







Focus Longer to See Better: Recursively Refined Attention for Fine-Grained Image Classification
code:https://github.com/TAMU-VITA/Focus-Longer-to-See-Better
paper:https://arxiv.org/abs/2005.10979
Abstract
类间的边缘视觉差异(the marginal visual difference)使得细粒度分类很难。
- focus on these marginal differences to extract more representative features.(基于此观察,作者将关注点放在了边缘视觉差异来提取更具有代表性的特征)。
- 另外,使用可视化方法来验证模型怎样focus changes from coarse to fine details。
- 一个简单的注意力模型可以聚合(加权)图像中最主要的鉴别部分。
- 由于模型比较简单,使得它成为一个即插即用模块(an easy plug-n-play module)。
优点:
- 可解释
- 相比baseline模型,acc增加高达2%。
3.Our Proposal
image I I I ;label c c c
a two-stream feature extractor is used to extract global and object-level feature representations to boost the classification accuracy.
3.1.Two-Stream Architecture 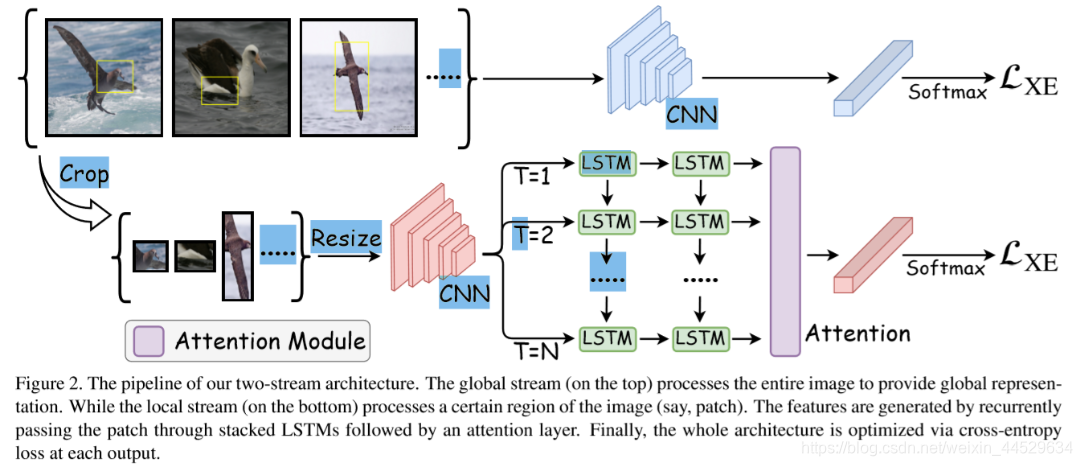
对于每个image I I I 会得到一组patches P P P,从中随机选择一个patch P i P_i Pi (patches P是通过该 paper 得到的), P i P_i Pi是由一对坐标表示 [ ( x i t l , y i t l ) , ( x i b r , y i b r ) ] [(x_i^{tl},y_i^{tl}),(x_i^{br},y_i^{br})] [(xitl,yitl),(xibr,yibr)],tl,br分别表示左上角、右下角坐标。
网络的输入就是由 image I I I 和patch P i P_i Pi 得到的。
- The top stream 就是常见的分类网络,原图放到CNN中提取feature,然后送到classification layer+softmax进行分类。
- The second stream将patch送到CNN中提取feature,然后送到LSTMs中去得到更细化的特征表示,该特征表示再通过加权融合的方式形成一个最具有判别性的特征表示。
Global Stream
对应the top steam,CNN模块主要是在ImageNet上pretrian好的模型,图片经过CNN提取到的特征表示为 W g ∗ I W_g *I Wg∗I, W g W_g Wg表示整个神经网络的权重, ∗ * ∗表示所有的conv、pooling、非线性激活等函数,之后该feature送到softmax中得到每个类别的概率。公式如下:
G I = F ( W g ∗ I ) G_I = F(W_g * I) GI=F(Wg∗I)
G I G_I GI 表示图片的global representation, F ( . ) F(.) F(.) 表示global avg pooling之后接softmax。
Global Stream的作用:
- 提供global information,因为patch送到网络中学到的是object-level的信息,仅关注object本身。
- 提供了一个baseline,加了local steam后可以用来验证contribution。
Local Stream
weakly supervised patch P = [ P 1 , P 2 , P 3 , . . . , P n ] P = [P_1,P_2,P_3,...,P_n] P=[P1,P2,P3,...,Pn]
图二中显示的The set of cropped image regions可以表示为 I ( P ) = I ( P 1 ) , I ( P 2 ) , I ( P 3 ) , . . . , I ( P n ) I(P)=I(P_1),I(P_2),I(P_3),...,I(P_n) I(P)=I(P1),I(P2),I(P3),...,I(Pn)
第i个patch送到pretrain的CNN网络中
F i = ( W g ∗ I ( P i ) ) F_i = (W_g * I(P_i)) Fi=(Wg∗I(Pi)) size=w x h x c
W g W_g Wg 表示CNN中所有的参数,* 表示conv、pooling、非线性激活等函数。
注意,两个CNN模块不共享参数。
stacked-LSTMs中所有time steps输出表示为 [ ϕ ( F i 1 ) , ϕ ( F i 2 ) , . . . , ϕ ( F i T ) ] , t = 1 , 2 , 3 , . . . , T [ \phi(F_i^1), \phi(F_i^2),..., \phi(F_i^T)],t=1,2,3,...,T [ϕ(Fi1),ϕ(Fi2),...,ϕ(FiT)],t=1,2,3,...,T , ϕ ( F i t ) ∈ R D \phi(F_i^t) \in R^D ϕ(Fit)∈RD
实验4.2验证假设,即特征如何随着时间步长而变化,以关注part的更细微的细节。
将通过LSTMs得到的finer details送到Attention机制中,得到的输出
A
i
A_i
Ai表示为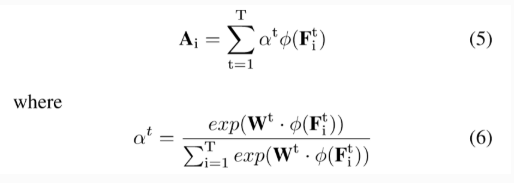
其中,
W
t
∈
R
D
W^t \in R^D
Wt∈RD表示其中的参数
之后将D维的输出送到FC+softmax进行分类,即 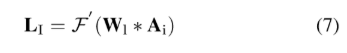
L
I
L_I
LI 表示概率分布,
W
l
W_l
Wl 表示attention之后fc层的参数,
F
′
(
.
)
F'(.)
F′(.)表示softmax layer
这样的设计使得网络逐渐关注到图像中patch/part中最具辨识力的区域,增强了对图像预测的置信度。
3.2.Classification Loss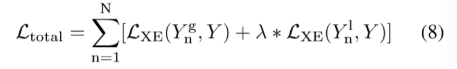
N表示training samples
Y n g Y_n^g Yng 表示global image的预测值
Y
n
l
Y_n^l
Ynl 表示patch的预测值,
λ
\lambda
λ 控制两个loss的权重
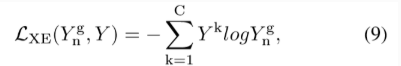
loss使用交叉熵,C表示类别数。
4.Experiment Results
4.1.Implementation Details
数据集:
- CUB200-2011 (11788张图,200类,5994train,5794test)
- Stanford Dogs(从ImageNet上采集的狗,20580张图,120类,12000train,8580test)
VGG
Global stream:
input size:(448*448)
为了减少计算量,将VGG的fc层移除,加上GAP+fc,fc参数随机初始化
Local stream:
patch先resize成224x224,——>放到被pre-train好的VGG网络(移去conv5_4)中,得到的ouput feature为512x14x14,——>经过GAP得到512channel的feature
——>LSTM(time-step=10)——>2个fc
在测试时,这些softmax层被删除,预测是基于这两个steam的相同加权组合
4.2.Visualization and Analysis
Grad-CAM
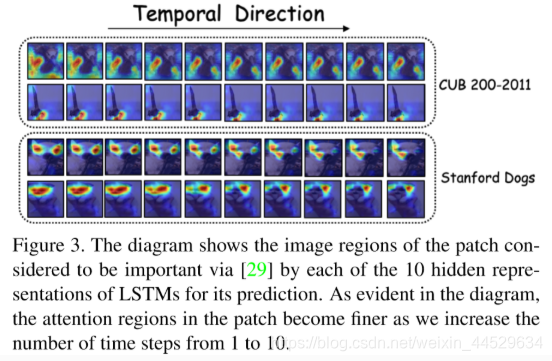
the attention spans changes from generic regions like the whole face to more subtle variations present in ears,feather, beak.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









