







 本文深入解析了三种集成学习方法:Bagging、随机森林和AdaBoost的基本步骤与原理。Bagging通过无放回抽样和各类分类器进行投票决策;随机森林在Bagging基础上引入属性随机选择,通常使用CART决策树;AdaBoost则通过调整样本权重和分类器权重实现错误样本的重点关注。
本文深入解析了三种集成学习方法:Bagging、随机森林和AdaBoost的基本步骤与原理。Bagging通过无放回抽样和各类分类器进行投票决策;随机森林在Bagging基础上引入属性随机选择,通常使用CART决策树;AdaBoost则通过调整样本权重和分类器权重实现错误样本的重点关注。
一、bagging
基本步骤:
① 从样本集中无放回的抽样选出n个样本;
② 在所有属性上,对这n个样本建立分类器(此分类器可以是ID3, C4.5, CART, SVM,Logistic回归等);
③ 重复上述两步m次,即获得m个分类器;
④ 将预测数据代入到这m个分类其中,根据这m个分类器的结果投票决定数据属于哪一类。
二、随机森林
基本步骤:
① 从样本集中无放回的抽样选出n个样本;
② 从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树;
③ 重复上述两步m次,即建立了m棵CART决策树;
④ 这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类。
可以使用决策树作为基本分类器,也可以使用SVM, Logistic回归等分类器,习惯上这些 分类器组成的“总分类器”,仍然叫做随机森林。
三、Adaboost
概述: 将前一个分类器分类错误的样本,通过增加其权重,同时减小分类正确的样本权重,来训练下一个分类器;同时给每一个分类器一个权重,分类错误率低的权重高,分类错误率高的权重低,通过线性组合的方式得到最后组合的分类器。AdaBoost方法对于噪声数据和异常数据很敏感。
基本步骤:
设训练数据集为 T={(x1,y1), (x2,y2)…(xN,yN)}
① 初始化训练数据的权值分布:
② 使用具有权值分布的训练数据集学习,得到基本分类器:
③ 计算G1(x)在训练数据集上的分类误差率:
④ 计算G1的系数:
⑤ 更新训练数据数据集的权值分布:
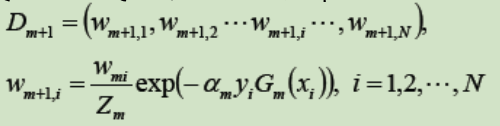
其中Zm为规范化因子:
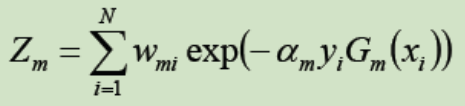
它的目的仅仅是使Dm+1成为一个概率分布。
⑥ 利用⑤更新的训练集的权值分布,训练下一个分类器G2,然后重复③④⑤
⑦ 构建基本分类器的线性组合:
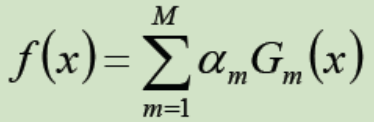
即 f(x) = a1G1(x) + a2G2(x) + … + am*Gm(x)
⑧ 得到最终的分类器:
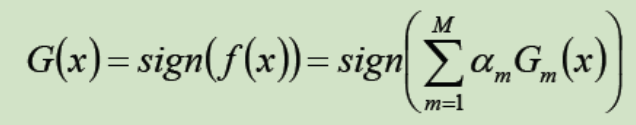

















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









