







一、背景
CLIP模型是在人工智能领域,特别是计算机视觉和自然语言处理交叉领域的一次重要突破。传统的计算机视觉模型通常依赖于大规模标注数据,并且在新任务或新领域的应用中存在局限性。为了打破这一局限,OpenAI提出了CLIP模型,旨在通过对比学习的方式,利用互联网中自然存在的图像-文本对,减少了对大量人工标注的需求,实现了图像和文本的联合表示学习。
二、原理
CLIP模型的核心原理是对比学习。它使用大规模的图像-文本对数据集进行预训练,这些数据集包含了丰富的图像和对应的描述文本。在训练过程中,CLIP模型通过计算图像和文本的特征向量,并比较它们之间的相似度,来优化模型参数。具体来说,对于每个批次中的图像-文本对,模型会计算图像和文本的特征向量,并计算它们之间的相似度(通常使用余弦相似度)。然后,通过对比损失函数来优化模型参数,使得匹配的图像-文本对的相似度最大化,而不匹配的则最小化。这种学习方式使得CLIP模型能够学习到更加泛化的图像和文本表示。
三、模型结构
CLIP模型主要由两个核心组件构成:图像编码器和文本编码器。
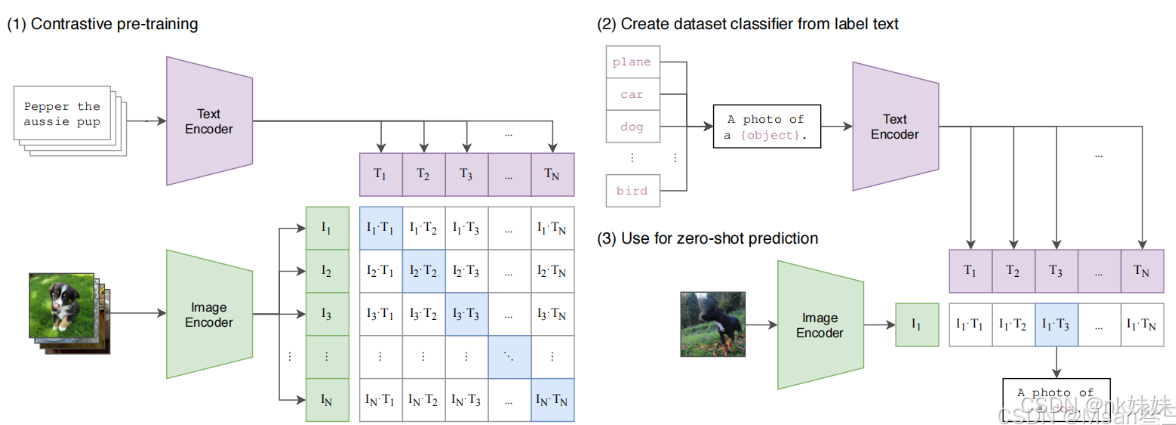
图像编码器:负责将图像转换为特征向量。它可以是卷积神经网络(如ResNet)或Transformer模型(如ViT)。这些架构能够捕捉图像中的关键特征,并将其转换为可用于后续计算的向量形式。
文本编码器:负责将文本转换为特征向量。它通常采用Transformer模型,能够处理长距离的依赖关系,并生成与图像向量相对应的文本向量。
这两个编码器通过共享一个向量空间来实现跨模态的信息交互与融合,使得相关的图像和文本在向量空间中相互靠近,而不相关的则远离。
四、训练过程
CLIP模型的训练过程包括以下几个阶段:
1.数据收集与预处理:从互联网上收集大规模的图像-文本对数据集,并进行预处理,如图像缩放、文本清洗等。
2.模型初始化:初始化图像编码器和文本编码器的参数。
3.对比学习训练:使用对比损失函数作为优化目标,通过迭代训练来优化模型参数。在每次迭代中,模型会计算每个批次中图像和文本的特征向量,并计算它们之间的相似度。然后,通过对比损失函数来更新模型参数,使得匹配的图像-文本对的相似度最大化,而不匹配的则最小化。
4.模型评估与调优:在训练过程中,定期评估模型的性能,并根据评估结果进行调优。
五、应用场景
1.图像分类:通过计算图像与文本描述之间的相似度,实现零样本或少量样本的图像分类。这种能力使得CLIP模型能够轻松迁移到各种下游任务中,如医学影像分类、植物识别等。
2.图像检索:根据文本描述从一组图像中找到最匹配的图像,适用于视觉搜索、内容推荐等场景。例如,用户可以通过输入描述性文本来搜索相关的图片或视频。
3.文本到图像生成:与生成模型结合,根据给定的文本描述生成高质量图像。这种能力在艺术创作、游戏设计等领域具有广泛的应用前景。
4.多模态理解:在视觉问答、图像字幕生成等任务中发挥作用,具备跨模态的理解能力。例如,模型可以根据图像内容生成相应的文字描述或回答相关问题。

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









