






Learning Perceptive Humanoid Locomotion over Challenging Terrain
Learning Perceptive Humanoid Locomotion over Challenging Terrain
研究动机
- 人形机器人必须能够在各种地形上行走,包括具有挑战性的越野环境中。
- 人类和动物会根据积累的经验不断修正自己和环境的理解——形成所谓的世界模型,而人形机器人通常在设计阶段无法考虑到错误的地形感知。这一缺陷在变形表面或传感器数据噪声较大的情况下,会降低其可靠性,从而增加实际部署中的风险。
- 传统方法通常依赖于预先构建的高精度地图,并通过优化预先计划或动态重新计划的轨迹和着地点来生成机器人动作。它们的成功取决于对机器人及其环境的准确建模,并且它们通常假设传感器输入和地形感知中没有噪声。不幸的是,这种假设限制了这些方法在面对真实世界场景中遇到的各种感知错误时的可扩展性和鲁棒性。强化学习通过整合高度图和域随机化模拟传感器噪声提供了有吸引力的替代方案。这种方法消除了预先确定的着地点或轨迹的需要,并有望在非结构化环境中应用。然而,即使在最先进的仿真器中,复制感知失败的完整范围——例如由茂密的植被引起的——仍然具有挑战性,这可能导致感知和实际地形之间的持续差距。
解决方案
提出人形机器人控制器,该控制器旨在整合外部地形感知并减轻传感器噪声。方法核心是使用具有变分信息的世界模型对观测和特权状态进行去噪估计。训练过程采用教师-学生知识蒸馏框架,分为两个阶段。在第一阶段,教师策略仅在纯净、无噪声的数据上进行训练。在随后的阶段,学生策略,包括世界模型和运动控制器,被蒸馏出来。学生策略使用世界模型的编码器处理噪声观测,并将压缩特征输入到运动控制器中。其训练同时受到解码器的重构损失和模仿损失的驱动,后者鼓励与教师的动作对齐,从而提高输入质量和最终的控制效果。
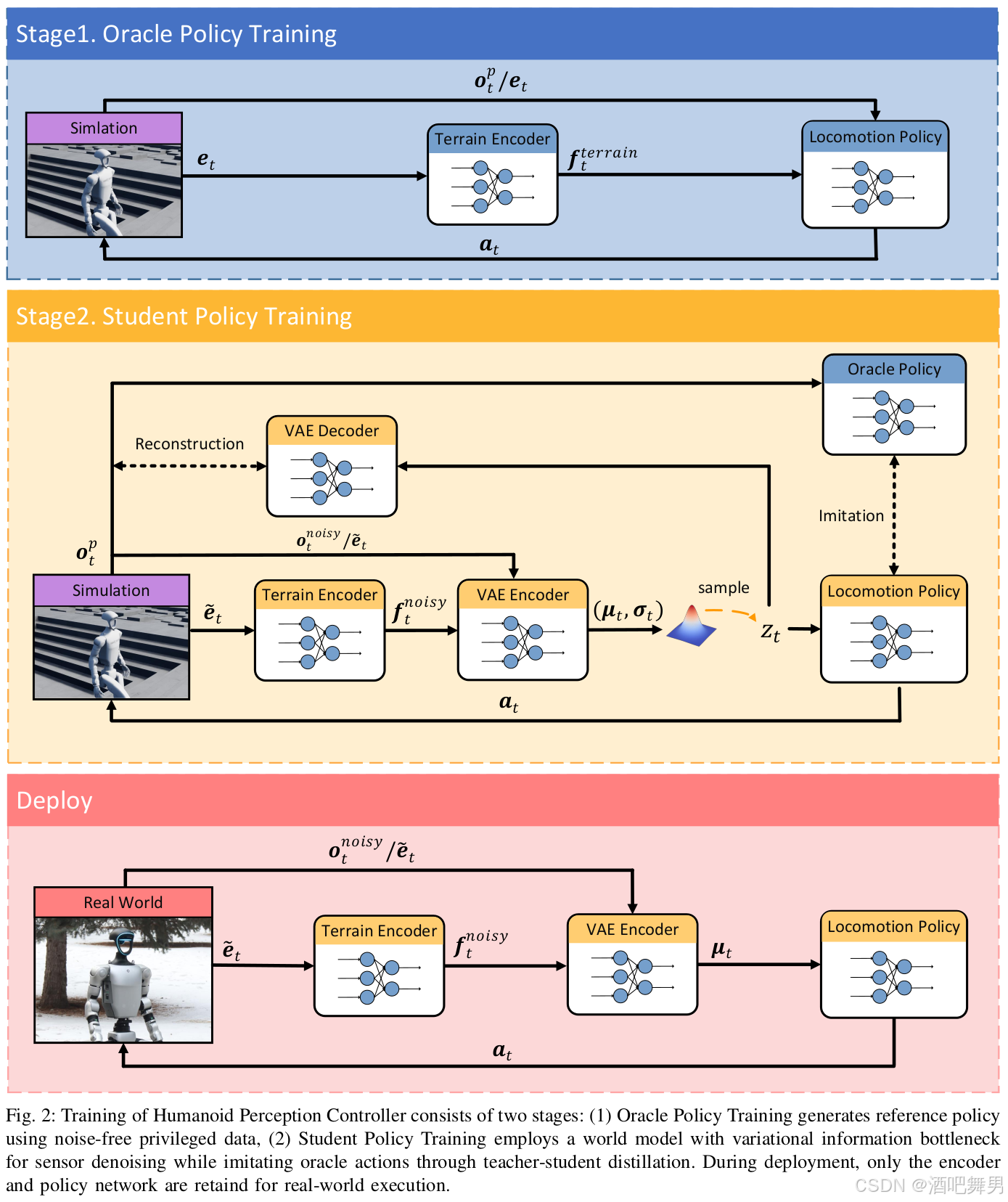
技术路线
Oracle策略训练
在第一阶段,将Oracle策略优化形式化为马尔科夫决策过程 M = ( S , A , P , r , γ ) \mathcal{M}=(\mathcal{S}, \mathcal{A}, \mathcal{P}, r, \gamma) M=(S,A,P,r,γ),以推导出最优的参考策略 π ∗ : S p → A \pi^*:\mathcal{S}^p \rightarrow \mathcal{A} π∗:Sp→A,其中 S p ⊆ R d s \mathcal{S}^p\subseteq \mathbb{R}^{d_s} Sp⊆Rds表示包含无噪声的本体感知和外部传感器测量的特权状态空间。并使用PPO进行参数化,以最大化累积奖励为目标:
π ∗ = a r g m a x π E τ ∼ p π [ ∑ t = 0 T γ t r ( s t p , a t ) ] \pi^* =arg \underset{\pi}{max} \mathbb{E}_{\tau \sim p_\pi}[\sum_{t=0}^{T}\gamma ^t r(s_t^p,a_t)] π∗=argπmaxEτ∼pπ[t=0∑Tγtr(stp,at)]
其中 γ ∈ [ 0 , 1 ) \gamma \in [0, 1) γ∈[0,1)表示折扣因子, s t p ∈ S p s_t^p \in \mathcal{S}^p stp∈Sp表示特权信息集。Actor网络 π ϕ t \pi_{\phi_t} πϕt和Critic网络 V ψ t V_{\psi_t} Vψt获取 Ω t p \Omega_t^p Ωtp的完全可观。
Privileged Observation
Oracle策略的观测值包含了仿真中可获得的信息,以最大化Oracle策略的性能。具体包括 o t p = ( h t p , p t p , R t p , v t p , ω t p , v t ∗ , ω t ∗ , c t p , q t , q ˙ t , a t − 1 , e t ) o_t^p=(h_t^p,p_t^p,R_t^p,v_t^p,\omega_t^p,v_t^*,\omega_t^*,c_t^p,q_t,\dot{q}_t,a_{t-1},e_t) otp=(htp,ptp,Rtp,vtp,ωtp,vt∗,ωt∗,ctp,qt,q˙t,at−1,et),分别为机器人root的高度、机器人本体的局部位置、机器人本体的局部旋转角、机器人本体的局部角速度、机器人本体的线速度和角速度、机器人身体的接触力、关节位置、关节速度和上一帧的动作,最后 e t e_t et为以机器人为中心的高度图。
Oracle策略架构
oracle策略使用了架构相似但独立的网络分别用于Actor和Critic。地形编码器 T θ t T_{\theta_t} Tθt将无噪声的高度图 e t e_t et转换为空间特征 f t t e r r a i n ∈ R d e f_t^{terrain} \in \mathbb{R}^{d_e} ftterrain∈Rde,然后与本体感知和运动学测量值拼接用于策略输入。
该架构通过LSTM层进行时间建模,保持隐藏状态 h t ∈ R d h h_t \in \mathbb{R}^{d_h} ht∈Rdh,随后在两个网络中使用MLP分支。策略 π ϕ t \pi_{\phi_t} πϕt通过MLP处理LSTM输出以生成动作均值 μ ϕ t \mu_{\phi_t} μϕt,而Critic使用单独的MLP分支进行值估计。
奖励函数设计
在奖励函数中故意省略了预定义的运动参考。仅使用正则化奖励来约束机器人的行为,以充分发挥机器人的能力。
学生策略
在第二阶段,提炼学生模型,该模型由用于预测和去噪的世界模型以及运动策略组成。
Student Observation
学生策略的观测值包含目标命令以及带噪声的本体感知和地形感知 o t = ( ω t , p t , v t , v t ∗ , ω t ∗ , q t , q ˙ t , a t − 1 , e ~ t ) o_t=(\omega_t,p_t,v_t,v_t^*,\omega_t^*,q_t,\dot{q}_t,a_{t-1},\tilde{e}_t) ot=(ωt,pt,vt,vt∗,ωt∗,qt,q˙t,at−1,e~t),其中 ω t \omega_t ωt是机器人本体角速度、 p t p_t pt是重力在机器人本体上的投影, v t v_t vt是机器人本体线速度。
世界模型
采用变分自编码器,通过潜变量 z t z_t zt建立噪声传感器观测值 o 1 : t o_{1:t} o1:t和特权状态 s t p s_t^p stp之间的概率映射。优化evidence lower bound(ELBO):
L E L B O = E q ϕ s ( z t ∣ o 1 : t ) [ l o g ( p ψ s ( s t p ∣ z t ) ) ] − β D K L ( q ϕ s ( z t ∣ o 1 : t ) ∣ ∣ p ( z t ) ) \mathcal{L}_{ELBO}=\mathbb{E}_{q_{\phi_{s}}(z_t|o_{1:t})}[log(p_{\psi_s}(s_t^p|z_t))]-\beta D_{KL}(q_{\phi_s}(z_t|o_{1:t})||p(z_t)) LELBO=Eqϕs(zt∣o1:t)[log(pψs(stp∣zt))]−βDKL(qϕs(zt∣o1:t)∣∣p(zt))
其中 q ϕ s q_{\phi_s} qϕs为编码器,将管测试压缩为服从高斯分布的潜变量 z t ∼ N ( μ ϕ s , Σ ϕ s ) z_t\sim \mathcal{N}(\mu_{\phi_s},\Sigma_{\phi_s}) zt∼N(μϕs,Σϕs),而 p ψ s p_{\psi_s} pψs为解压器,用于重构特权状态。权重系数 β \beta β符合如下公式:
β = m i n ( 0.5 , 0.01 + 1 × 1 0 − 5 ⋅ t ) \beta=min(0.5, 0.01+1\times 10^{-5}\cdot t) β=min(0.5,0.01+1×10−5⋅t)
其中t表示训练步长。在推理过程中,行走策略 π ξ s \pi_{\xi_s} πξs基于编码的统计信息 μ ϕ s ( o 1 : t ) \mu_{\phi_s}(o_{1:t}) μϕs(o1:t)生成确定性动作 a t a_t at,而训练过程中则是对潜变量 z t z_t zt进行采样以增强鲁棒性。
模仿Oracle策略
使用Dataset Aggregation (DAgger) 通过迭代数据重新标记来进行行为克隆。具体而言,在每次迭代 k k k时,通过并行执行学生策略 π ξ s \pi_{\xi_s} πξs来收集轨迹 τ ( k ) = ( o t . a t t e a c h e r ) t = 1 T \tau^{(k)}=(o_t.a_t^{teacher})_{t=1}^{T} τ(k)=(ot.atteacher)t=1T,同时记录教师策略的动作 a t t e a c h e r = π t e a c h e r ( o t p ) a_t^{teacher}=\pi^{teacher}(o_t^p) atteacher=πteacher(otp)。目标是最小化学生和教师动作之间的均方误差:
L i m i t a t i o n = E ( o t , a t t e a c h e r ) ∼ D [ ∣ ∣ π ξ s ( o t ) − a t t e a c h e r ∣ ∣ 2 2 ] \mathcal{L}_{imitation}=\mathbb{E}_{(o_t,a_t^{teacher})\sim \mathcal{D}}[||\pi_{ \xi_s}(o_t)-a_t^{teacher}||_2^2] Limitation=E(ot,atteacher)∼D[∣∣πξs(ot)−atteacher∣∣22]
其中 D = ∪ i = 1 k τ ( i ) \mathcal{D}=\cup _{i=1}^k \tau^{(i)} D=∪i=1kτ(i)表示包含先前所有的迭代数据集。
损失函数
学生的策略训练损失函数结合了变分推理和行为克隆:
L s t u d e n t = L i m i t a t i o n + λ L E L B O \mathcal{L}_{student}=\mathcal{L}_{imitation}+\lambda \mathcal{L}_{ELBO} Lstudent=Limitation+λLELBO
其中 λ = 0.5 \lambda=0.5 λ=0.5。
域随机化
为弥合Sim2Real的Gap并增强策略的稳健性,实现了一个全面的域随机化框架,该框架考虑了传感器噪声和地形的形变。
对于地形,高度图 ε ^ t ∈ R H × W \hat{\varepsilon} _t\in \mathbb{R}^{H\times W} ε^t∈RH×W在时间t被建模为
ε ^ t = α ⊙ ε t + β + ϵ t \hat{\varepsilon}_t=\alpha \odot \varepsilon_t+\beta+\epsilon_t ε^t=α⊙εt+β+ϵt
其中 ε t \varepsilon_t εt为地面真实高度图, α ∼ U [ 0.8 , 1.2 ] \alpha \sim \mathcal{U}[0.8,1.2] α∼U[0.8,1.2]为乘法噪声系数, β ∼ N ( 0 , 0.0 5 2 ) \beta \sim \mathcal{N}(0, 0.05^2) β∼N(0,0.052)表示持续的地形形变, ϵ t ∼ G P ( 0 , k ( l ) ) \epsilon_t \sim \mathcal{G}\mathcal{P}(0, k(l)) ϵt∼GP(0,k(l))是均值为0的高斯过程,使用Matérn核 k ( l ) k(l) k(l)来模拟空间相关噪声。
学生策略架构
学生策略引入了变分信息用于传感器去噪,处理噪声触感器历史和形变地形:
f
t
n
o
i
s
y
=
T
θ
s
(
e
~
t
)
f_t^{noisy}=T_{\theta_s}(\tilde{e} _t)
ftnoisy=Tθs(e~t)
h
t
=
B
i
L
S
T
M
(
[
o
1
:
t
n
o
i
s
y
;
f
1
:
t
n
o
i
s
y
]
)
h_t=BiLSTM([o_{1:t}^{noisy};f_{1:t}^{noisy}])
ht=BiLSTM([o1:tnoisy;f1:tnoisy])
μ
t
,
σ
t
=
M
L
P
μ
(
h
t
)
,
M
L
P
σ
(
h
t
)
\mu_t,\sigma_t=MLP_\mu(h_t),MLP_\sigma(h_t)
μt,σt=MLPμ(ht),MLPσ(ht)
z
t
∼
N
(
μ
t
,
d
i
a
g
(
σ
t
2
)
)
z_t \sim \mathcal{N}(\mu_t,diag(\sigma_t^2))
zt∼N(μt,diag(σt2))
s
^
t
p
=
p
ψ
s
(
z
t
)
\hat{s}_t^p=p_{\psi_s}(z_t)
s^tp=pψs(zt)
a
t
=
π
ψ
s
(
z
t
)
a_t=\pi_{\psi_s}(z_t)
at=πψs(zt)
实验结果
请阅读原文。

















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









