







1、什么是爬虫
从程序猿的角度来说,爬虫就是写程序,然后去互联网上抓取数据的过程。爬虫可以形象理解为在互联网这个网络上爬来爬去的一只蜘蛛,当遇到一些网站资源时,蜘蛛就会把它们爬取下来。很多语言都可以实现爬虫,例如java,ph,c,c++,但是pyhon语言语法简单,代码优美,而且具有强大的scrapy框架,更适合做爬虫
2、涉及到的内容
(1)一些库~
有urllib、requests、bs4…这些
(2)解析网页内容
正则表达式、bs4、xpath、jsonpath
(3)动态html
selenium+phantomjs、chromeheadless
(4)scrapy框架
(5)scrapy-redis组件
redis,分布式爬虫
(6)爬虫-反爬虫-反反爬虫的一些内容
UA、代码、验证码、动态页面等
3、爬虫基本流程
~发送请求
通过http库向目标站点发送请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
~获取响应内容
如果服务器能正常响应,会得到一个response,response的内容便是所要获取的页面内容,类型可能有html、json字符串、二进制数据(如图片视频)等类型
~解析内容
得到的内容可能是html,可以用正则表达式、网页解析库进行解析,可能是二进制数据,可以做保存或进一步的处理
~保存数据
保存形式多样,可以存为文本,也可以保存至数据库,或者保存为特定格式的文件
4、两种协议 http和https
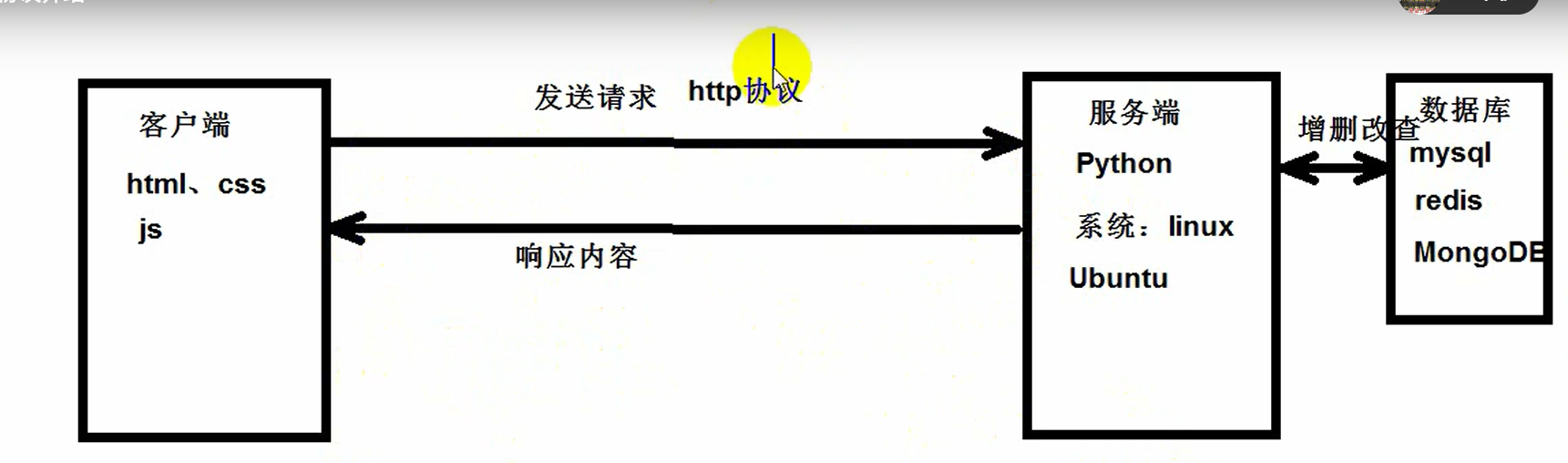
(1)HTTP协议
超文本传输协议,被用于在web浏览器和网站服务器之间传递信息,以明文形式发送内容,不对数据进行任何加密,http协议不适合传送一些敏感信息,比如信用卡号、密码等,这是因为如果攻击者截取了web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息
(2)HTTPS协议
是http协议的安全版,https在http协议的基础上加入了ssl协议,ssl依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密
(3)两种协议的区别
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
详情见:https://www.cnblogs.com/wqhwe/p/5407468.html
(4)了解http协议
http请求

~请求行:
图中请求行中的get是请求方式,请求方式常见的有 get和post,如果用户没有设置,默认情况下浏览器向服务器发送的都是get请求。不管POST或GET,都用于向服务器请求某个WEB资源,这两种方式的区别主要表现在数据传递上。
如果请求方式为GET方式,则可以在请求的URL地址后以?的形式带上交给服务器的数据,多个数据之间以&进行分隔,例如:GET /mail/1.html?name=abc&password=xyz HTTP/1.1 但是在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。
如果请求方式为POST方式,则是在请求的实体内容中向服务器发送数据,post请求方式传送的数据量无限制。
~请求头:(要求掌握)
HTTP请求中的常用消息头如下:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
~请求内容:
详情见: https://www.cnblogs.com/10158wsj/p/6762848.html
http响应
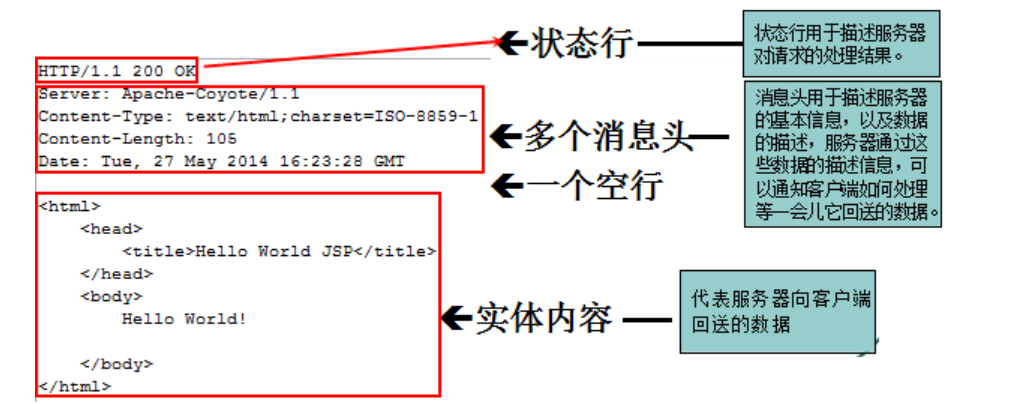
一个http响应代表服务器向客户端回送的数据,包括一个状态行,若干消息头,一级实体内容
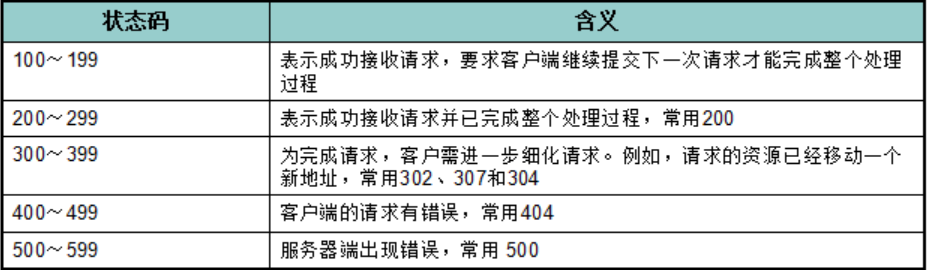
~http常见的状态码
| 200 | 请求成功,处理方式:获得响应内容 |
|---|---|
| 301 | 请求到的资源都会分配一个永久的URL,可以在将来通过该URL访问此资源,处理方式:重定向到分配的URL(永久重定向) |
| 302 | 请求到的资源在一个不同的URL处临时保存,处理方式:重定向到临时的URL(临时重定向) |
| 403 | 禁止,处理方式:丢弃 |
| 404 | 没有找到,处理方式:丢弃 |
各种系列:
~响应头(只需了解)
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
5、Request & Response
~大致流程图

~Request 请求
💖:**请求方式(主要是get和post) **
💖:**请求URL(统一资源定位符,每一个网页、每一张图片都有唯一的 url 确定) **
💖: 请求头(包含请求时的头部信息,如User-Agent、Host、Cookies等信息)
💖:请求体(请求时额外携带的数据,如表单提交时的表单数据)
request主要有两种方式,get请求和post请求,两者的不同主要体现在以下几点:
**(1) ** get请求的参数直接包含在url(全称是统一资源定位符)里面,不太安全,并且参数量是有一定限制的;post请求传递的参数放在Request body中,不直接暴露在url中,这就相对来说比较安全
get:
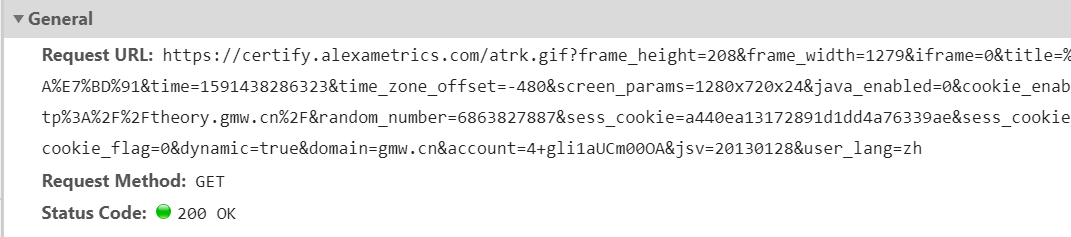
post:
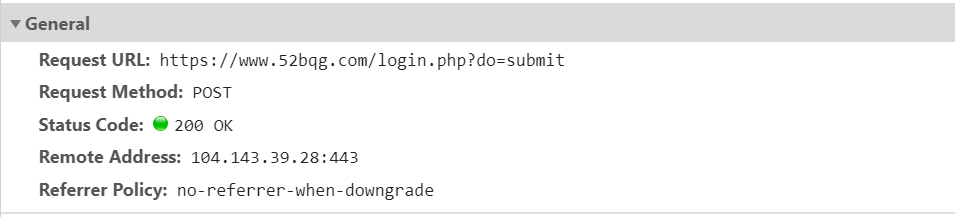
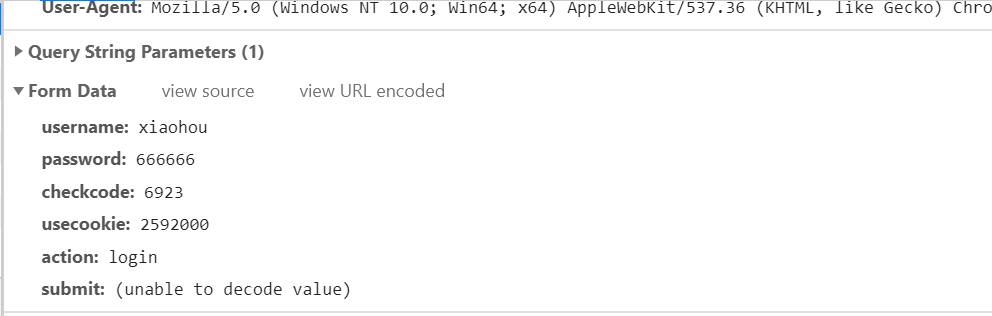
(2) ** post请求通常是以form表单的形式向服务器发送请求
~Response 响应

响应状态和响应头请参考上面的介绍,响应体是请求资源的内容,比如网页html代码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









