在倒残差结构中的激活函数是ReLu6激活函数。
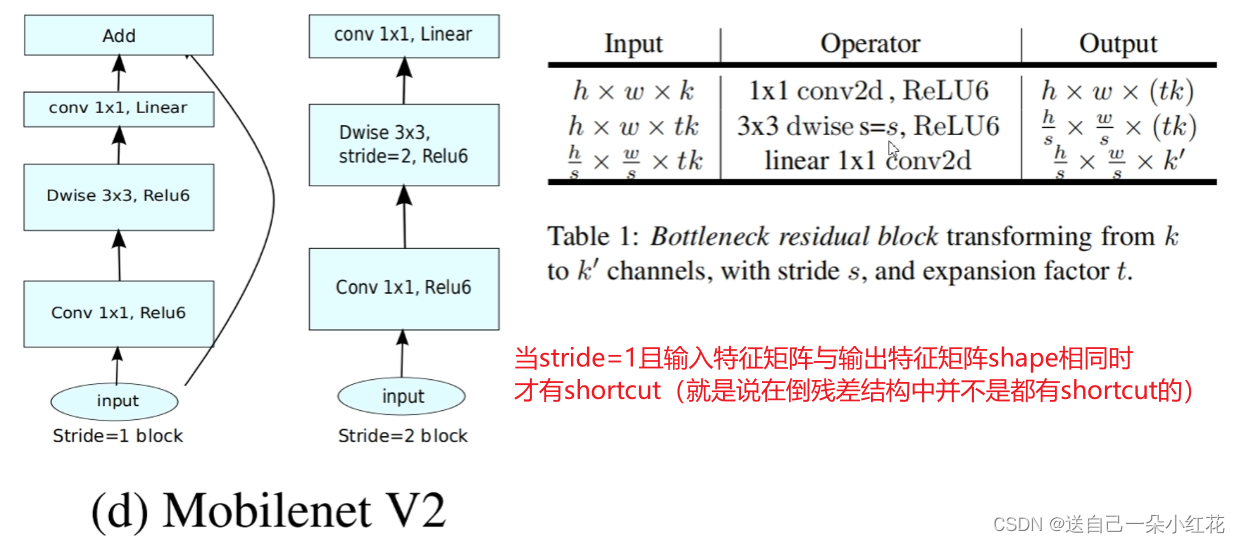
2 Linear BottleNecks
https://blog.youkuaiyun.com/baicaiBC3/article/details/122363249
MobileNet V2中引入了Linear Bottleneck。Linear BottleNecks是没有激活函数的Bottlenecks块。
在论文的第3.2节中,他们详细讨论了为什么在输出之前存在非线性会损害性能。简而言之,非线性函数ReLU在<0时设为0会导致破坏信息。因此,在Bottlenecks中删除nn.ReLU你就可以拥有Linear BottleNecks。
mobilenetv2认为relu将信息从低纬到高纬度不会存在信息丢失(反之会存在信息丢失),如下图,所以在expansion layer(1x1 conv进行channel升维)会保留relu6,但是在projection layer(1x1 conv进行channel降维)会取消relu6
MobileNet V3
亮点:
1 更新了block, 加入SE模块(SQqueeze and excitation)。
2 更新了激活函数,使用h-swish函数激活。
当前基于MobileNetV2的倒置瓶颈结构和变体的模型使用1x1卷积作为最后一层,以便扩展到更高维度的特征空间。为了具有丰富的预测特征,这一层至关重要。 但是,这要付出额外的计算和延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1*1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少7ms的开销,在提速11%的同时减小了30m的操作数。
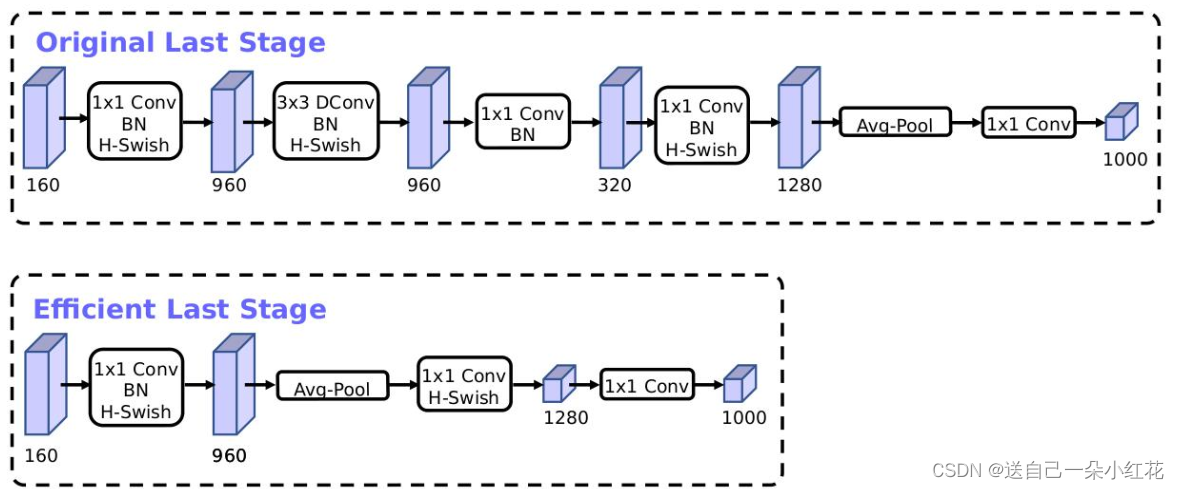
1注意力机制(SE)
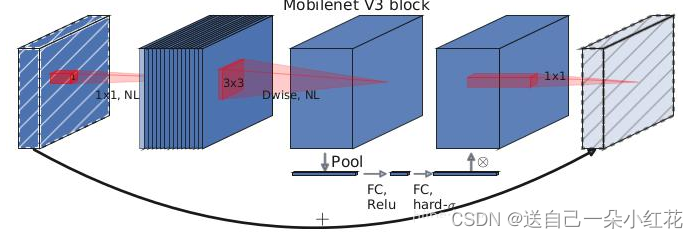
注意:Nl:不是进行的线性激活
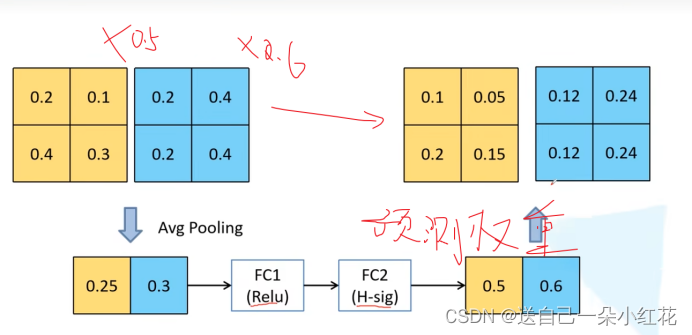
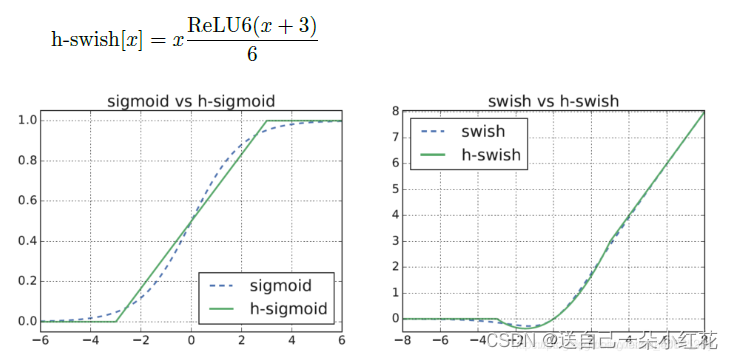
2 H-swish激活函数
swish非线性激活函数替代ReLU函数,可以显著提高神经网络的准确性,其定义如下:
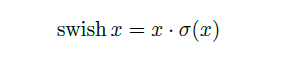
尽管这种非线性提高了准确性,但在嵌入式环境中却带来了非零成本,因为S型函数在移动设备上的计算成本更高。主要是计算、求导复杂,对量化过程不友好。所以我们将其进行改进(用relu6进行改进,因为它求导计算简单方便)。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------下面是笔记上其他的内容-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
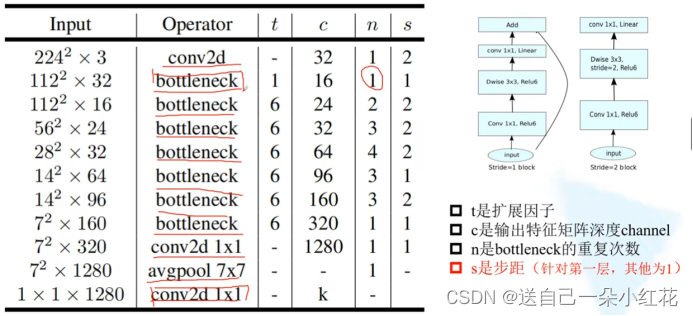
7.2 pYTORCH实现Mobile net V2
网络结构
进入代码
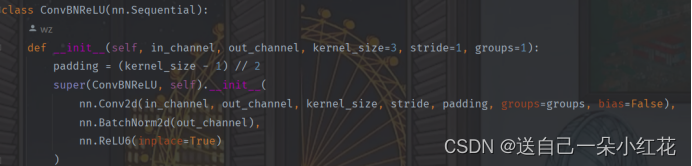
group注意一下,在pytorch里它的DW卷积,也是调用的nn.conv类,当group为1时,它是普通卷积,当group输出特征矩阵的深度的时候(也就是in_channel),它就是DW卷积。所以在定义的时候,传入groups这样的一个参数。
Padding 是根据我们kernel_size来进行设置的
Super(ConvBNRElU,self):
继承了Sequential以后他构造的函数相当于直接构造了Sequential结构
倒残差结构、
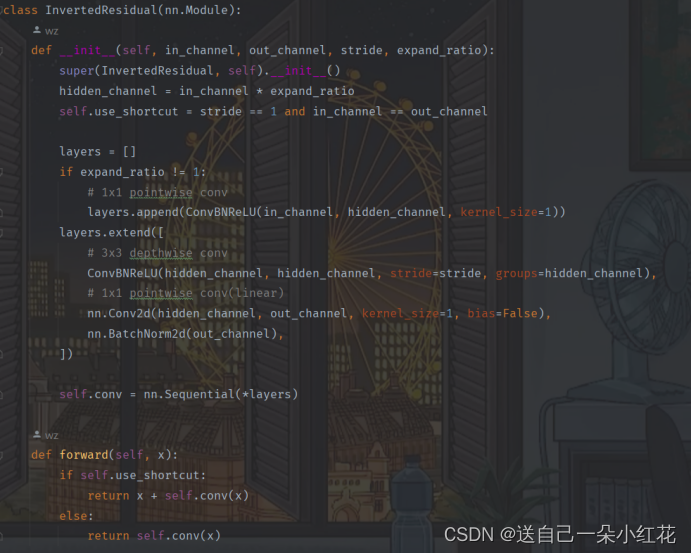
两头细中间粗
函数初始换中传入了in_c,out_c,stride,expand_ratio扩展银子(表格当中的t)
父类初始化,他创造他自己
定义变量隐层channel(第一层卷积层的卷积核的个数){tk}
self.use_shortcut = 判断是否使用捷径分支[and 同时满足才返回true]
创建列表
判断是否扩充(t),如果t为1,我们就不需要第一个1x1的卷积了
Append一次插入一个,extend可以批量插入、
3x3卷积,输出输出都是hidden_channel因为DW卷积,输入输出是相同的,stride是我们初始传进来的,group = hidden_channel表示这是一个DW卷积
1x1就不能使用我们定义的convbnrelu,只能用最原始的conv2d,这一场就不需要进行relu函数了,liner层就是让y=x的,不对我们的输出进行处理,所以我们不需要额外的添加一个激活层函数。
到这里我们所有的层结构就定义好了
在 Python 中,一个星号(*)用于解包一个列表或元组,使其成为函数的独立参数。在这种情况下,*layers将列表或元组中的所有元素解包并传递给nn.Sequential()函数作为独立参数。因此,*layers是一个可变长度的参数列表,它可以接受任意数量的层作为输入,并将它们传递给nn.Sequential()函数。这使得创建深度神经网络的代码更加简洁和易读

Alpha是超参数,控制卷积层所使用卷积核个数的倍率
Round_nearest是倍率,把她设置为8 的整数倍,更好的调用我们的设备
通过Make_divisible把channel变成8的倍数
Last channel是我们最后一层的1x1卷积,
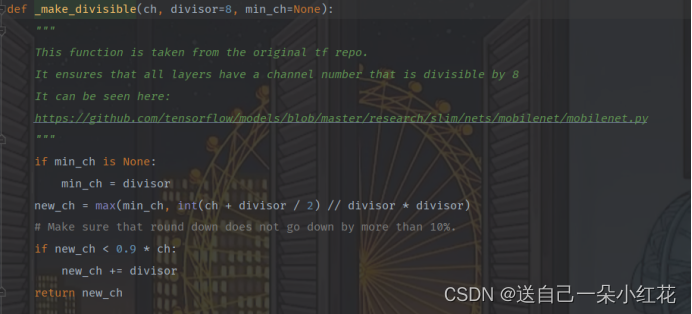
Ch传入的卷积核个数
min_ch最小通道数
如果最小卷积核个数为None,那么min_ch=diversor
Int(ch+divisor/2)就是在取整
//两个除号,将我们的结果自动向下取整

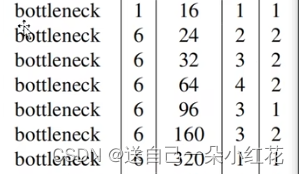
list里面每一个元素都是表格中对应一行的参数
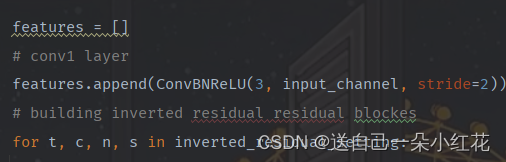
再定义一个列表,输入是3,输出是input-channel
先把第一层卷积写进去:ConvBNReLU(),定义好了的函数,你没指定kernel size,就以函数定义默认为3x3.
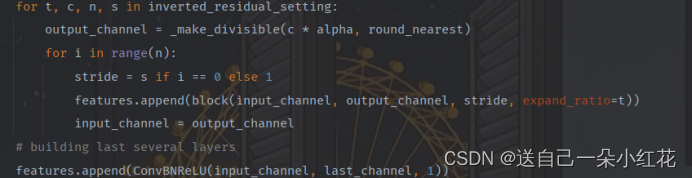
Output channel 定义一下未来可变的超参数(t)
n是这一层有几个倒残差结构
表格中的s、对应第一层的一个布局,其他层的步距都是1
把out_channel给input_channel,(输出)作为我们下一层的输入
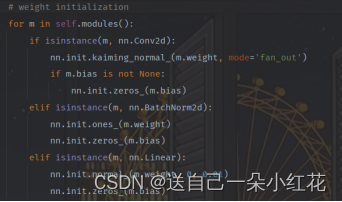 定义了一个初始化权重的操作:
定义了一个初始化权重的操作:
Self.module()我们定义的所有子模块
在这段代码中,m.weight 表示神经网络层的权重参数,使用 kaiming_normal_ 方法进行随机初始化。其中,mode='fan_out' 表示使用输出通道数作为权重张量的缩放因子。
对于卷积层,采用kaiming正态分布初始化方法(kaiming_normal_),同时将偏置初始化为0(zeros_)。
对于批归一化层,将权重参数初始化为1(ones_),将偏置参数初始化为0(zeros_)。
对于全连接层,将权重参数初始化为均值为0、标准差为0.01的正态分布(normal_),将偏置参数初始化为0(zeros_)。
通过这些初始化方法,可以使神经网络在训练时更快、更稳定地收敛,并且可以有效地避免梯度消失或爆炸等问题。
Self.avgpool = nn.AdaptiveAvgPool2d((1,1))
在这个代码中,(1, 1)表示输出张量的高度和宽度都为1,因此nn.AdaptiveAvgPool2d((1, 1))实际上是一个全局平均池化,将整个2D平面内的像素值求平均。这是在一些图像分类模型中常用的一种方法,因为它可以帮助模型更好地捕捉图像的全局特征,从而提高模型的分类性能。
模型定义讲完了:
Train.py:
下载官方的预训练模型参数
在train.py里面导入
import torchvision.models.mobilenetv2
下载下来
pre_weights = torch.load(model_weight_path, map_location='cpu')
载入权重得到的是字典类型
![]()
![]()
(第一种)遍历权重字典:k: v for k, v in pre_weights.items()
如果“clsaaifier”不在k层名称里面,我们就保存我们的权重参数
(第二种)
首先,通过字典推导式,将预训练模型的权重(pre_weights)中与新的神经网络模型(net)中具有相同形状的权重筛选出来,形成一个新的字典 pre_dict。
接着,调用新的神经网络模型的 load_state_dict 方法,将 pre_dict 中的权重加载到新的神经网络模型中。在加载权重时,由于预训练模型和新的神经网络模型的结构可能不完全相同,因此设置 strict 参数为 False,表示可以忽略预训练模型中存在但是新的神经网络模型中不存在的权重,以及新的神经网络模型中存在但是预训练模型中不存在的权重。加载完权重后,函数会返回两个列表 missing_keys 和 unexpected_keys,分别表示在加载权重过程中遇到的缺失的键和意外的键。
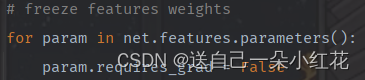
这段代码的作用是将网络模型中的所有卷积层参数的requires_grad属性设置为False,即将这些参数标记为不需要梯度更新,避免在网络的反向传播过程中对这些参数进行更新,从而提高训练效率。这通常用于对预训练模型进行微调时,保持预训练的参数不变,只更新新添加的全连接层等特定部分的参数。
Net.feature是模型里面定义的feature部分的意思,全部冻结用net.parameters()
7.2.2
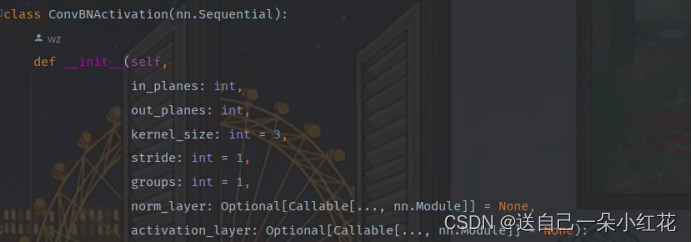
这段代码定义了两个可选参数norm_layer和activation_layer,它们的类型都是Callable,即可调用对象。在这里,Callable[..., nn.Module]表示这些可选参数需要是一个函数,其返回值是一个nn.Module类型的对象。具体来说:
norm_layer表示用于归一化的层,如Batch Normalization、Layer Normalization等,这里可以传入一个自定义的归一化层函数,默认为None。
activation_layer表示用于激活的层,如ReLU、LeakyReLU等,这里也可以传入一个自定义的激活函数,默认为None。
在模型定义中,这些可选参数可以用来替换模型中的默认层,从而实现模型结构的定制化。例如,可以使用自定义的归一化层来替换模型中的Batch Normalization层,或使用自定义的激活函数来替换模型中的ReLU层。
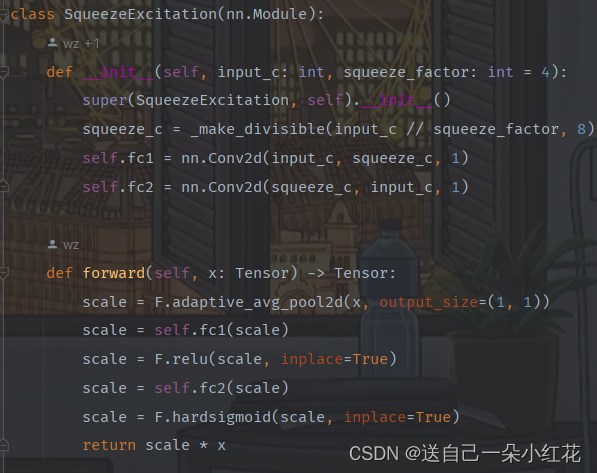
注意力机制
SE模块=两个全连接层
第一个se模块,节点个数是输入特征矩阵的1/4,relu
第二个与输出特征矩阵一致,hardsigmid
这里的类型提示 "-> Tensor" 表示 forward() 方法返回的是一个 Tensor 类型的对象。类型提示可以在 PyTorch 中增加代码的可读性和可维护性。
Scale* x 在此处就是那个向上的箭头 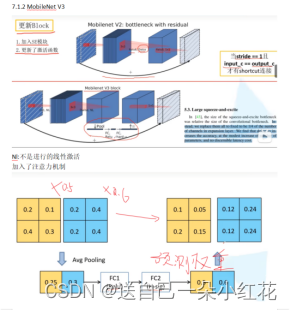

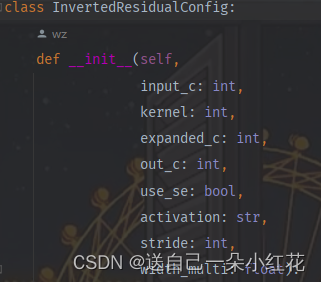
width_multi,倍率因子,expanded_c对应第一层的卷积核个数
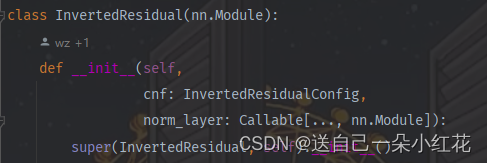 左边一整个结构取名↑
左边一整个结构取名↑
![]() 定义空列表,每个都是nn.model类型
定义空列表,每个都是nn.model类型
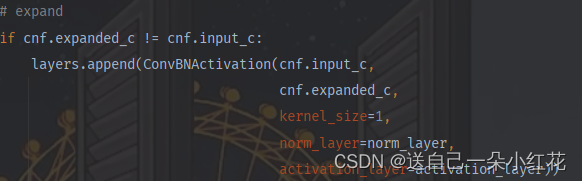
升维操作
第一层没有升维操作,之后的bneck都有
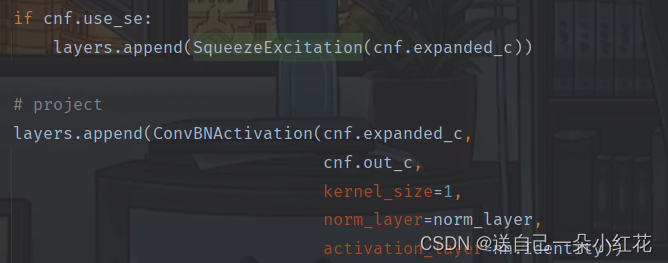
DW操作,里面nn.Identity函数是表示没有任何操作。
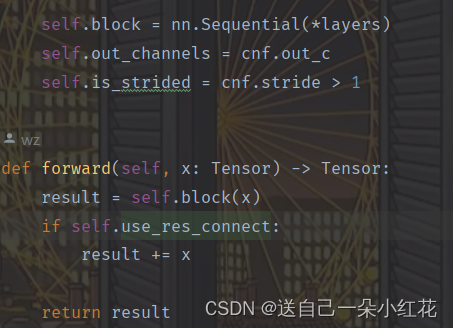
把上面的卷积等操作放到self.block(包含了卷积,DW,SE)
Self.use_res_connect判断是否用shortcut
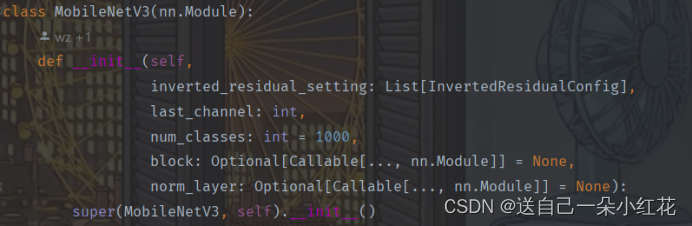
inverted_residual_setting,对应一系列我们的bneck的所有参数
Last channel是倒数第二个卷积层,输出节点个数
nun_class 分类个数
Block 我们定义的invertedResidual模块
![]()
默认值eps,momentum
原文链接:https://blog.youkuaiyun.com/weixin_44751294/article/details/116903680


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









