






讲的是RNN:
1.RNN的基本概念:有记忆的neural network
案例:slot分类,比如地点啊,时间啊
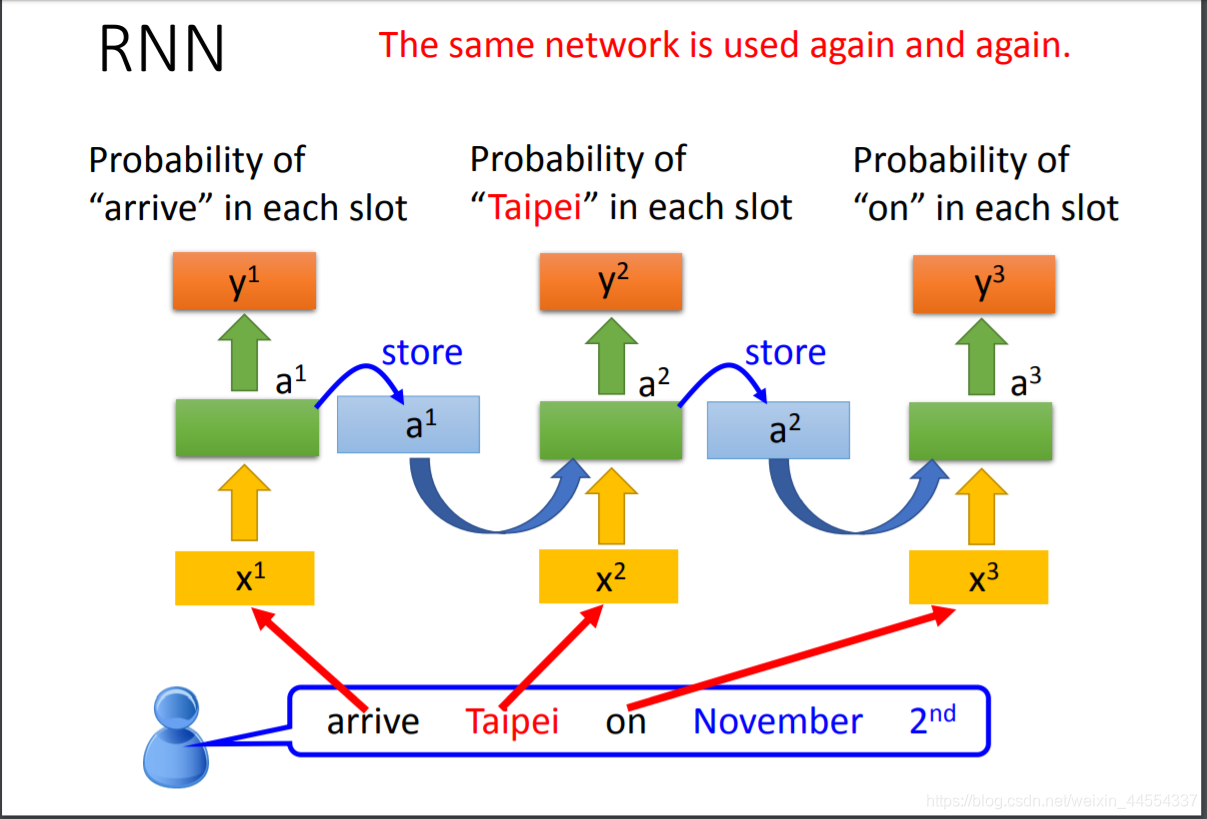
有个订票系统,Slot Filling,听到用户说: I would like to arrive Taipei on November 2nd. 时,Slot Filling, 即识别出语音中 Taipei 对应 Destination 这个slot, November 2nd 属于 Time of arrival 这个slot, 而其它词汇不属于任何slot。
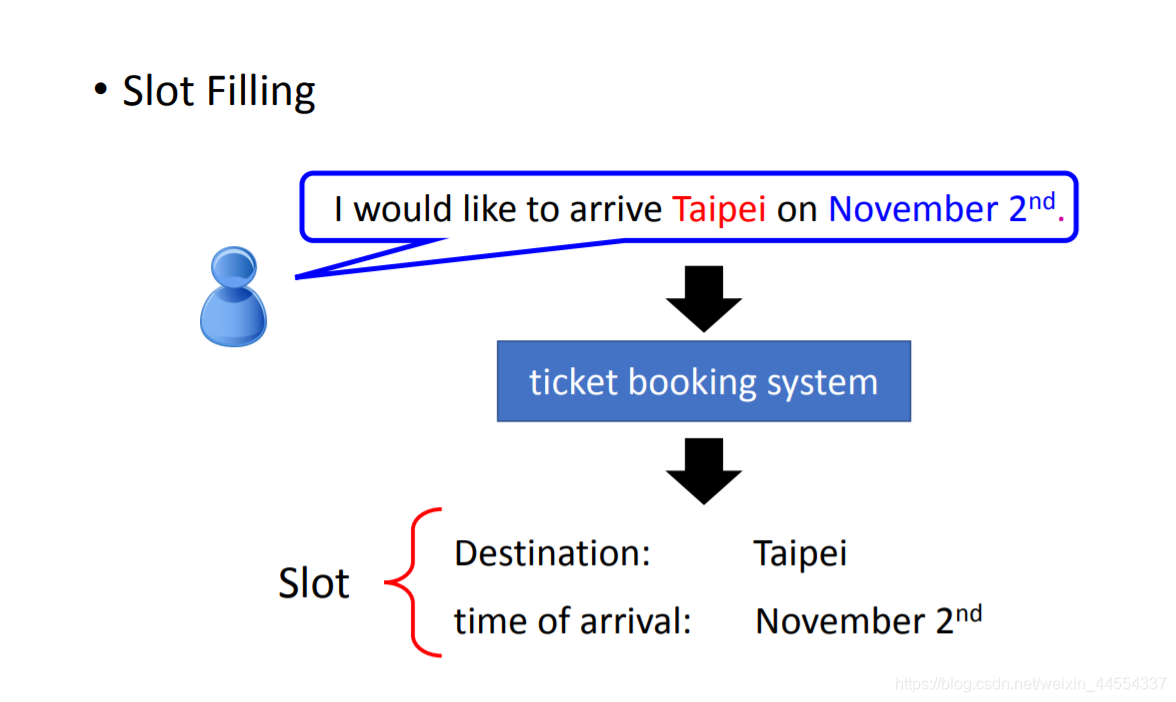
李老师说明:Feedforward network不能解决这个问题,因为Feedforward network是把word变成vector(e.g. 1-of-N encoding, word hashing)作为Feedforward network的输入,输出是该词汇属于slots(Destination, Time of arrival) 的概率,这样远远不够
有很多没有表示过的词汇

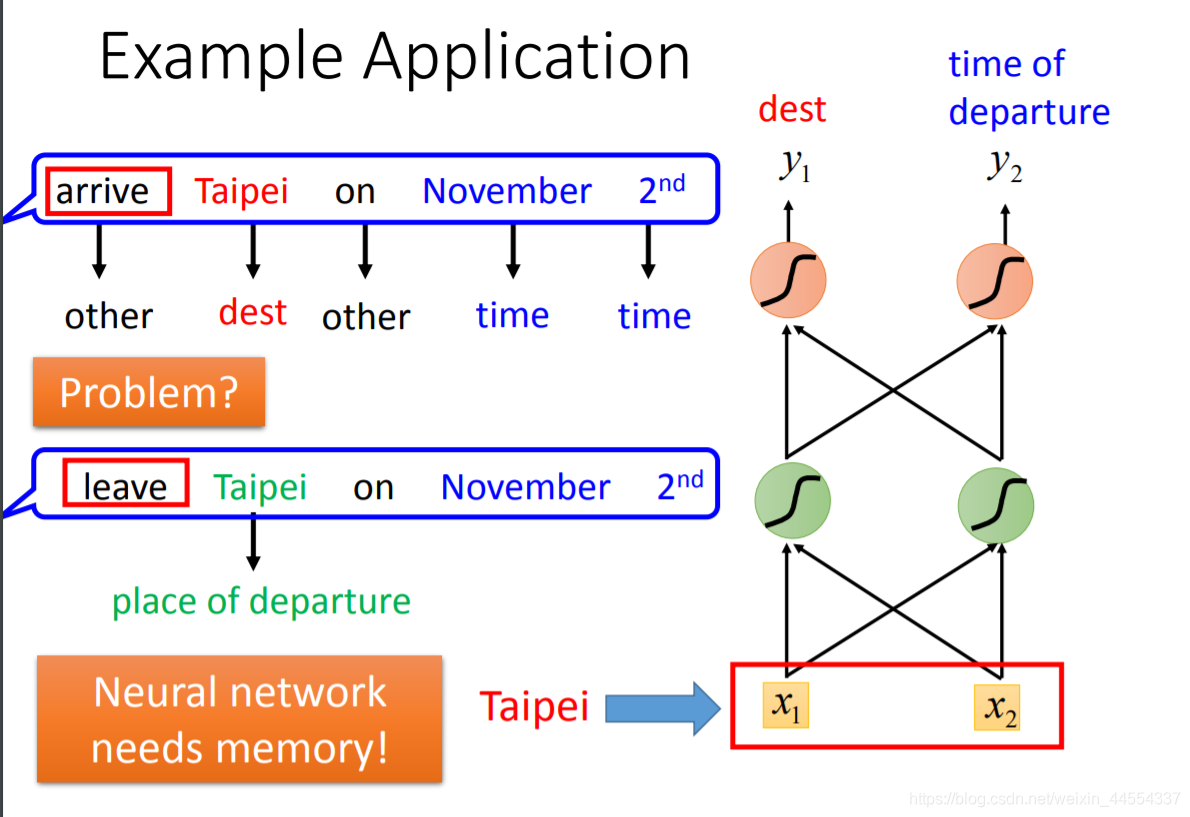
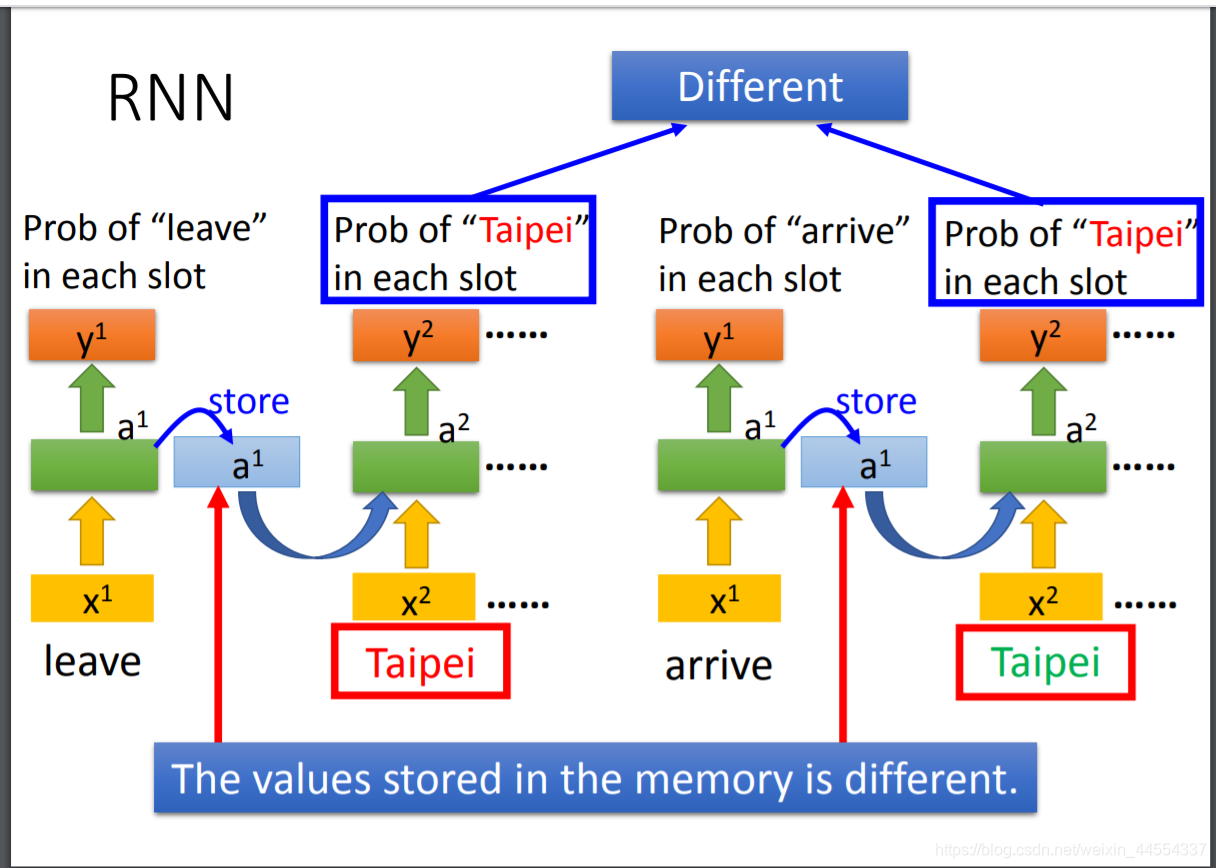
那比如说从台北出发,和到达台北,台北检索的时候不知道是出发还是离开,所以光检测是不够的,还需要有记忆:根据上下文的记忆,产生不同的output
1.1RNN特性
- 因为是以时间为特性的网络架构,所以RNN中,hidden layer 的neuron产生的output会被存放到,memory中,之后的input,hidden layer不知考虑input,还会考虑memory
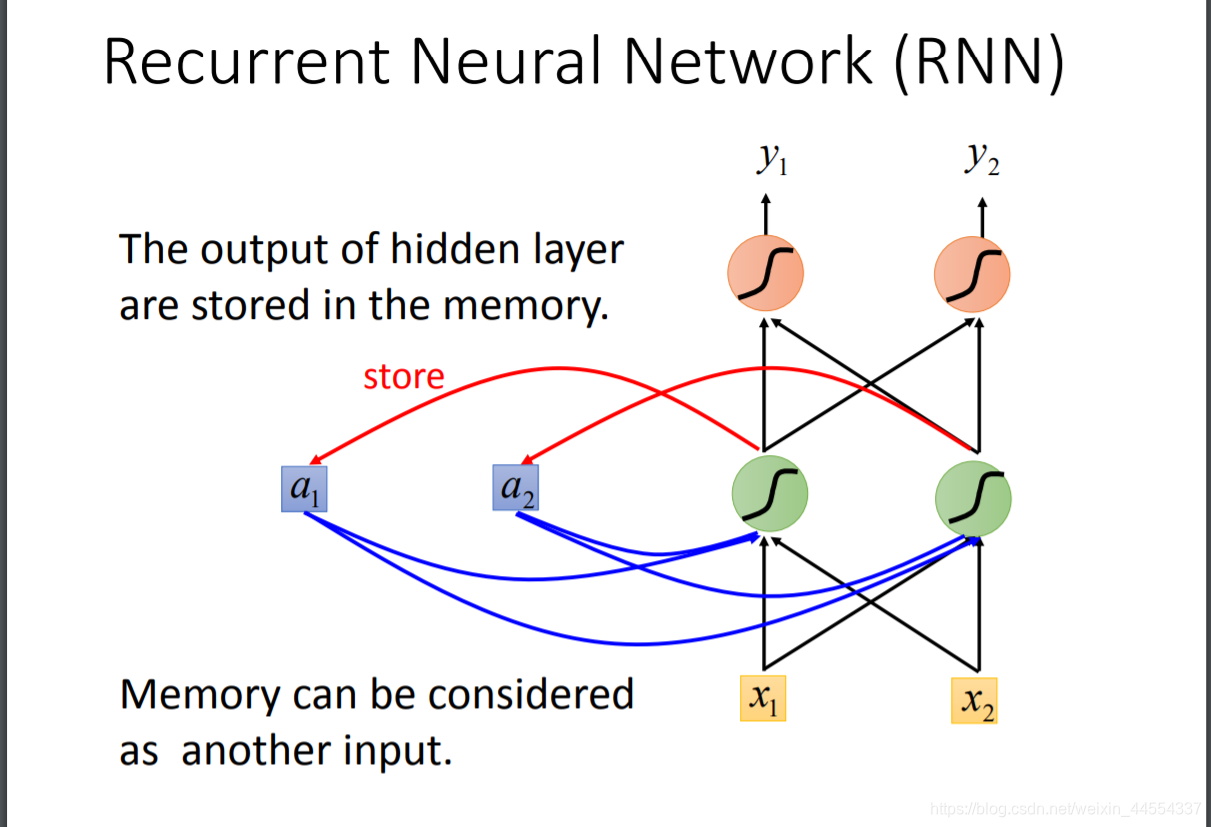
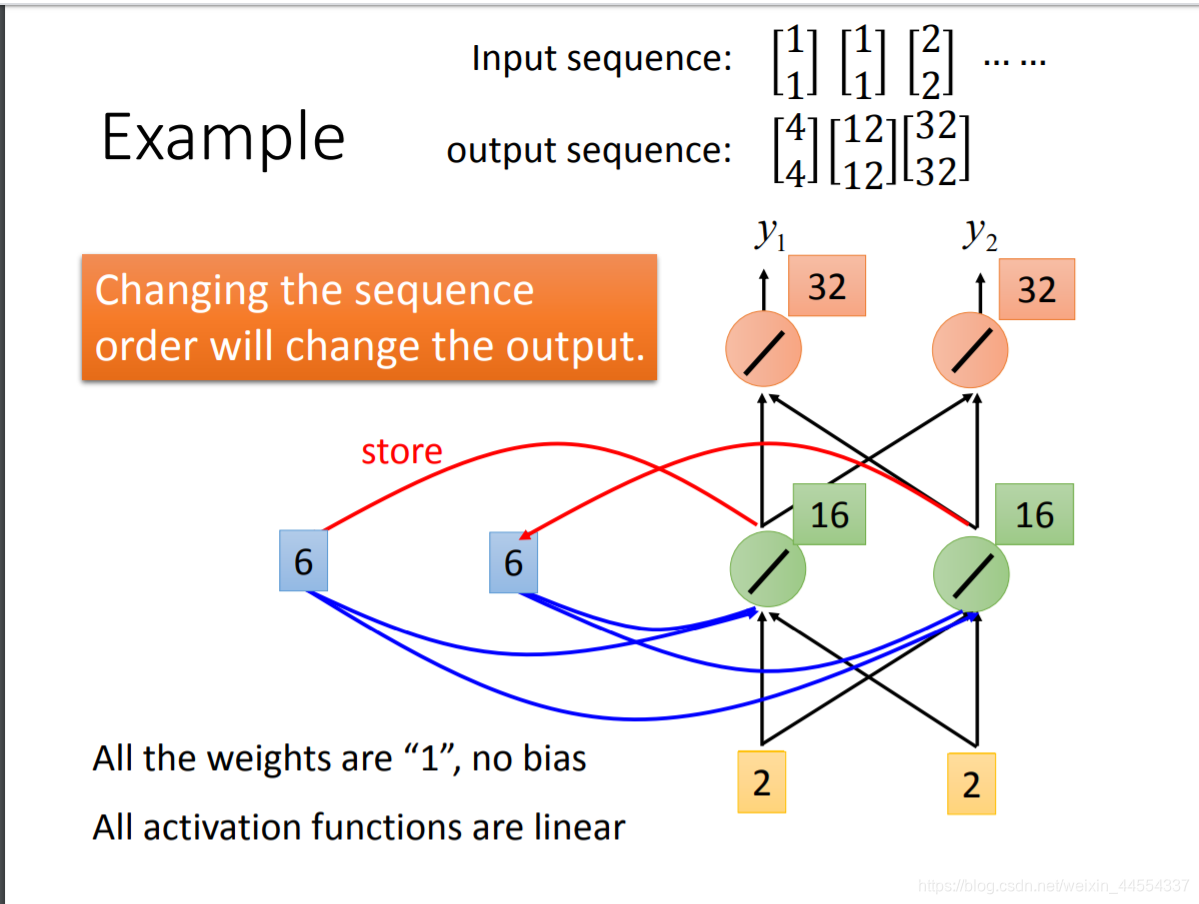
- 另外:RNN会考虑input sequence的order,改变这个input的order,output也会随之改变
比如输入是 1 1加上开始时memory存储的0 0 输出 2 2 相加4 4
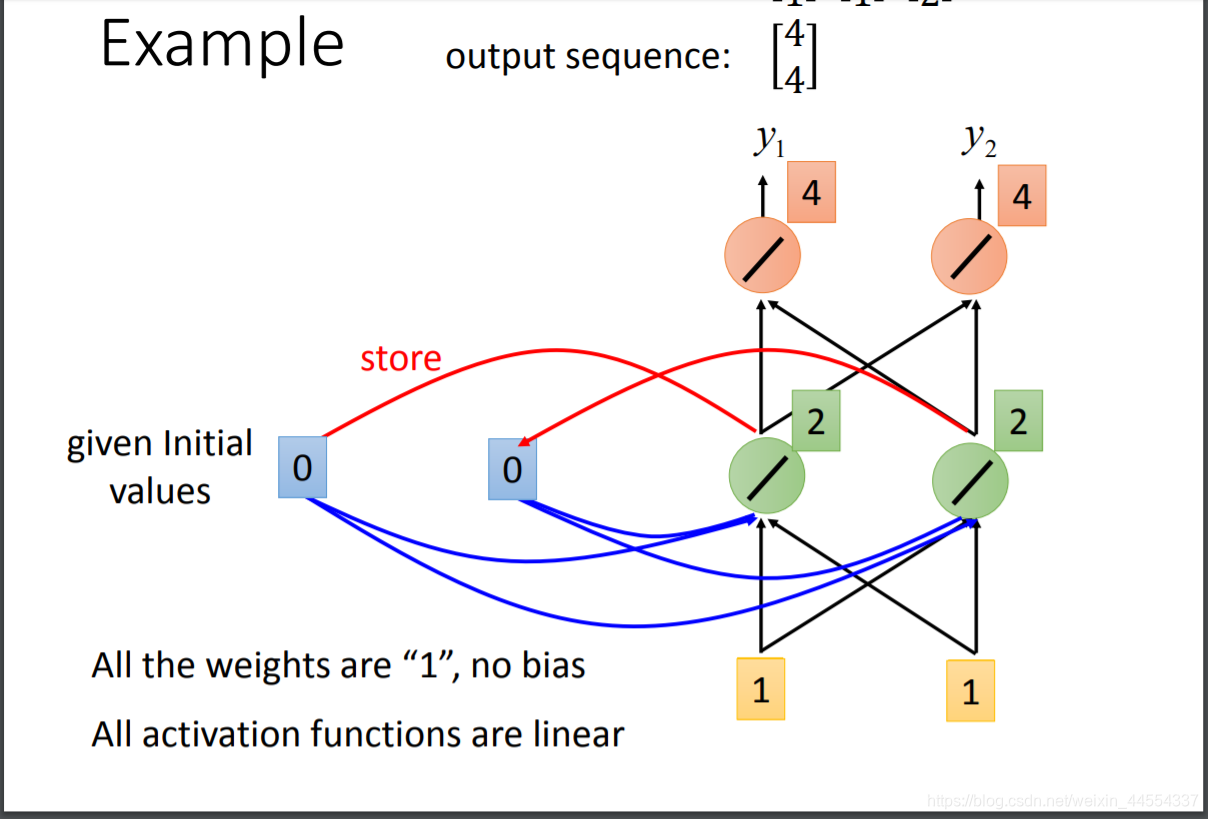
然后再把2 2 写到memory输出6 6相加12 12
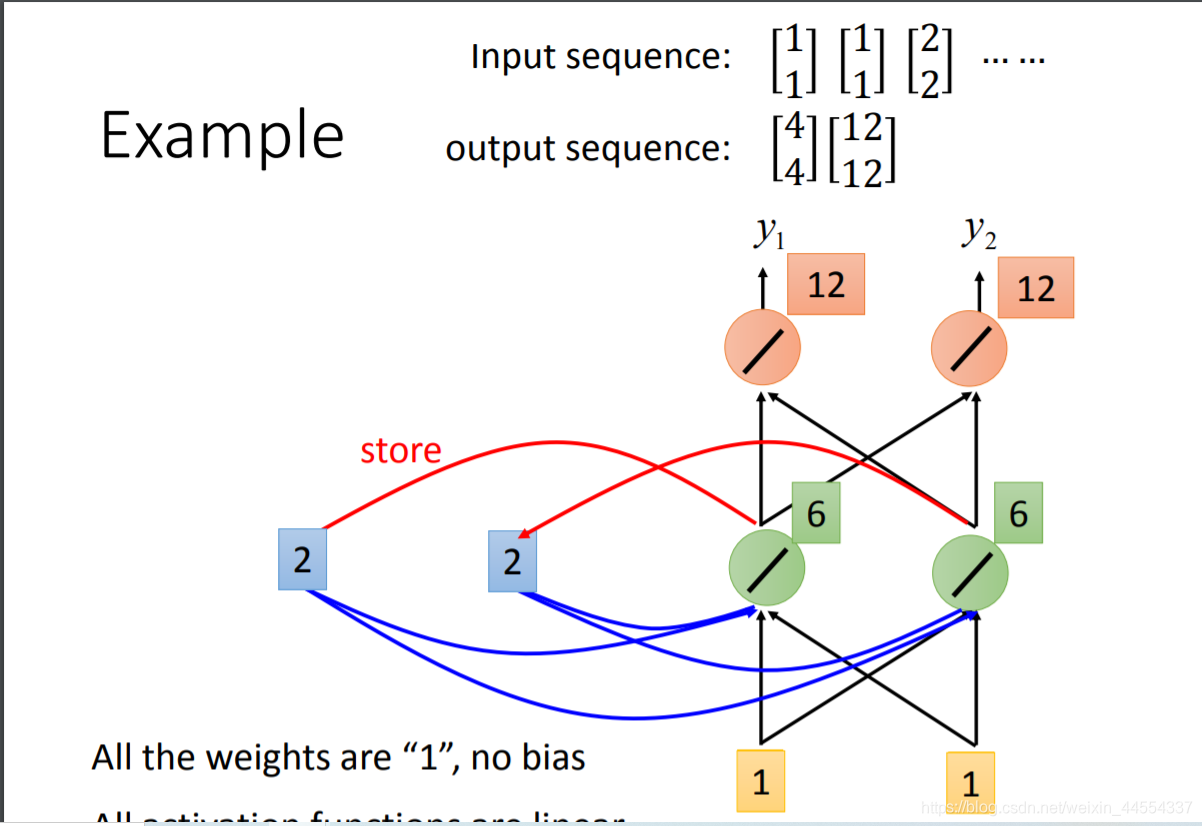
因为memory的值不一样所以同样的输入,可能会不同的输出
arrive先输入进去,然后存到memory。然后Taibei 作为X2 input进去,hidden layer会同时考虑memory 和input
同一个input ,memory ,导致output不同
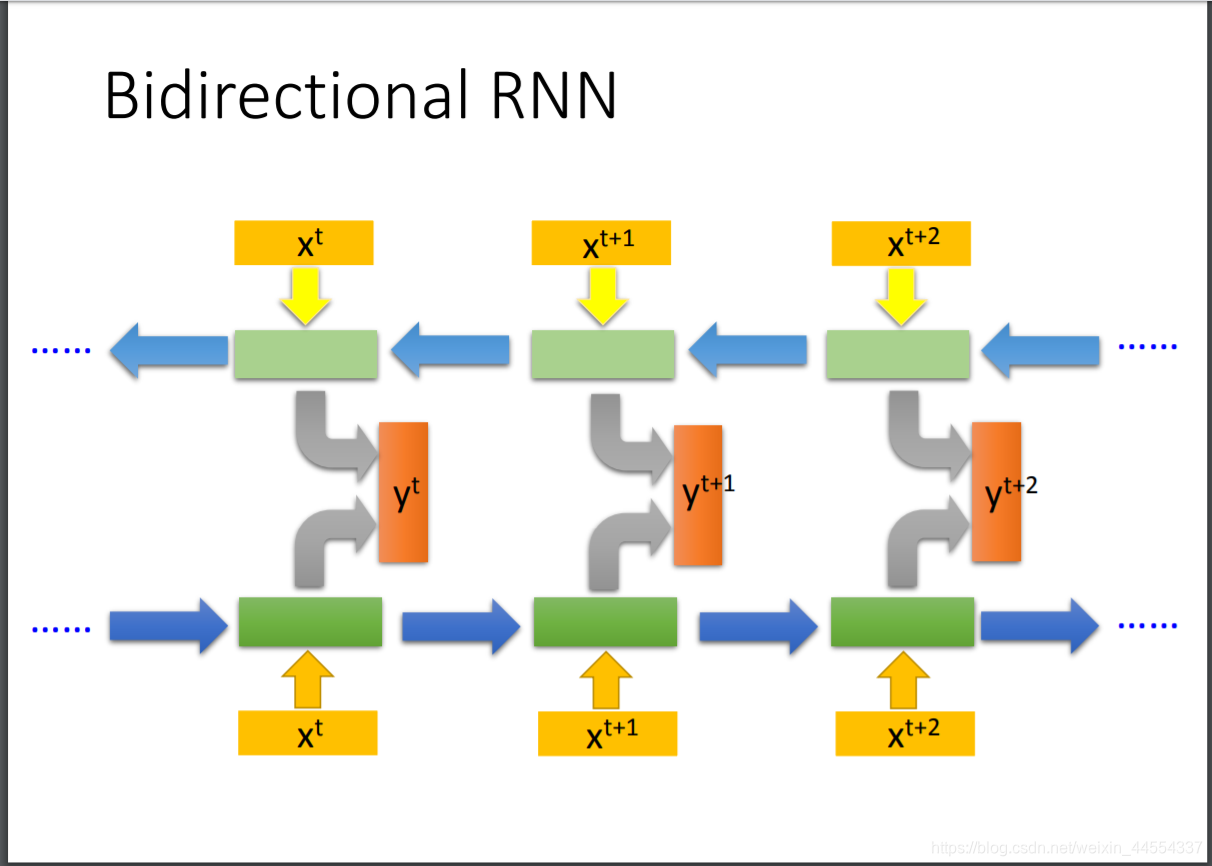
- RNN里面有一个双向的概念,指的是什么呢?就是说input的句子,可以正西读也可以反向读,把两者的hidden layer接到一个output layer上,这样的好处是,output看的范围广,看到整个input sequence
先读xt再读xt+2,也可以反过来,正反方向都丢给yt,看的更远
1.2 听过Jordan Network没
他的performance更好,当然是相比较Elman Network而言,Elman Network里面没有Target,导致有点难控制到底把什么东西放到Memory里面,Jordan是有target的
J是把整个output存进memory,output有target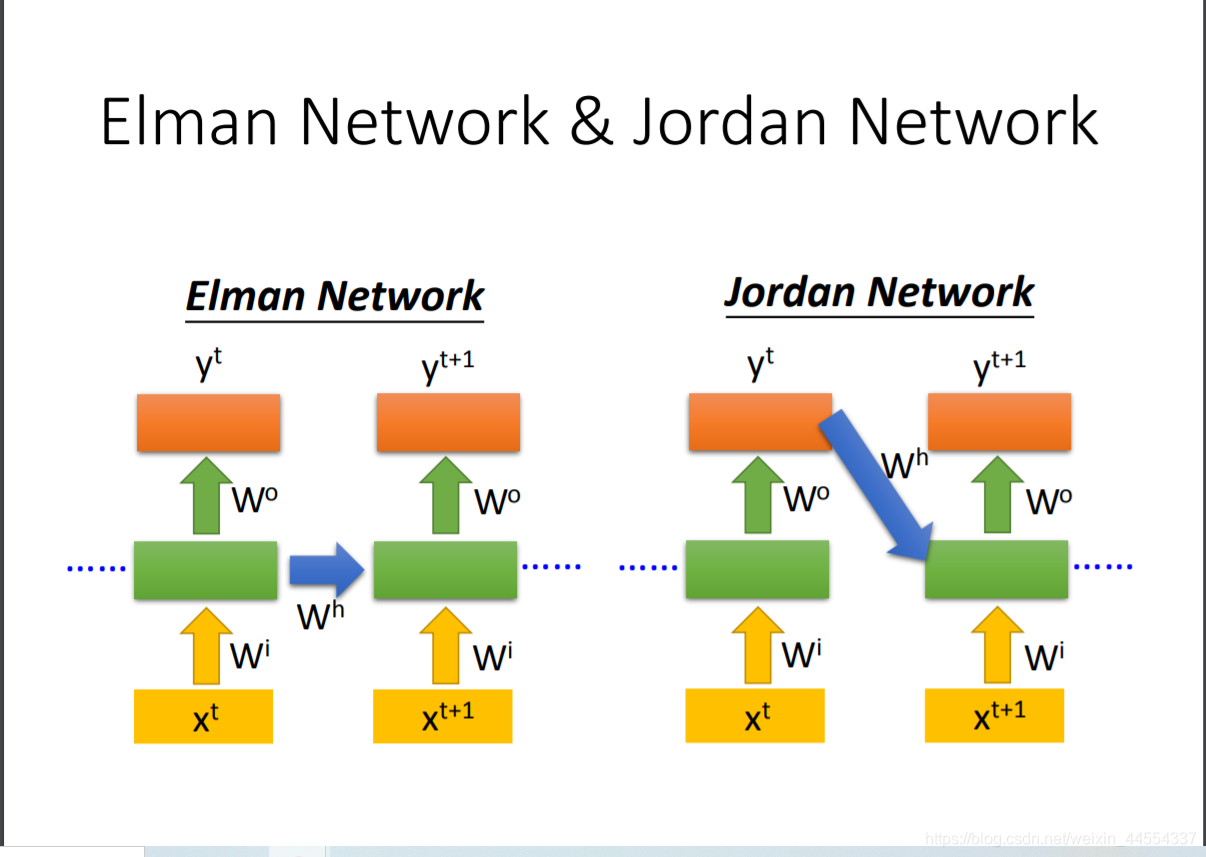
2.LSTM:最常用的RNN
2.1概念:long short-term Memory:
-
经典特征就是三个Gate:input gate,output gate ,forget gate,这三个门的开关都是netural network自己学的,input gate只有开着的时候,才让memory cell 写入东西,forget gate决定memory cell中的那些内容什么时候忘掉
-
另外一个特性就是special neuron:4 input+1 ouput
三个input是控制三个门开关的信号,一个input 是外界想存到memory cell里面的东西,不一定值能存进去
学习什么时候开门,关门,什么时候可以读出来值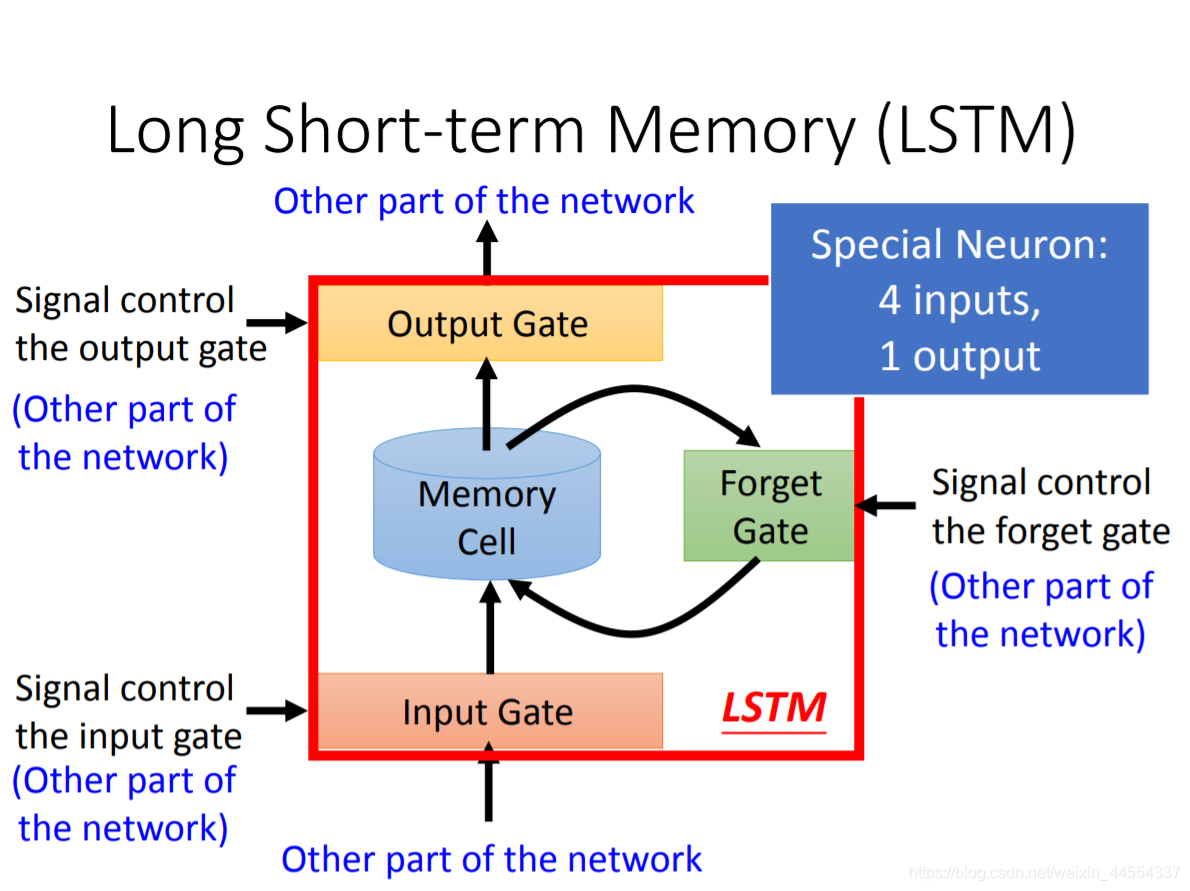
-
相比较传统的RNN,他的特点在long,什么意思呢?传统是short-term memory,每次有新的memory,上一个都会被洗掉,LSTM控制,只要forget gate给的信号是不forget,memory的值就会永久被保存
2.2 还是举例子说明LSTM把
有一个常识就是,0:关,1:开 概率的事情用sigmoid函数知道把
-
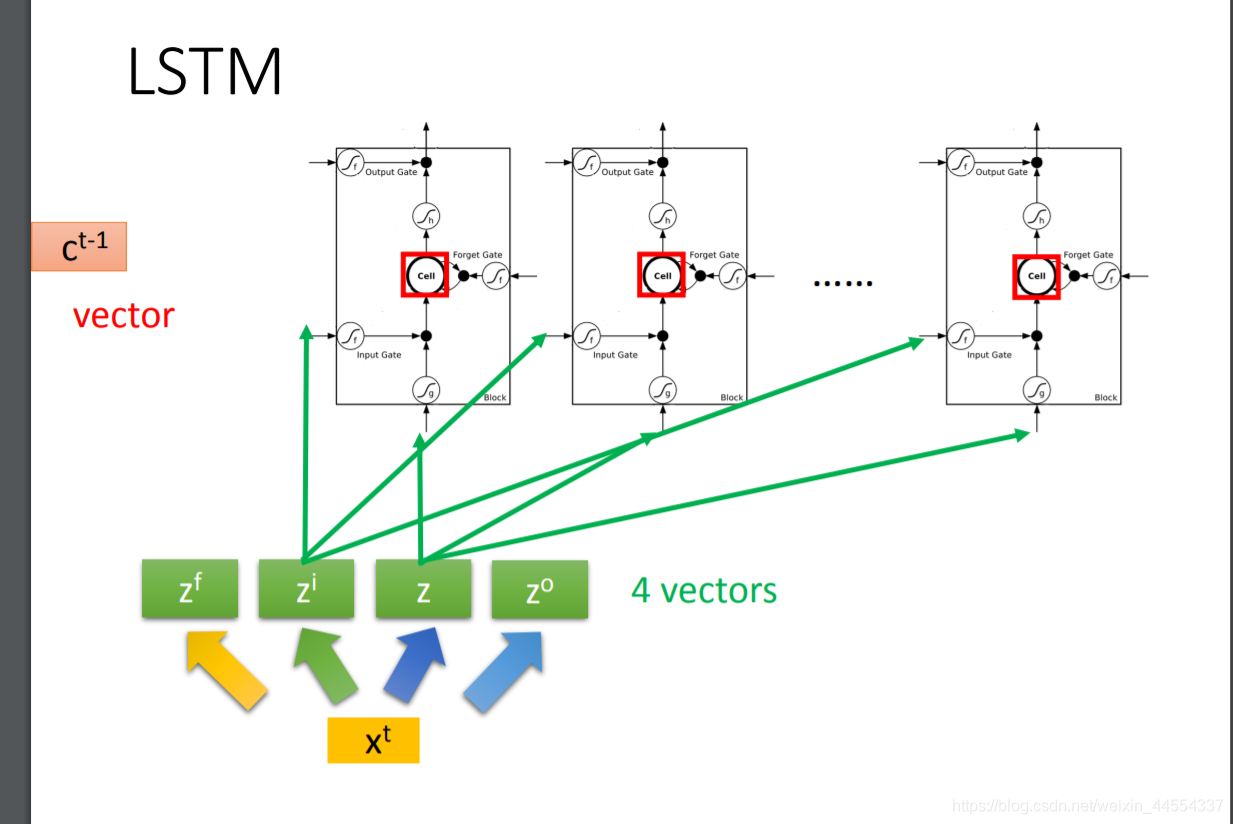
首先是4个scalar Z:zi,zo,zf,z
z是怎么来的呢,input vector和weight vector计算内积+bias来,那weight vector和bias是training data用gradient decent学来的 -
过的f用的是sigmoid函数,输出的0-1表示门开的程度,0:关 1:开
f(zi)=1 时,允许输入; f(zi)=0 时,相当于无输入,f(zo)=1 时,允许输出;f(zo)=0 时,相当于无法输出。f(zf)=1 时,相当于记得memory cell中之前的值cc;f(zf)=0 时,相当于洗掉 memory 。z是需要存入的memory
z和zi两个结合组成input ,
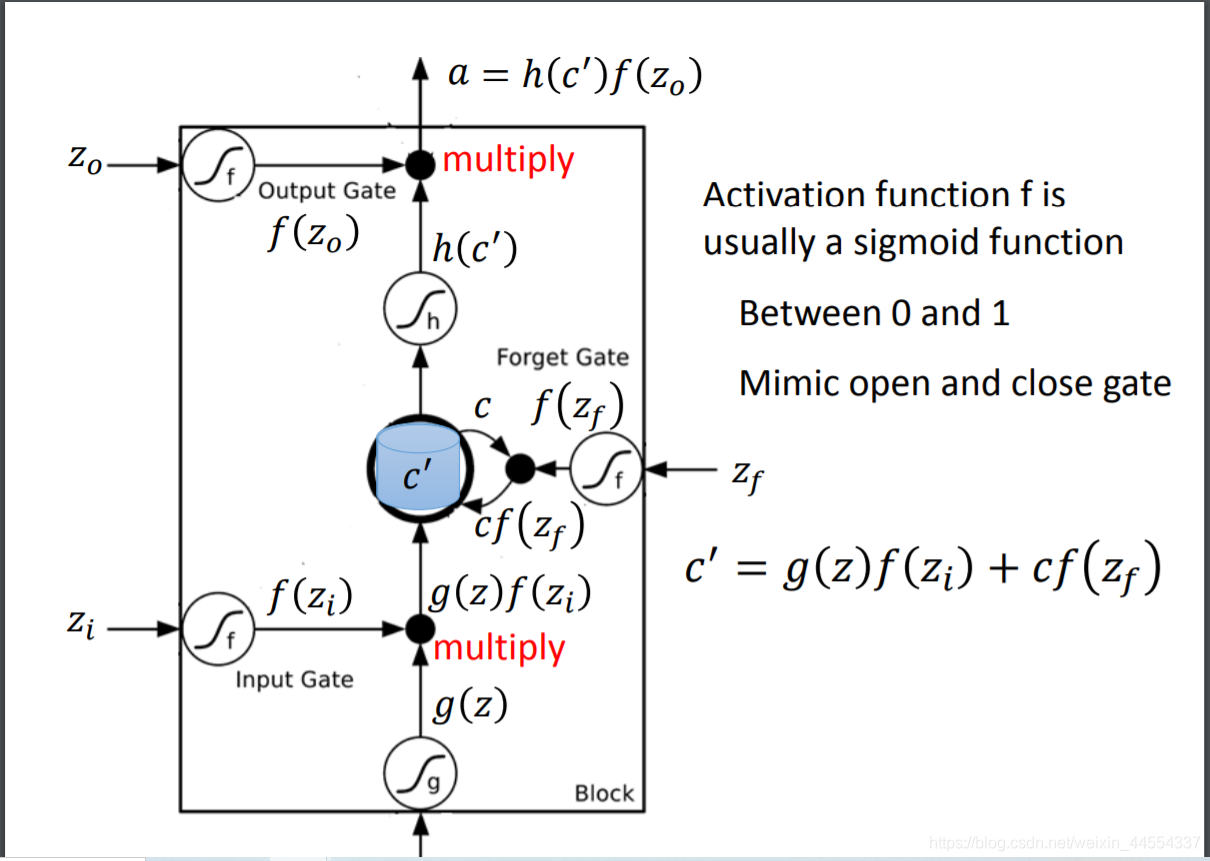
input都是三维的vector,ouput都是一维的
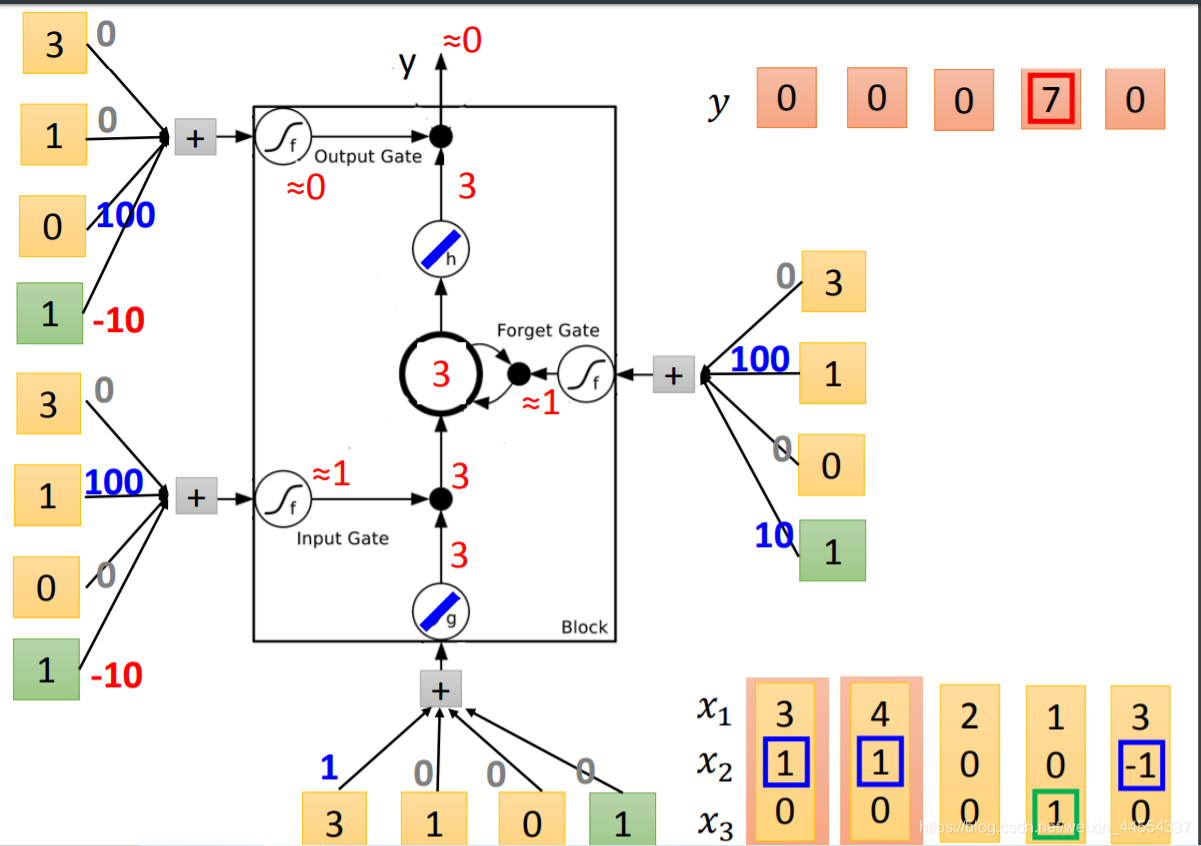
当x2是1,写3 memory 4 得到7
当先x2是-1,重置memory 为0
当x3是1,输出 7被输出

三维乘三个weight+bias得到input
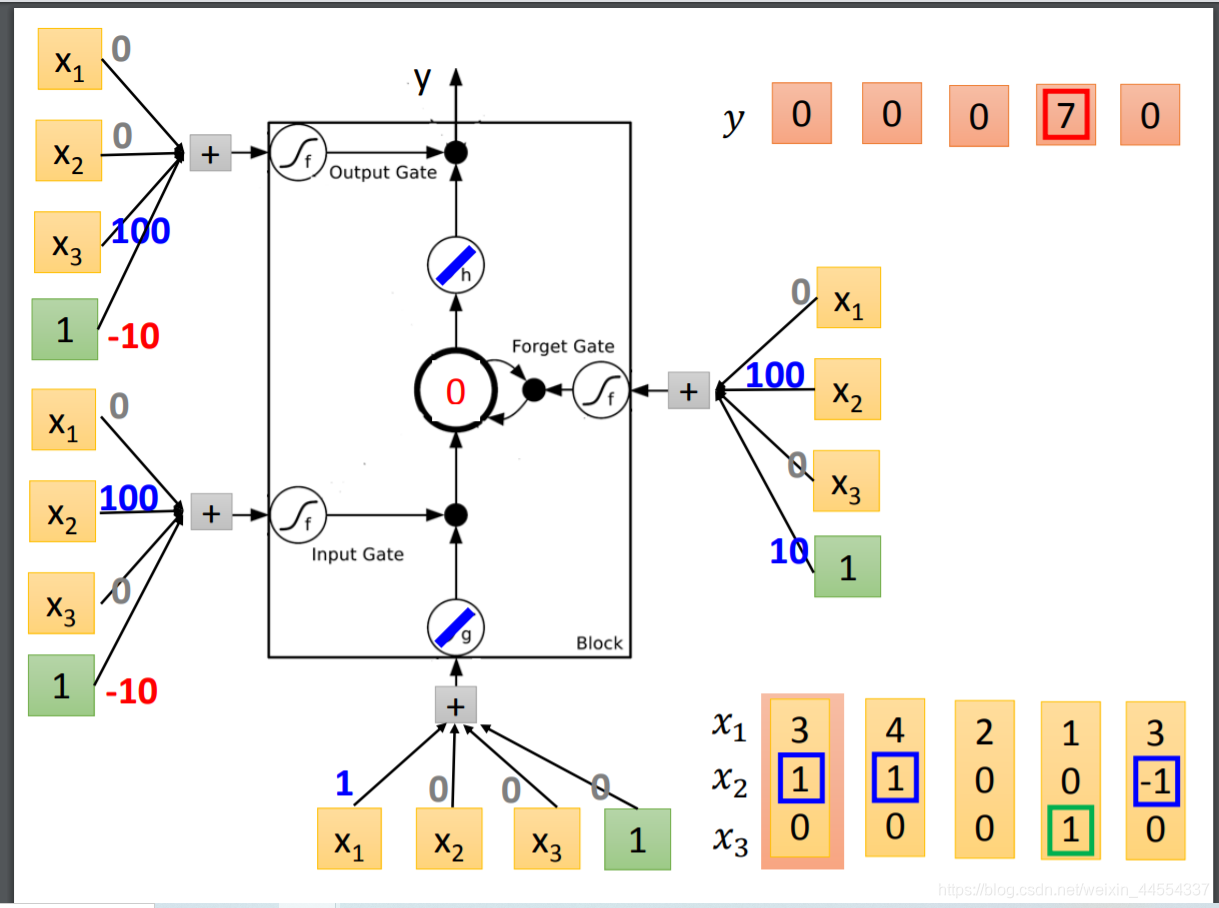
看懂这个图,memory和output
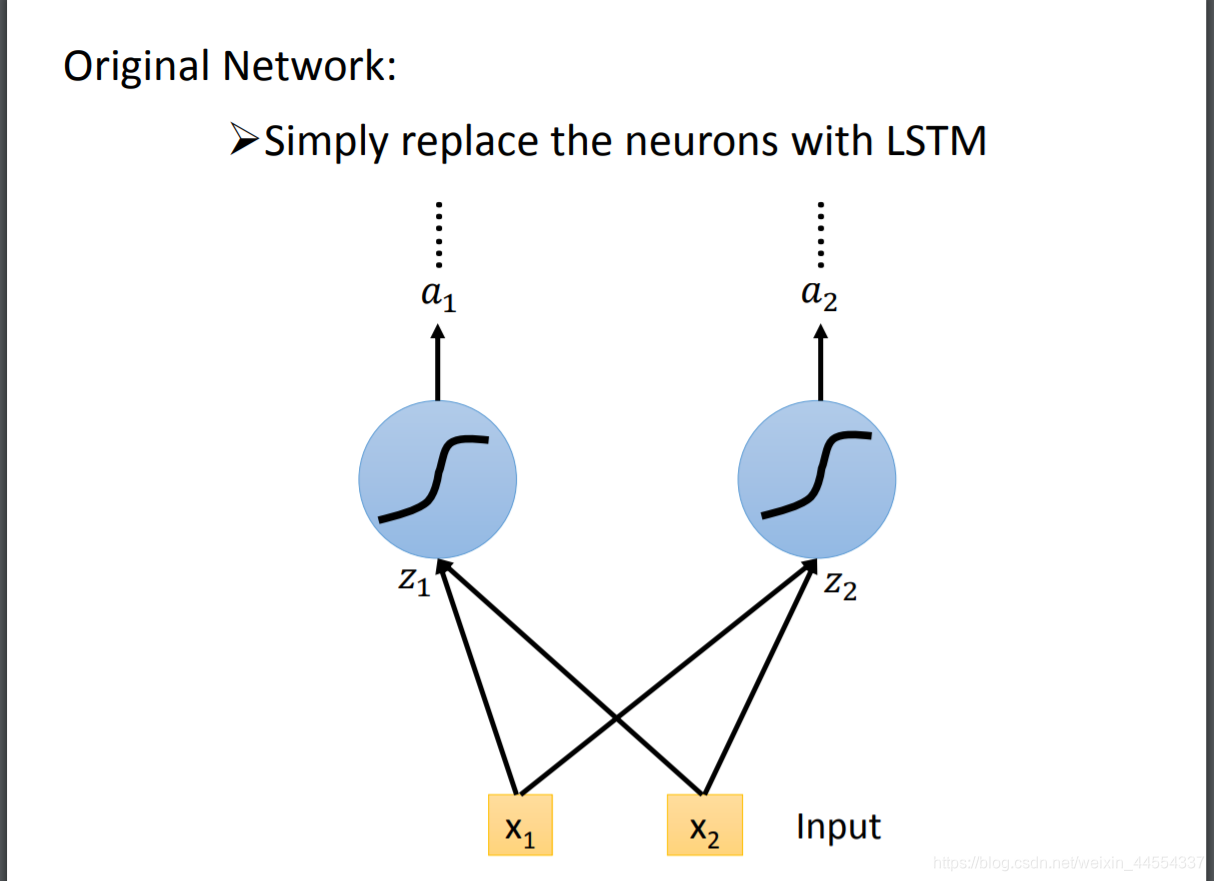
2.3:把LSTM放到netural network里
-
你知道LSTM在哪个位置嘛?在x和a之间
参数量变成了原来的4倍
假设有两个netural,两个分别的4个input都不一样,所以参数量是四倍
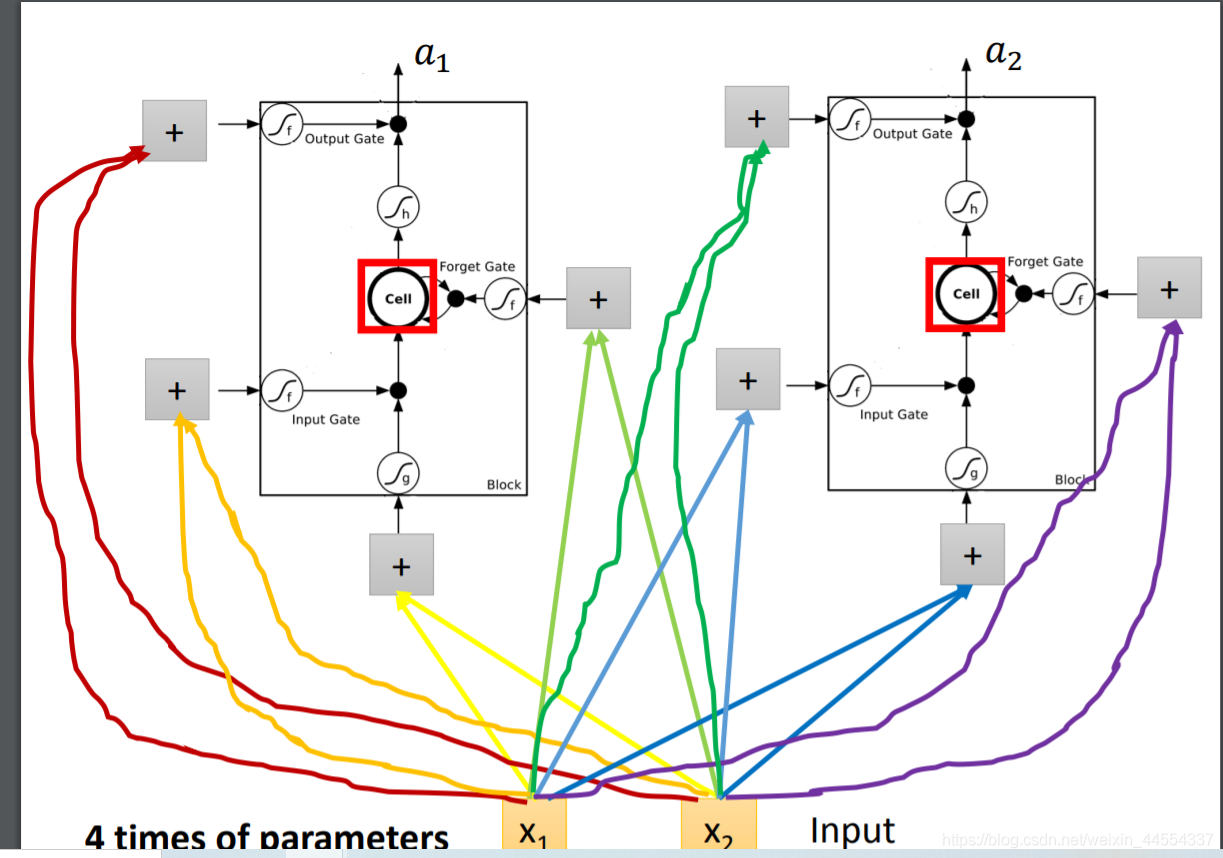
一排netural z zi zo zf都是三维,合起来操控运作
-
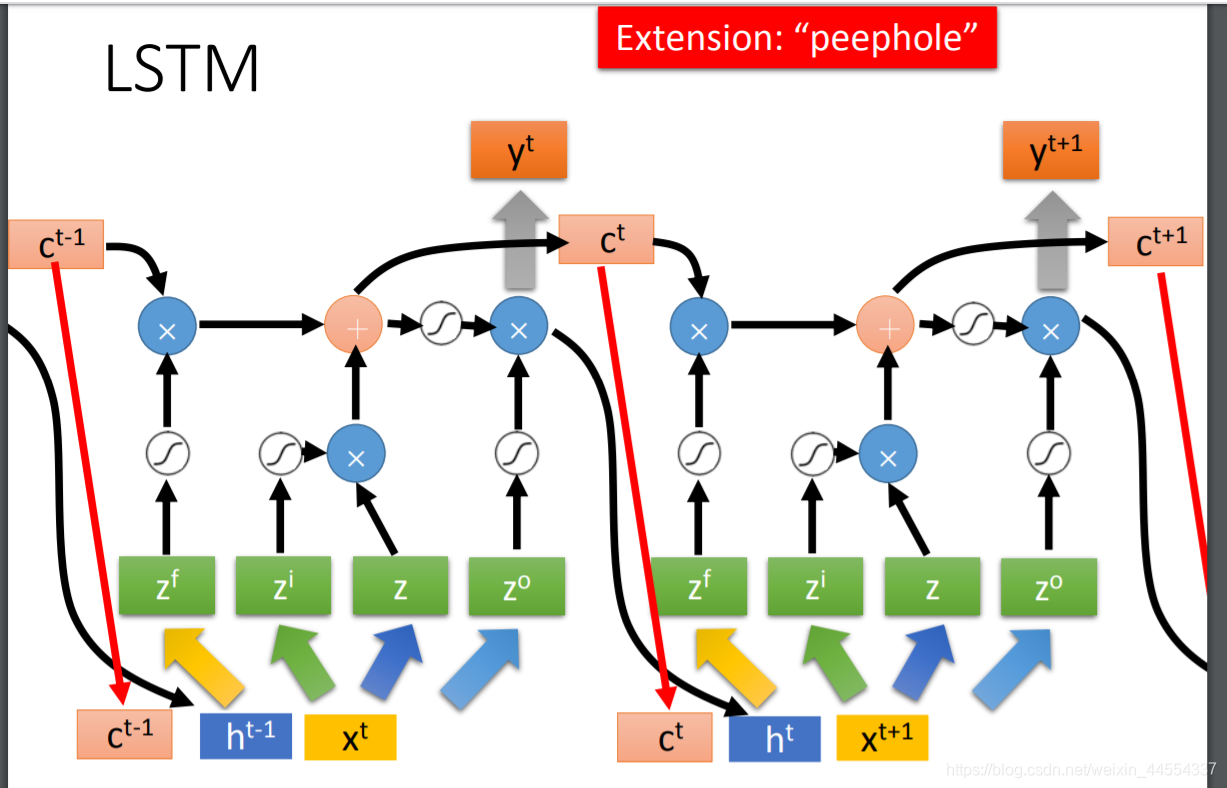
把每个LSTM在时刻t的output ht 接到该LSTM在下一时刻的输入,同时所谓peephole的意思是把前一时刻memory cell中的值也拉到下一时刻的input中。即,操控LSTM4个input z,zi,zf,zo,z,时同时考虑了xt+1,ht,ct
-
Multiple-layer LSTM:多层是必然的,前一层各LSTM输出的ht 作为下一层对应LSTM的输入xt.
-
Keras:Keras支持三种RNN,LSTM, GRU,SimpleRNN
GRU:LSTM的改进,两个gate,减少了参数避免了过拟合,performance与LSTM差不多


















 1869
1869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









