










目录
1. 引言
- 简要介绍YOLO系列的发展历程及其在目标检测领域的地位。例如,可以提到YOLOv8作为最新版本,继承了前代模型的高效性和准确性,并在速度、精度和易用性上实现了显著提升。
- 强调YOLOv8在多目标检测、实时性以及复杂场景下的应用优势。
2. YOLOv8架构解析
2.1 核心思想
- 将目标检测任务视为回归问题,通过单一神经网络直接预测边界框坐标和类别概率,从而简化了传统两阶段检测算法的复杂性。
- 强调其“单次检测”(Single Shot)的核心理念,即通过端到端的网络结构实现高效的目标检测。
2.2 网络结构
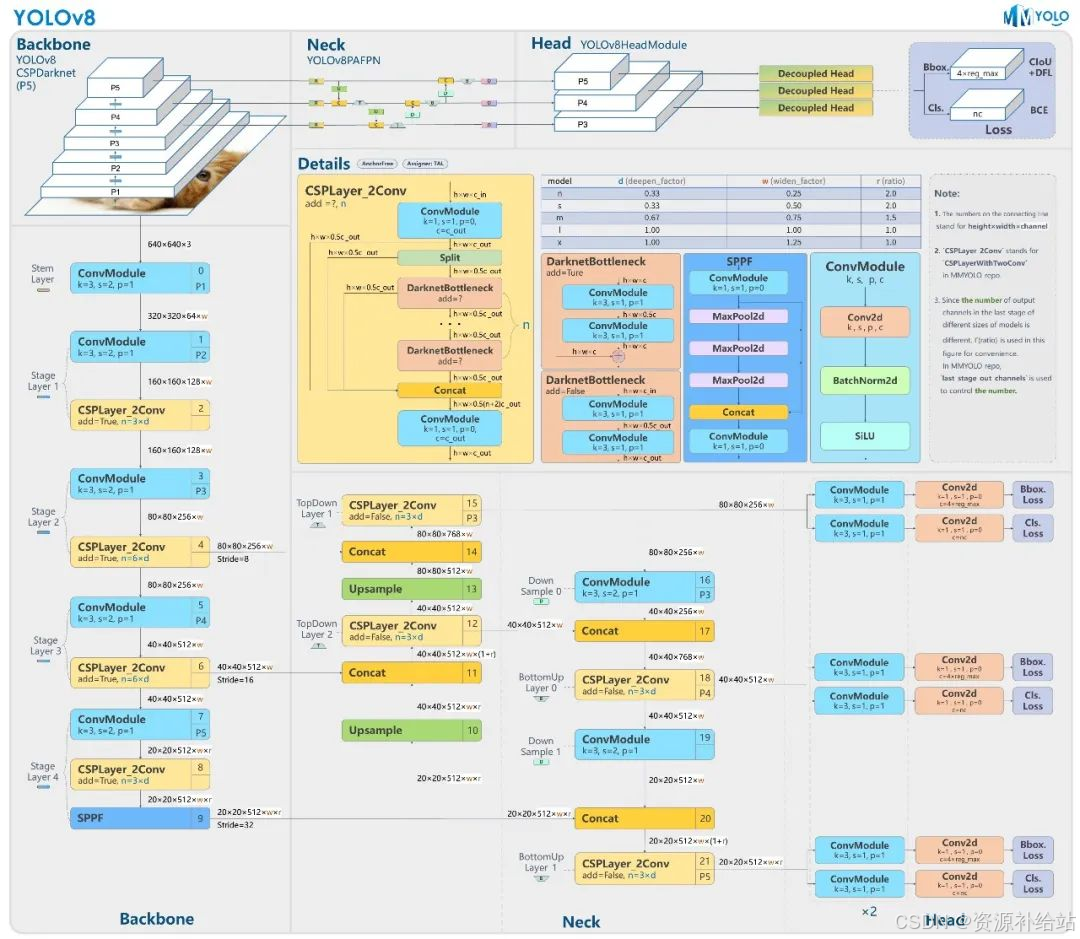
- Backbone(主干网络) :采用CSPDarknet53作为基础架构,包含C3模块、Cf和SPPF模块,用于特征提取。
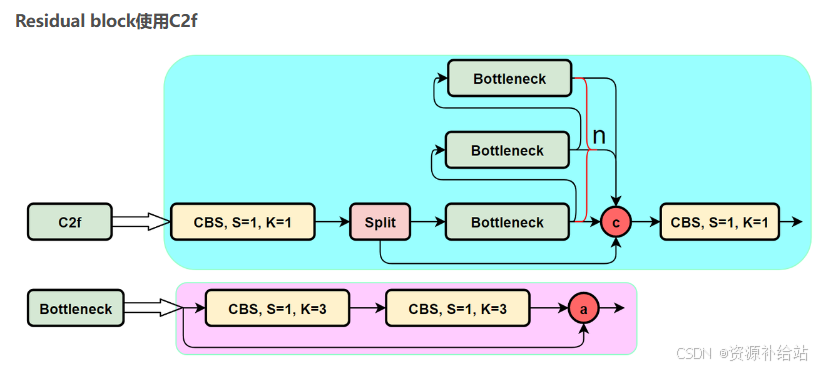
- Neck(颈部模块) :引入PAFPN结构,支持多尺度信息融合,提升小目标检测能力。
- Head(头部模块) :采用解耦头设计,分别负责分类和回归任务,同时引入Squeeze-and-Excitation(SE)模块以增强特征表达能力。
2.3 创新点
- 多尺度特征融合:通过PANet特征融合机制,提高模型对不同尺寸目标的适应性。
- 自适应锚框生成:改进锚框生成策略,提升小目标检测精度。
- 注意力机制:引入多头自注意力机制(MHSA),整合多角度特征信息,进一步优化检测性能。
3. 训练与优化策略
3.1 训练流程
- 数据准备:包括数据集收集、标注及划分。可以使用LabelImg工具将VOC格式的标注文件转换为YOLO格式。
- 模型加载与预训练:利用Ultralytics库加载预训练模型,并根据具体任务调整模型参数。
- 训练参数设置:包括学习率调度、优化器选择(如Adam或SGD)、损失函数设计等。
3.2 优化技术
- 数据增强:通过随机裁剪、翻转、颜色抖动等方法增加训练样本多样性,提高模型泛化能力。
- 损失函数改进:采用复合损失函数,结合定位损失(如CIoU)、分类损失(如Focal Loss)和注意力机制优化目标检测效果。
- 模型压缩与加速:通过剪枝、量化等技术减少模型参数量和计算复杂度,提升推理速度。
4. 实际应用案例
4.1 自动驾驶
- 在自动驾驶场景中,YOLOv8能够实时检测车辆、行人及其他障碍物,为决策系统提供可靠的数据支持。
4.2 工业检测
- 在工业场景中,YOLOv8被用于缺陷检测、零件分类等任务。例如,在太阳能电池板缺陷检测中,改进后的YOLOv8模型显著提高了微小缺陷的识别率。
4.3 监控与安全
- 在监控领域,YOLOv8能够准确识别监控视频中的人员行为,用于智能监控系统。
5. 性能评估与对比
- 提供YOLOv8与其他主流目标检测算法(如Faster R-CNN、SSD、YOLOv5等)的性能对比结果。例如,在茶虫小目标检测任务中,YOLOv8的mAP达到了98.17%,显著优于其他算法。
- 分析YOLOv8在不同硬件平台上的运行效率,展示其在边缘设备上的适用性。
6. 未来发展方向
- 探讨YOLOv8潜在的改进方向,如进一步优化注意力机制、引入更先进的特征提取模块等。
- 分析YOLOv8在新兴领域的应用前景,如水下目标检测、无人机遥感等。

7. 复现训练YOLOv8模型
7.1环境准备
在开始之前,确保你的开发环境已经正确配置。推荐使用Anaconda来管理Python环境,因为它可以方便地创建和管理虚拟环境,并且与深度学习库(如PyTorch)兼容性良好。以下是详细的步骤:
- 安装Anaconda:如果你还没有安装Anaconda,可以从Anaconda官网下载并安装。
- 创建虚拟环境:打开终端或命令提示符,创建一个新的虚拟环境,并激活它。
conda create -n yolov8_env python=3.7
conda activate yolov8_env
7.2 安装必要的库
在激活的虚拟环境中,安装所需的库。
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
pip install opencv-python
pip install matplotlib
pip install PyYAML
pip install seaborn
安装Ultralytics库:YOLOv8是由Ultralytics开发的,因此需要安装该库。
pip install ultralytics
检查CUDA和NVIDIA驱动:确保你的系统上安装了合适的NVIDIA显卡驱动以及CUDA工具包。可以通过以下命令检查CUDA是否可用:
import torch
print(torch.cuda.is_available())
7.3 数据集准备
YOLOv8支持多种数据集格式,但最常用的是YOLO的标准格式。以下是详细的数据集准备步骤:
- 创建主目录:创建一个主目录,例如
dataset/。 - 创建子目录:在主目录下创建
images/和labels/两个子目录。 - 组织图像文件:将图像文件放入
images/目录。 - 创建标签文件:为每张图片创建一个对应的标签文件放在
labels/目录。标签文件应与图像文件同名,使用.txt扩展名。内容格式为:
<class_id> <x_center> <y_center> <width> <height>
其中,坐标为相对坐标,范围在0到1之间。
7.4 配置文件
在训练之前,需要为YOLOv8配置一个数据集的配置文件,例如data.yaml。示例内容如下:
train: dataset/images/train
val: dataset/images/val
nc: 2 # 类别数量
names: ['class1', 'class2'] # 类别名称
7.5 训练模型
接下来,我们将训练YOLOv8模型。以下是详细的训练步骤:
- 检查GPU可用性:确保你的系统上安装了NVIDIA显卡驱动和CUDA工具包。
- 启动训练:使用以下代码启动训练。
import os
import torch
# 检查是否有可用的GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# YOLOv8的训练命令
os.system('python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov8.pt --cache')
- 参数解释:
--img:输入图像的尺寸。--batch:每个批次的图像数量。--epochs:训练的轮数。--data:数据集配置文件的路径。--weights:预训练权重文件的路径(你可以使用预训练的YOLOv8模型)。--cache:开启缓存以加速训练。
7.6 评估模型
训练完成后,我们可以评估模型的性能。可以使用以下命令进行评估:
os.system('python val.py --weights runs/train/exp/weights/best.pt --data data.yaml --img 640')
7.7 进行预测
在训练完成并进行模型评估后,你可以利用训练好的模型进行预测。以下是实现预测的示例代码:
import cv2
from models.common import DetectMultiBackend
# 加载模型
model = DetectMultiBackend('runs/train/exp/weights/best.pt', device=device)
# 读取图像
img = cv2.imread('path/to/your/image.jpg')
results = model(img)
# 解析结果
boxes = results.xyxy[0] # 第一张图像的结果
for box in boxes:
x1, y1, x2, y2, conf, cls = box
print(f'Detected {model.names[int(cls)]} with confidence {conf:.2f}')
经过上述步骤,你成功复现并训练了YOLOv8模型,使用自己的数据集完成目标检测。
8. 总结
- 总结YOLOv8在目标检测领域的创新性和实用性,强调其在速度、精度和易用性上的平衡,YOLOv8表现出色,适合各种实际应用场景。
- 强调YOLOv8作为行业标准模型的重要性,并展望其未来的发展潜力。


















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









