







一、概述
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
XXL-JOB由Quartz这款老牌的任务调度中间件演化而来,相对来说,具备以下优势:
- 操作更简单,学习成本更低
- 使用异步化调度,性能更好
- 有配套的运维后台系统,提供了配置、监控、日志、统计报表等功能
- 拥有更简单的集群部署方案,服务的注册与发现等功能
跟Quartz的对比:
1、语言支持: Quartz主要是基于Java的任务调度框架,支持Java语言,xxl-job是一个分布式调度平台,提供了Java版本的调度中心,同时还提供了Python、PHP等语言的任务执行器,因此可以支持多语言。
2、分布式支持:Quartz本身并不提供分布式支持,需要通过一些拓展或者其他组件结合来实现。xxl-job专注于分布式任务调度,提供了分布式调度的解决方案,可以在多个节点进行任务调度与执行。
3、管理界面和监控系统: Quartz并没有相关的管理界面以及监控功能,需要自行开发或者结合其他组件实现。xxl-job提供了管理界面(包含任务管理、调度管理、监控、日志)。
4、 社区活跃度: Quartz是一款成熟的框架,拥有庞大的用户群体以及社区活跃度,xxl-job虽然相比较比较新颖,但也有着活跃的社区以及持续的更新支持。
1、调度中心
调度中心是一个单独的Web服务,主要是用来触发定时任务的执行。
它提供了一些页面操作,我们可以很方便地去管理这些定时任务的触发逻辑。
调度中心依赖数据库,所以数据都是存在数据库中的。
调度中心也支持集群模式,但是它们所依赖的数据库必须是同一个。
所以同一个集群中的调度中心实例之间是没有任何通信的,数据都是通过数据库共享的。
2、执行器
执行器是用来执行具体的任务逻辑的
执行器你可以理解为就是平时开发的服务,一个服务实例对应一个执行器实例
每个执行器有自己的名字,为了方便,你可以将执行器的名字设置成服务名
3、任务
任务什么意思就不用多说了,一个执行器中也是可以有多个任务的
总的来说,调用中心是用来控制定时任务的触发逻辑,而执行器是具体执行任务的,这是一种任务和触发逻辑分离的设计思想,这种方式的好处就是使任务更加灵活,可以随时被调用,还可以被不同的调度规则触发。
二、 DEMO
下载xxl-job源码,下载地址:https://github.com/xuxueli/xxl-job.git;
xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;
然后改一下数据库连接信息,执行一下在项目源码中的/doc/db下的sql文件;
1、 搭建调度中心
1.1、单机版:
将xxl-job-admin打成jar包启动或者本地IDEA直接启动后即可访问;
访问域名:http://localhost:8080/xxl-job-admin/toLogin 账号密码:admin/123456
1.2、集群版
XXL-JOB的集群部署非常简单,只需要注意两点:
- 集群节点都连接的是同一个数据库。
- 多台机器部署时,需要统一系统时间,如果是单个机器部署,则不用管这条。
现在是在同一台机器中,并且在上面打的包中,指定了数据库的url地址,所以只需要正常启动,就满足上述的条件了。找到刚刚打的包,xxl-job-admin,这是一个springboot的功能,所以通过java -jar直接启动就好了,这里先启动两台。
java -jar xxl-job-admin-2.3.1.jar --server.port=8080
java -jar xxl-job-admin-2.3.1.jar --server.port=8081通过配置域名以及Nginx路由即可访问集群中的调度中心管理系统了。
2、 启动执行器
2.1、引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>2.2、配置 XxlJobSpringExecutor
通过properties配置参数,然后初始化执行器对象,然后交给spring托管。
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-test
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30

在实际使用的时候可以直接把XxlJobConfig复制到自己的项目中去,也可以自行封装一个SpringBoot的starter包,在其他的项目中直接引入starter包进行使用,这里就不做赘述了。
最终,会使用XxlJobSpringExecutor生成一个Bean注册到Spring中,这个就是当前服务节点中的执行器对象,执行器对象会充当指挥官的角色,由它来调用不同的定时任务。
2.3、执行任务
我们需要注册一个Bean到Spring中,并使用@XxlJob告诉执行器哪个方法是需要进行调度的,代码如下:
package com.xxl.job.executor.service.jobhandler;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Component
public class TestJob {
private static Logger logger = LoggerFactory.getLogger(TestJob.class);
@XxlJob("TestJob")
public void testJob () {
System.out.println("TestJob执行日志打印!!");
}
}配置好后,我们就可以启动SpringBoot服务了,启动后就会往调度中心的数据库中,注册一个执行器实例。
注册的数据存入到xxl_job_registry表中:

- registry_key: 执行器节点中配置的
appname,即执行器名称。 - registry_value: 执行器节点暴露的ip和端口号。
registry_key是让调度中心用来获取执行器所有节点的请求地址的key,获取到请求地址后,就可以请求执行器的调度接口进行任务调度了。
2.4、执行器集群
执行器也是支持集群的,只需要在properties文件中,将addresses和appname配置为一样的就可以了。
3、 调度中心执行器以及任务配置
3.1、创建执行器
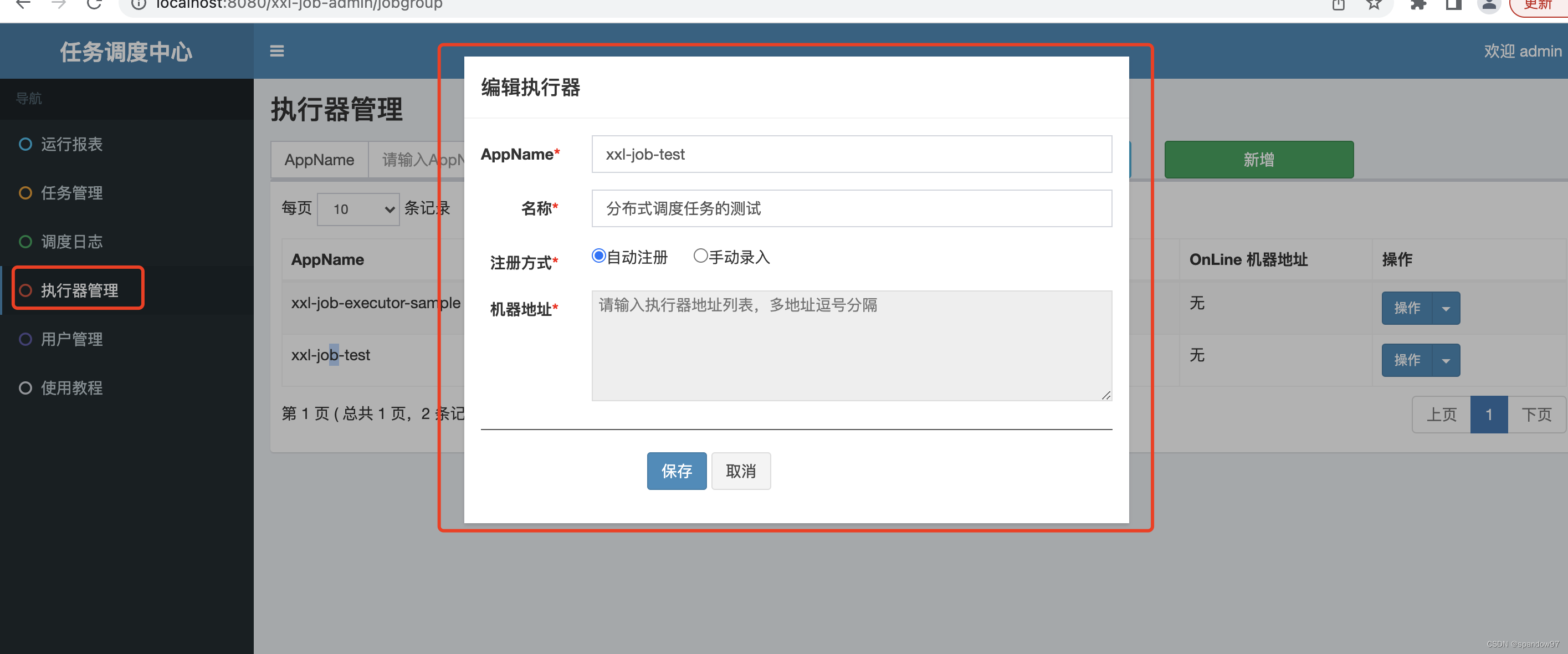
注册方式一般都默认选择自动注册,这种方式通过调度中心和执行器的通信机制传输注册信息;如果选择手动录入,在新增、修改、减少执行器实例的时候,都需要手动修改机器地址,需要人工一直介入,一般不会使用这种方式;
创建完成后,可以看到执行器注册实例的ip地址了
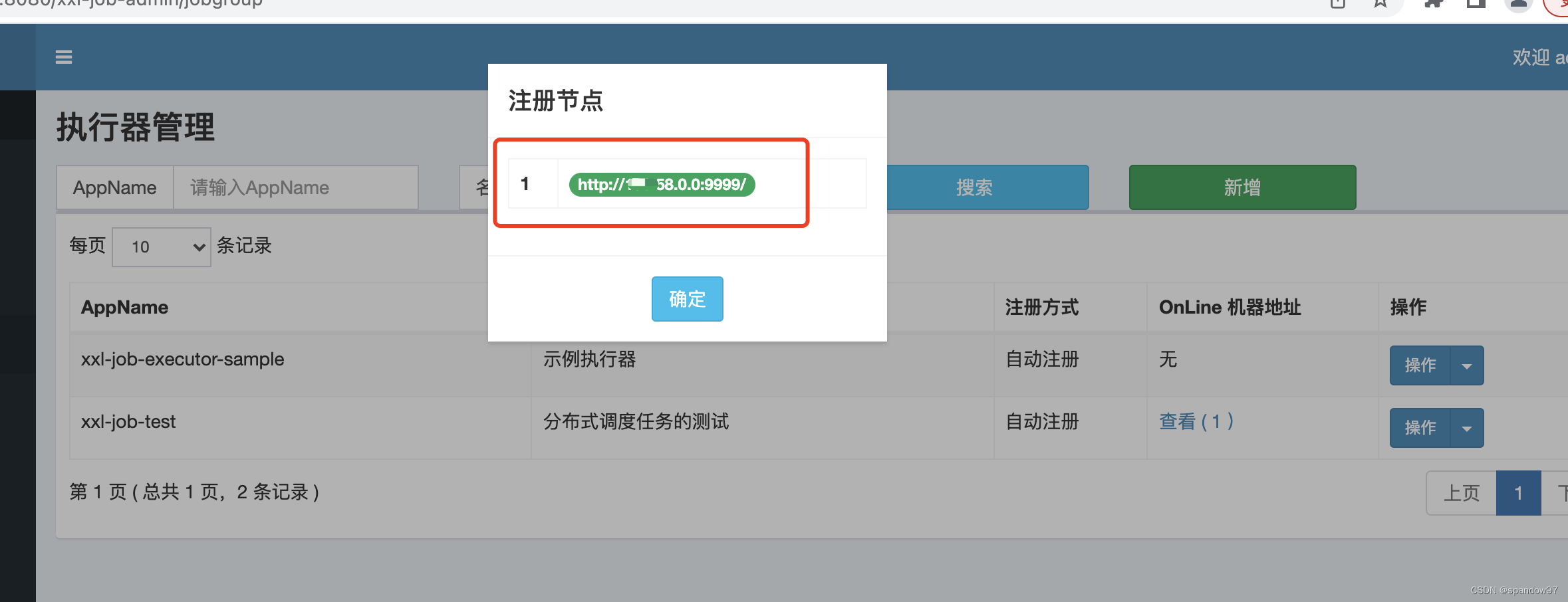
注意: 这里的地址列表是保存在执行器表xxl_job_group中的,如果在页面创建完成之后,Online机器地址没有值,可以等待30秒左右再进行查询,因为注册完成的执行器实例,每30秒会更新一次注册信息。
3.2、 创建定时任务
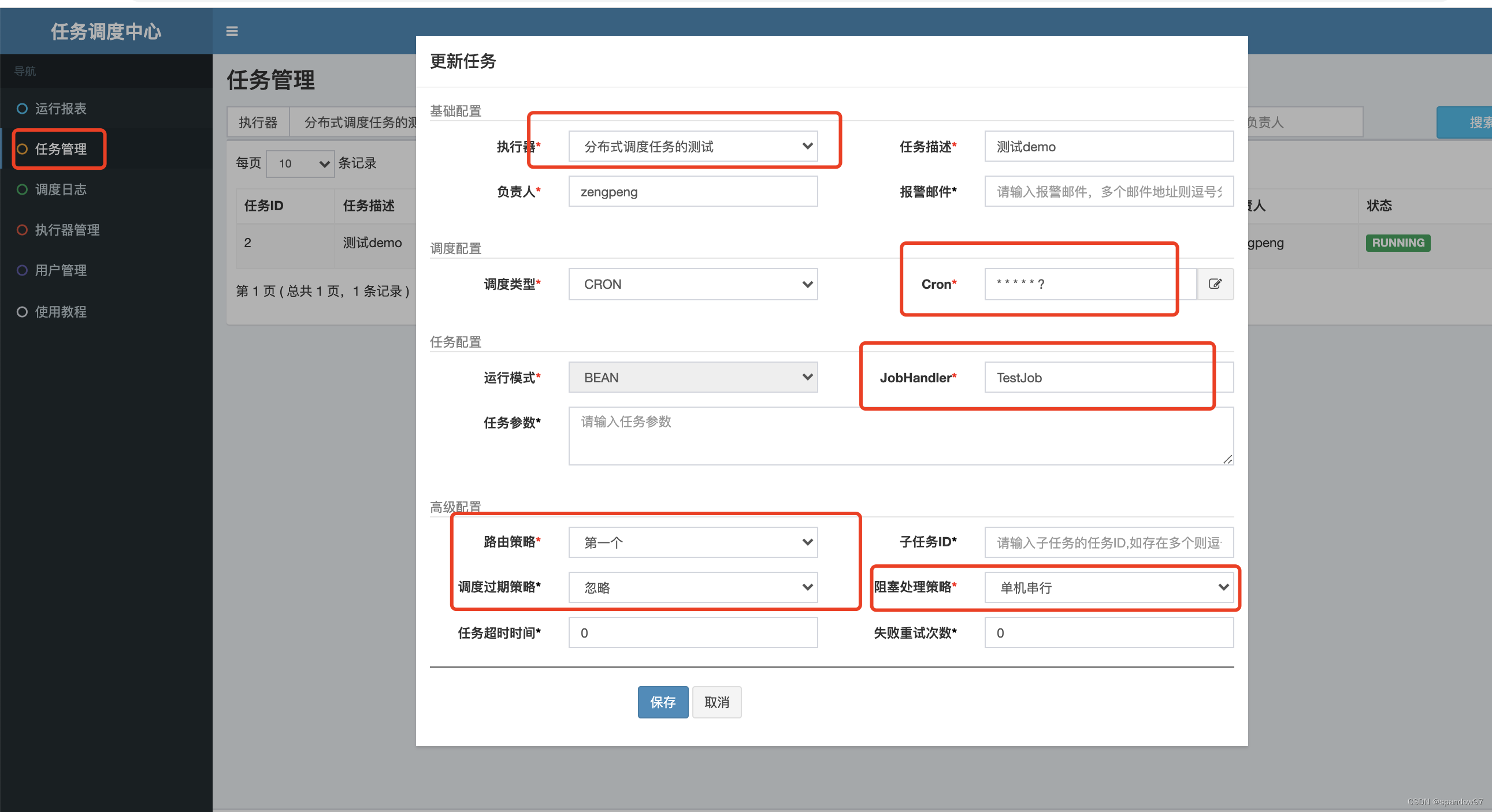
执行器选择我们刚才创建好的执行器即可;
Cron表达式定义调度规则;
JobHandler填写任务JOB名称,与代码中注解@XxlJob配置的名称一致;
创建完之后需要启动一下任务,默认是关闭状态,也就不会执行;
三、调度中心如何维护执行器的上下线感知
xxl-job在运行的过程中,调度中心要对执行器进行调度,得先获取执行器的信息,才能根据信息发起调度请求,同时,我们又不希望调度中心调用到不可用的执行器而导致程序异常。
于是XXL-JOB在调度中心维护了一个“注册中心”,通过xxl_job_registry表来实现的,调度中心根据表中的信息做负载均衡。所以需要将可用的、活跃的执行器信息注册上去,将不可用、宕机的执行器移除,这样就可以实现调度中心对执行器的上下线感知。
故主要包含三点:
- 执行器的注册流程;
- 执行器的注销流程;
- 调度中心的探活;
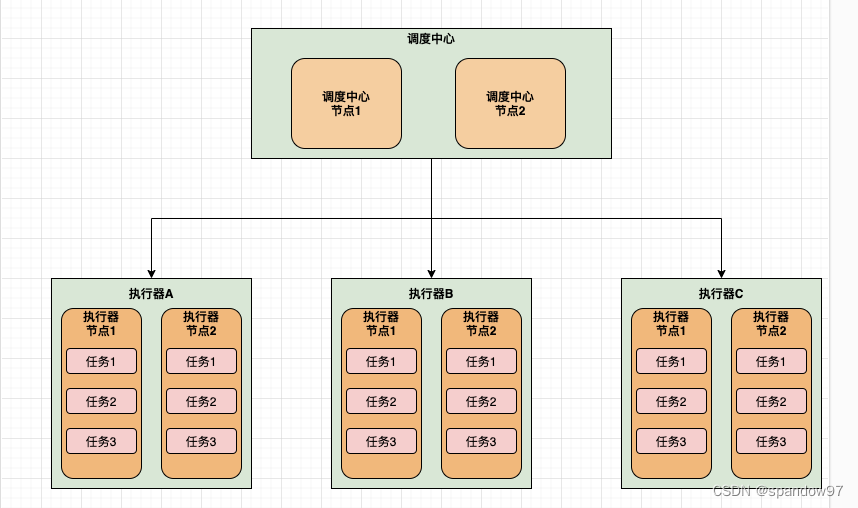
3.1、定时任务的调用流程
XXL_JOB的调度方式分为三层,每层向下进行调度,最上层为调度中心,最下层是定时任务方法。调度中心通过调度不同的执行器,执行器在调用归属于自己的定时任务。
3.2、 执行器注册流程
我现在使用的版本是2.3.1,XXL_JOB采用的是HTTP通信,调度中心是通过springboot实现的。
调度中心启动后,提供了一个执行器的注册接口,执行器启动的时候就会请求这个接口,将自己的执行器相关的IP、端口等信息传输到调度中心,调度中心将执行器上报的数据存储到数据库中,由此就完成了执行器的注册。
3.2.1、 调度中心的注册能力
在xxl-job-admin的controller包中,有一个接口提供了api:
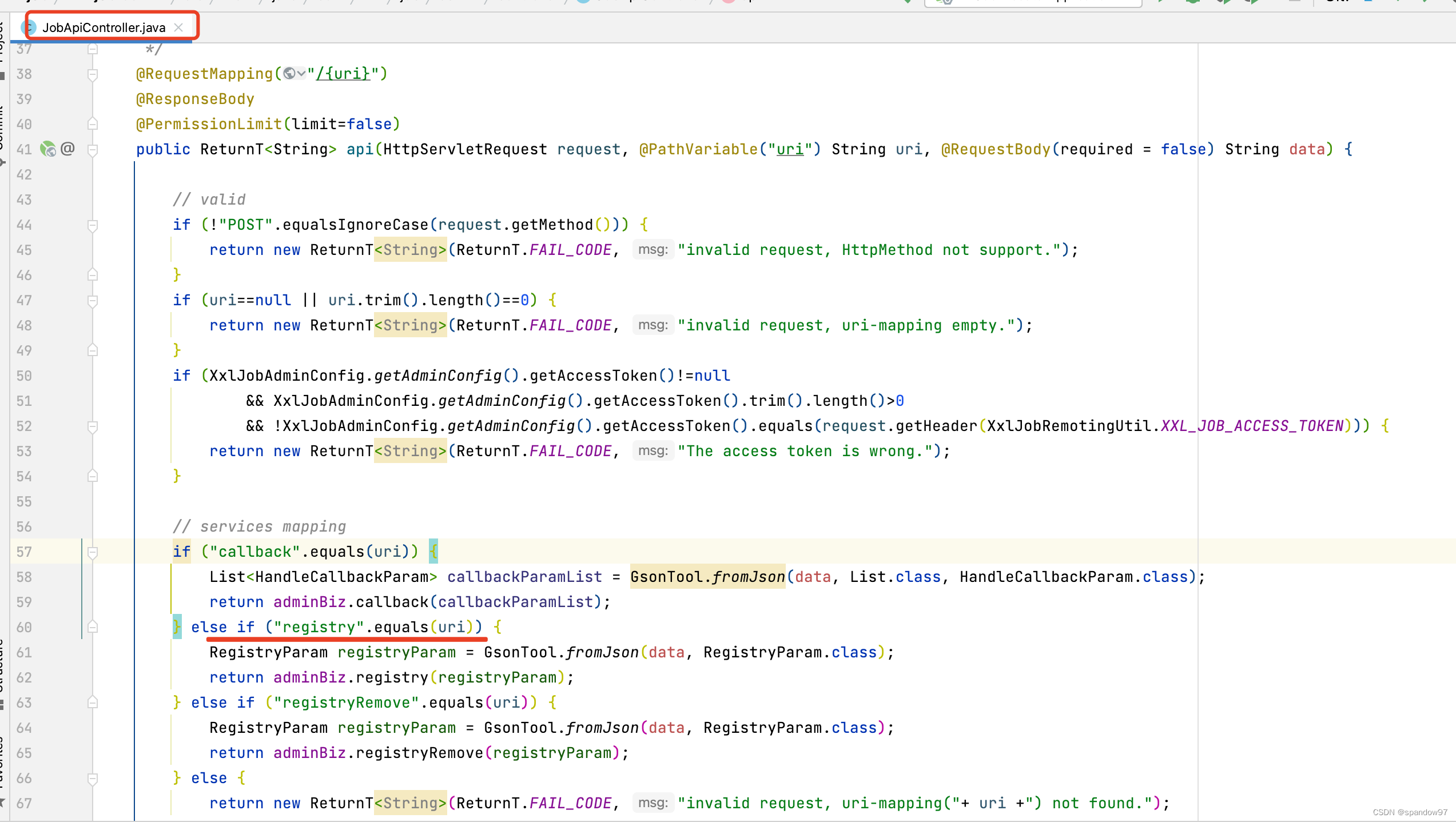
我们首先关注registry请求,看一下他的实现:
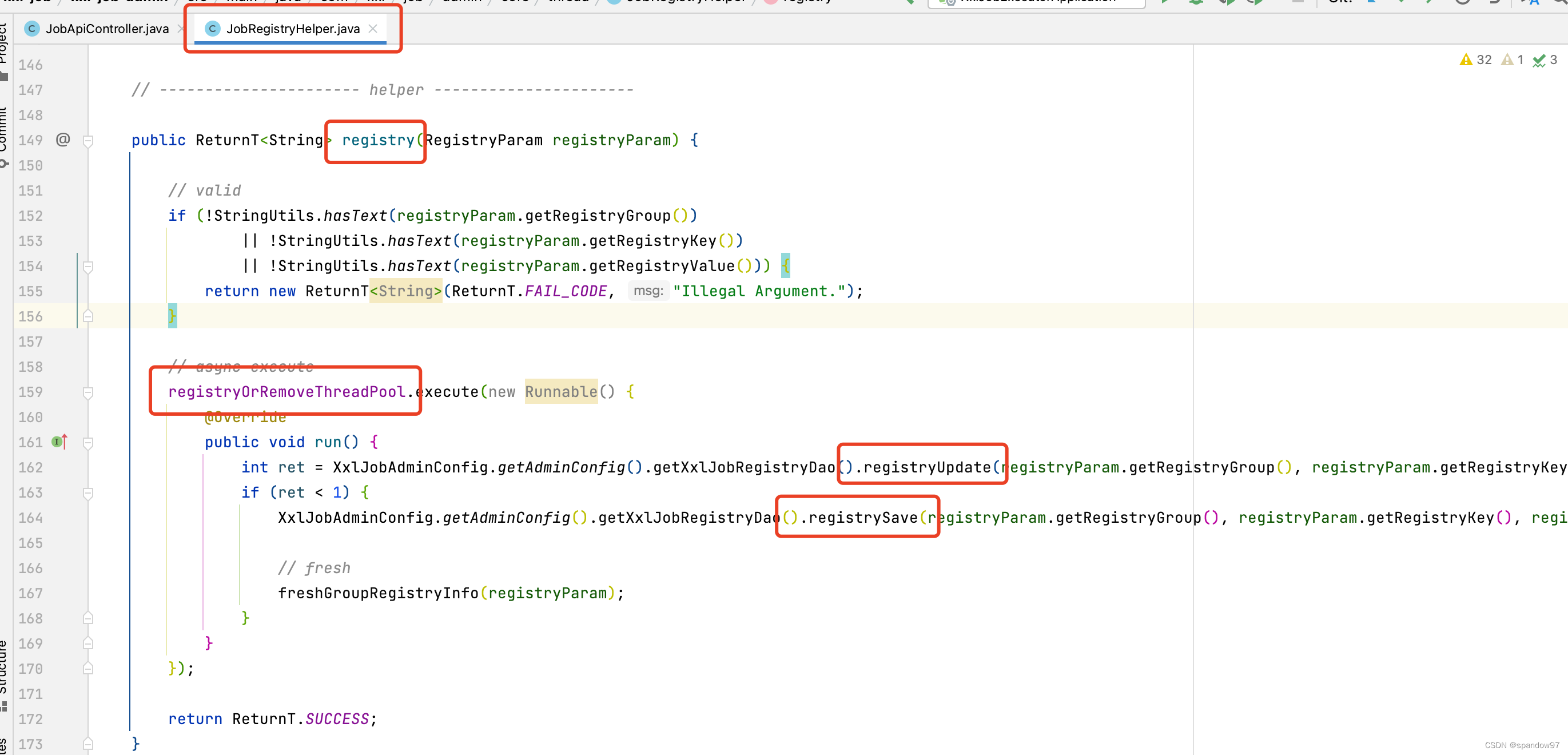
registry方法首先进行一个参数的校验,然后将请求扔到一个线程池中执行。
- registryUpdate: 更新执行器信息,操作主要是为了维持心跳;
- registrySave:创建执行器的注册信息;
这样执行器的信息就能注册到调度中心了;
registryOrRemoveThreadPool这个线程池是项目启动时提前创建好的,项目启动过程中通过init方法,创建线程池: 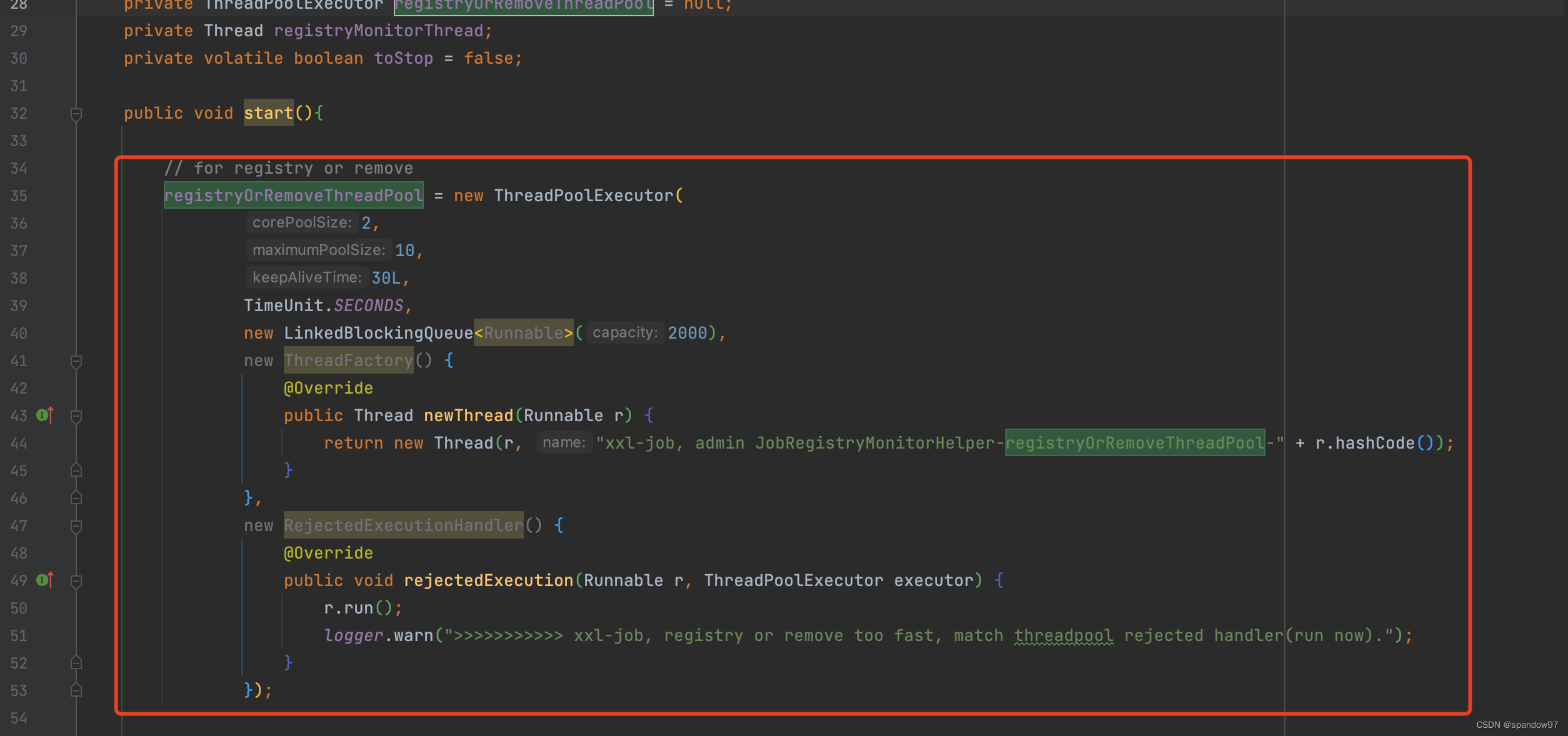
3.2.2、 执行器发起注册请求
我们使用的执行器,就是一个引入了xxl-job-core依赖包的web服务。xxl-job的通信主要基于core依赖中的AdminBiz类实现。 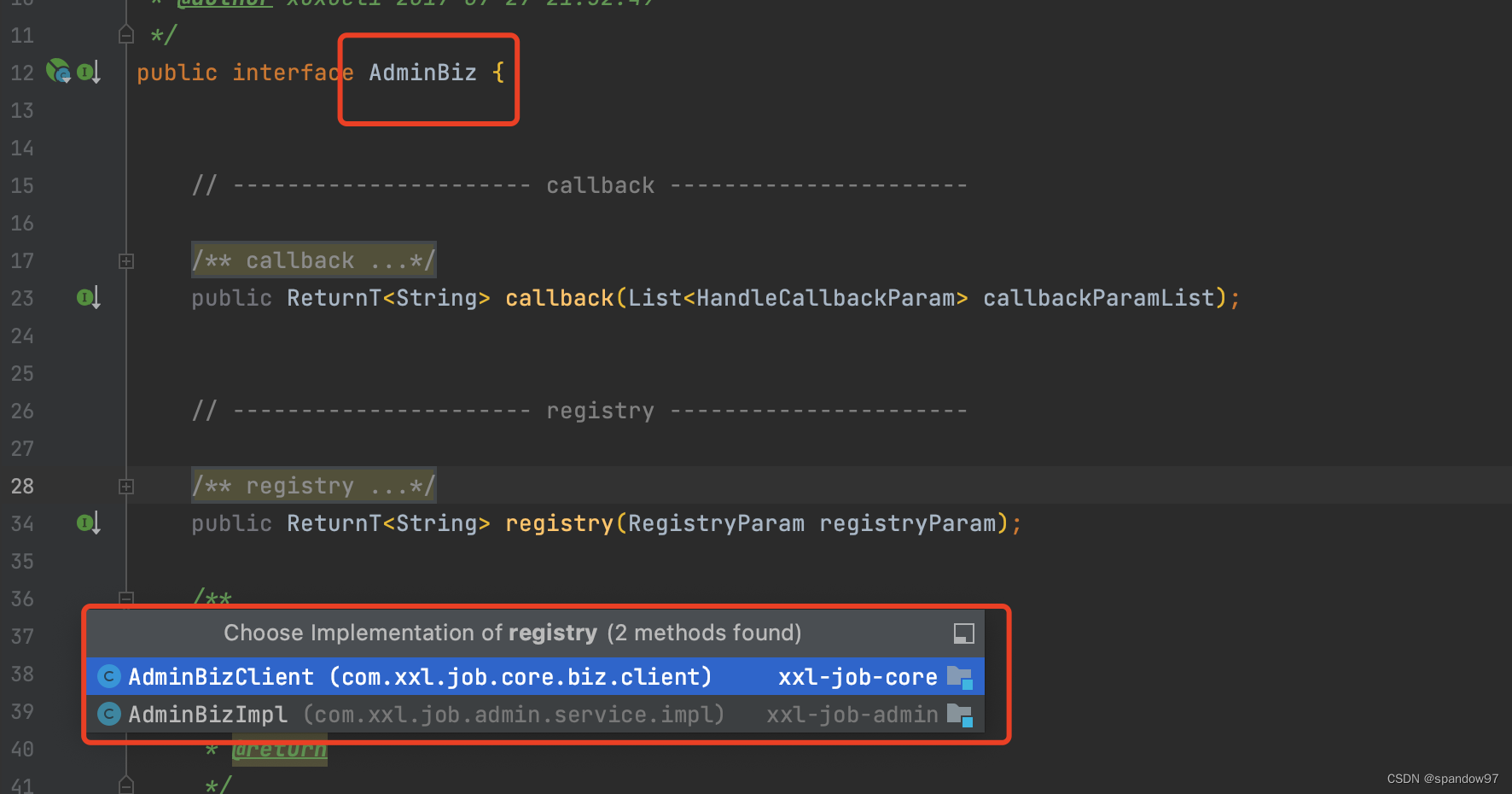
可以看到registry接口有两个实现,一个是AdminBizImpl实现类,在xxl-job-admin包中,这个类我们刚才已经见过了,就是注册中心提供注册API的时候使用过的。另外一个是AdminBizClient,这个类在xxl-job-core包中,执行器执行注册就是通过这个接口实现的。
接下来我们看一下registry接口的使用位置: 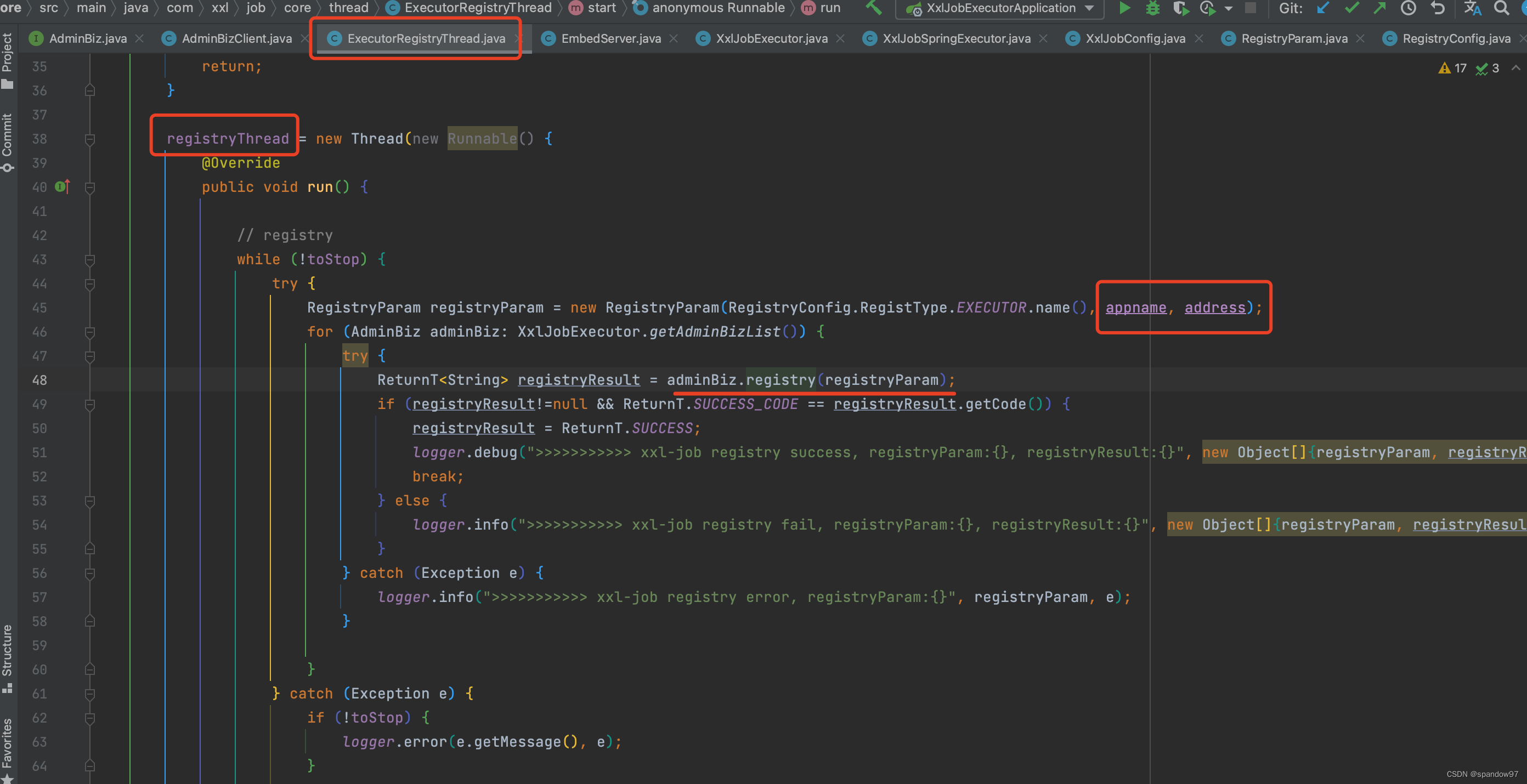
可以看到是在一个异步线程中执行,发起请求的注册参数registryParam包含执行器的appName以及adress信息。
在异步方法中,有一个while (!toStop)在不断地循环注册,是因为除了首次注册后,还用这个方法用来做心跳连接。心跳的频率是30s一次。
继续往外跳,我们可以看到是通过Netty作为http通信的底层实现进行数据传输。
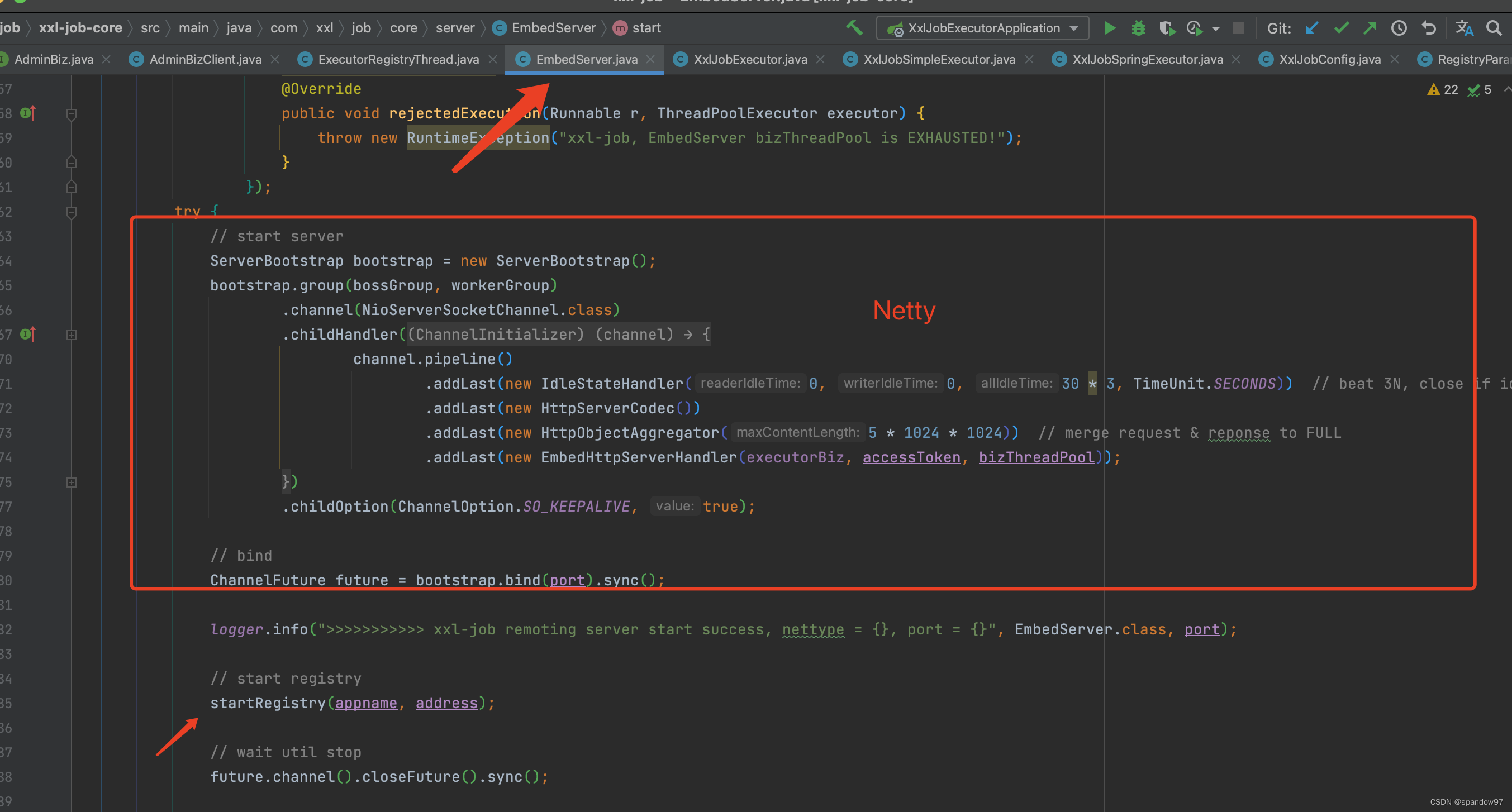
在往上翻,可以看到是XxlJobExcutor类中初始化的执行器通信。
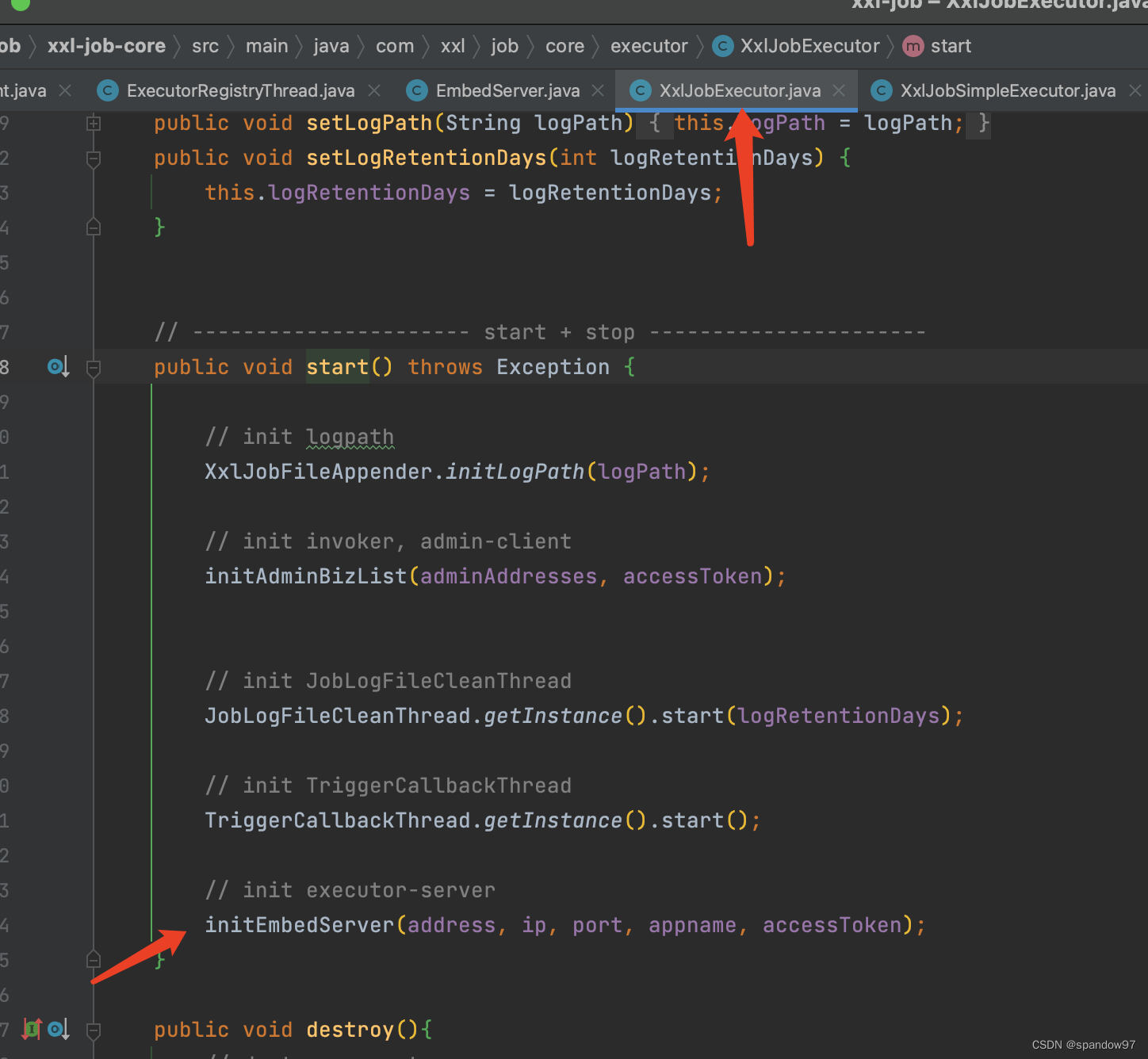
再往上翻,可以看到XxlJobSpringExecutor继承自XxlJobExcutor类,在这个类中开启执行器的一系列初始化功能。
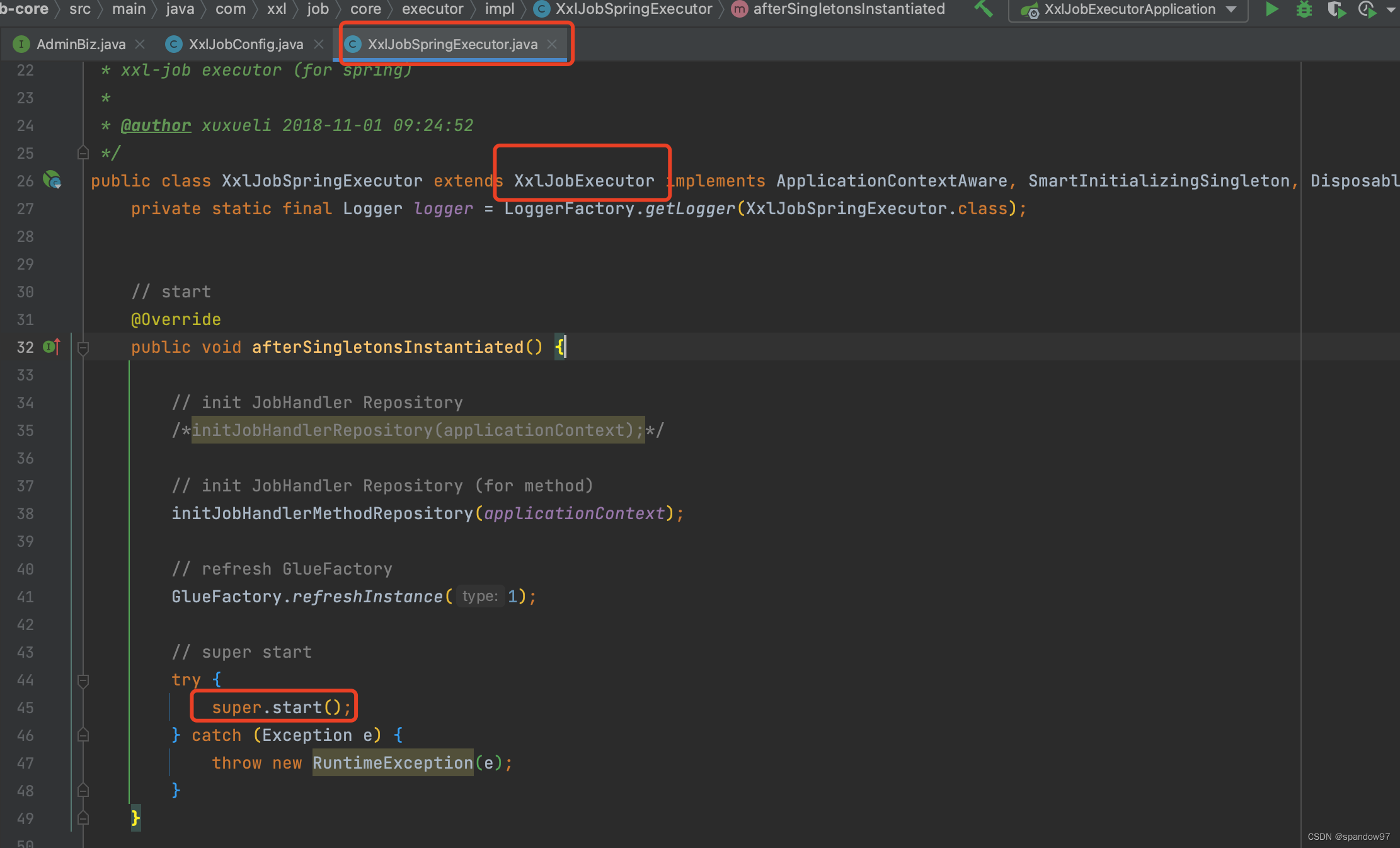
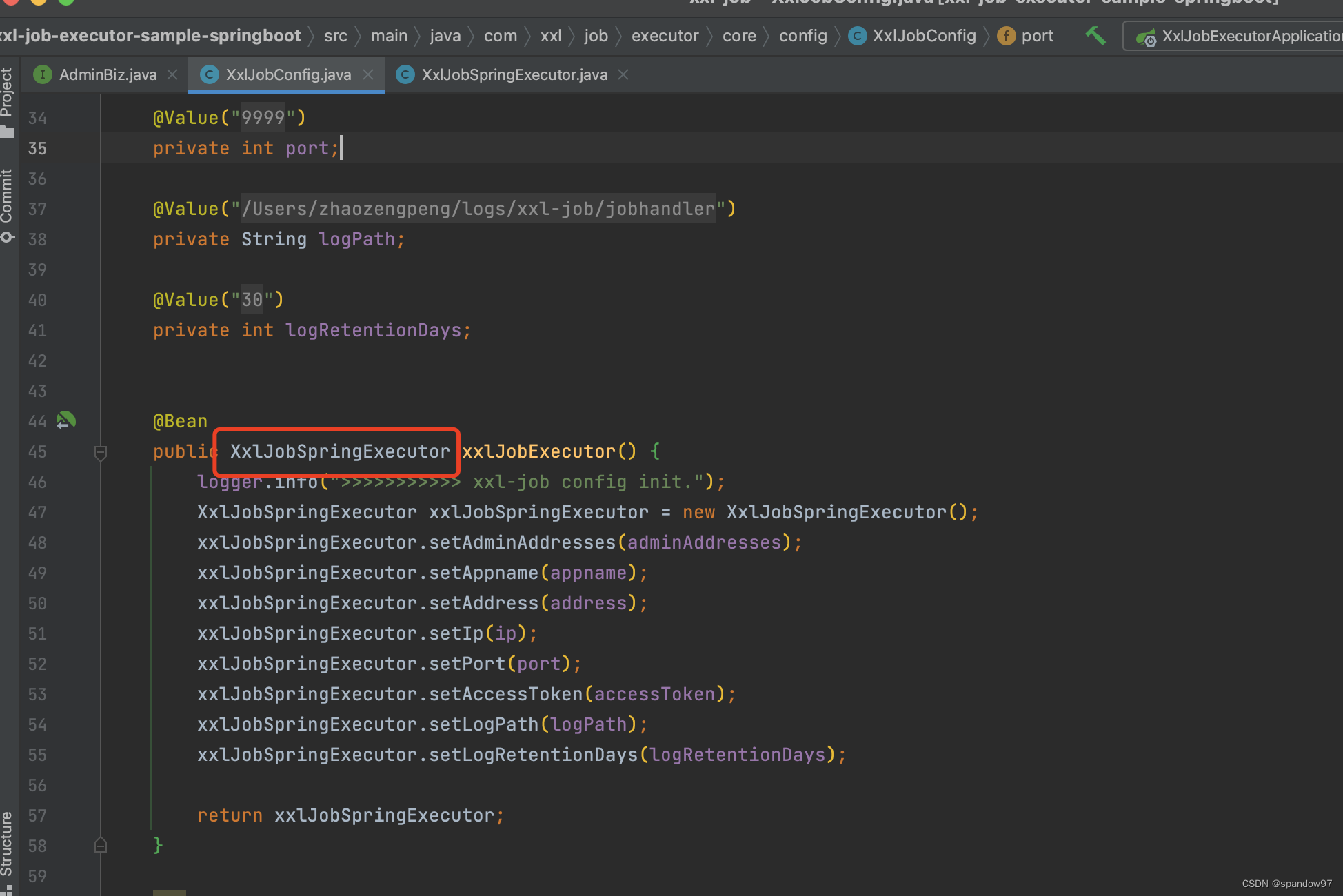
XxlJobSpringExecutor我们也不陌生的,在上边的Demo中,我们做执行的初始化参数配置的时候,就是给他注入参数的。
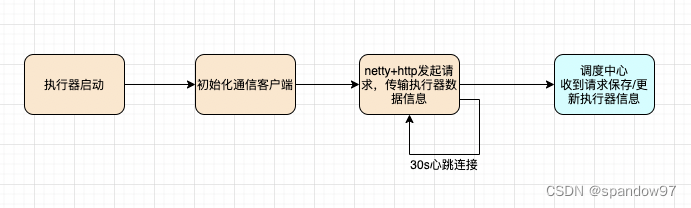
总结一下执行器的注册请求流程
3.3、执行器注销流程
执行器注销分为两种,一类是主动注销,另外一种是被动注销。
- 主动注销: 执行器主动向调度中心发送注销请求,调度中心接收到请求后,将该执行器的注册信息删除;
- 被动注销: 如果执行器所在机器发生宕机或者其他无法正常使用的情况下,由调度中心的探活线程发现某个执行器下线后,将该执行器的注册信息删除;
3.3.1、 主动注销
当spring容器正常关闭时,XxlJobSpringExecutor还实现了接口DisposableBean,这个接口提供了一个destory方法。当spring容器停止时,会停止Netty服务,中断注册线程(心跳线程),并主动发送注销请求。
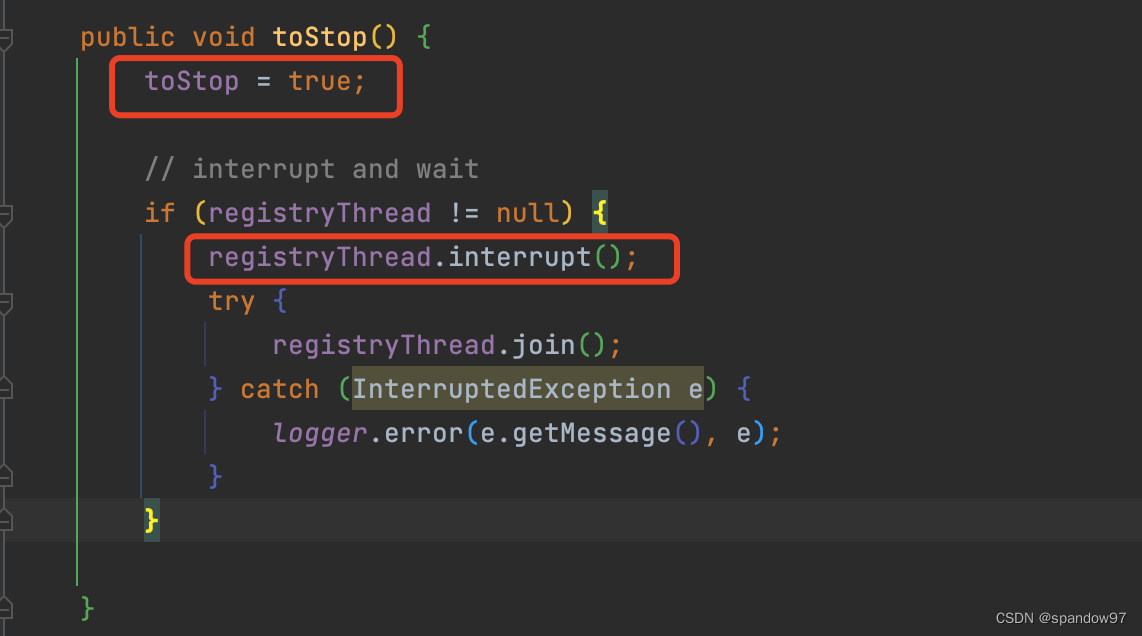
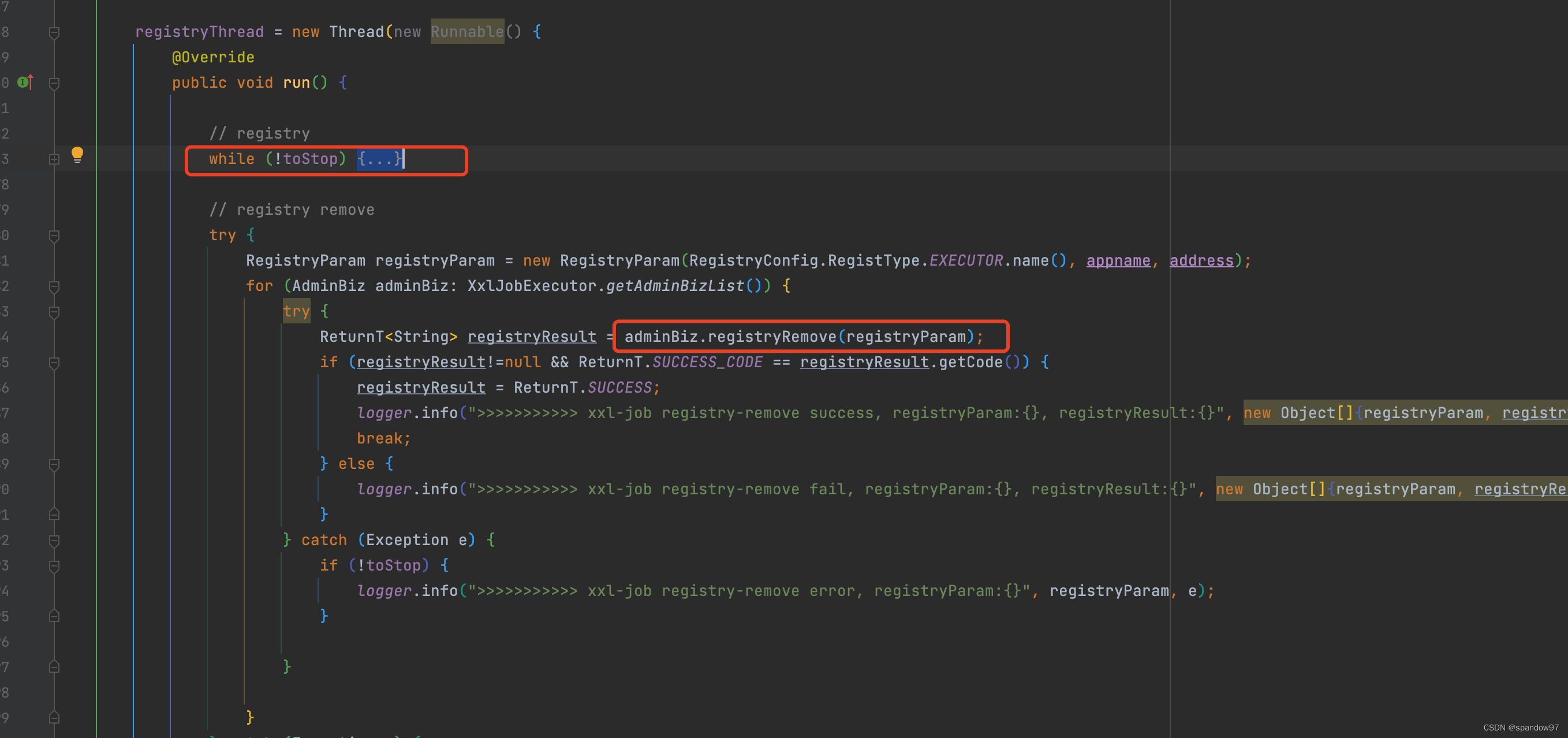
当stop改为true后,心跳流程终止,进而执行注销流程。调度中心收到注销请求后,通过线程池异步删除执行器数据(xxl_job_registry表)。
3.3.2、被动注销
调度中心在启动时,会初始化一个监控线程,这个线程每30s进行一次探活,查询xxl_job_registry表中的数据,将update_time为30s未更新的数据从表中删除。
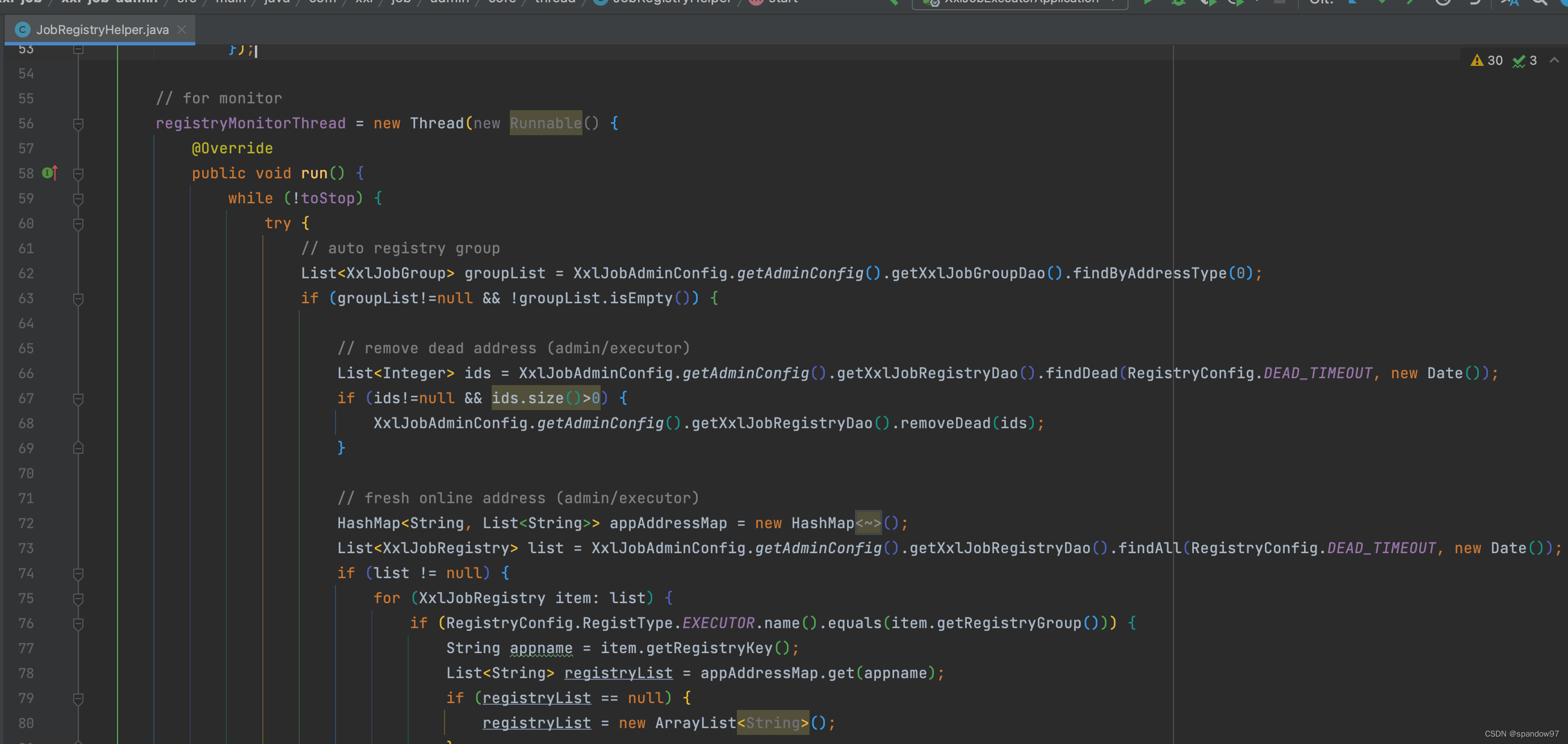
3.4、总结一下
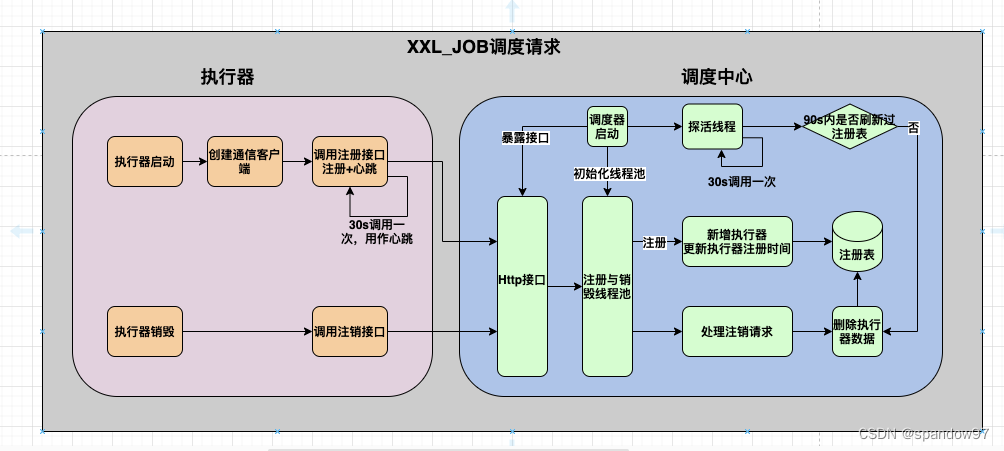
执行器注册到调度中心的流程以及代码实现,流程如下:
- 调度中心启动了一个Tomcat作为Web容器,暴露出注册与注销的接口,可以供执行器调用。
- 执行器在启动Netty服务暴露出调度接口后,将自己的name、ip、端口信息通过调度中心的注册接口传输到调度中心,同时每30秒会调用一次注册接口,用于更新注册信息。
- 在执行器停止的时候,也会请求调度中心的注销接口,进行注销。
- 调度中心在接收到注册或注销请求后,会操作xxl_job_registry表,新增或删除执行器的注册信息。
- 调度中心会启动一个探活线程,将90秒都没有更新注册信息的执行器删除掉。
四、定时任务执行
假如我们要自己实现一个定时任务的调度执行该怎么做?
- 调度中心循环读取定时任务表,查询已经达到触发时间的任务,如果已经到达触发时间,调用执行器执行对应的任务;
- 执行器接收调度中心调度,收到请求后执行任务,并将执行结果相应。
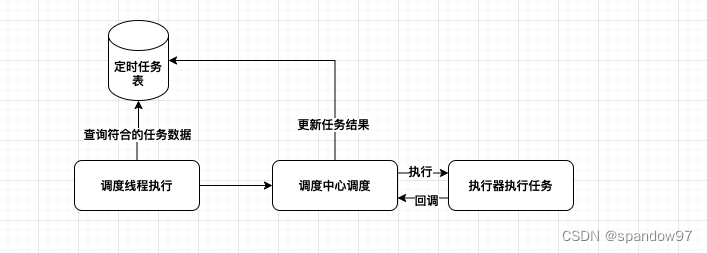
一个简单的定时任务流程就搭建好了,但是如果要在实际生产中应用的话,还存在一些问题:
1、 调度中心支持集群模式,怎么解决调度中心重复调度的问题?
2、 调度线程多久查询一次数据表合适?
3、 如何判断任务已经到了触发时间?已经超过出发时间还未触发的任务怎么处理?
4、 调度中心如何获取到具体的执行器实例,怎么避免调度到同一个执行器的多个实例?
5、 调度中心执行任务的时间过长,导致其他任务执行阻塞如何解决?
6、 执行器执行任务还未结束,下一个任务已经过来,如何处理?
7、 一个执行器可能有多个任务,如何找到当前需要执行的任务?
8、 多个任务之间如何避免影响?
9、 任务执行超时如何解决?
.............
带着这些疑问来看下XXL-JOB是如何解决这些问题的!
4.1、 调度任务扫描线程
调度中心在初始化的时候出创建任务扫描线程,通过#com.xxl.job.admin.core.scheduler.XxlJobScheduler类中的init方法,开启了JobScheduleHelper中的start方法
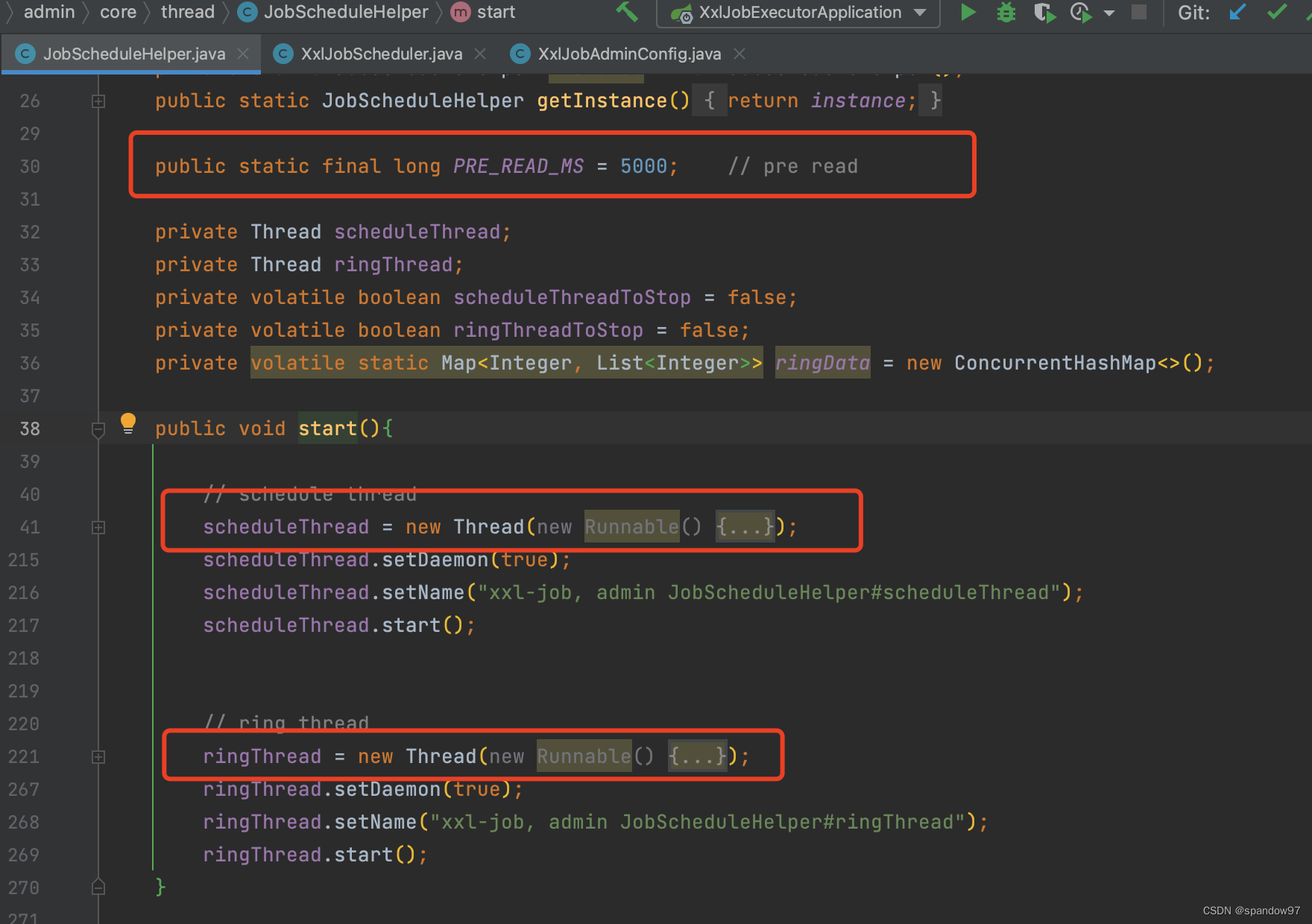
可以看到服务启动的时候,初始化了两个线程,一个是scheduleThread,用于任务扫描,判断任务是否应该触发。另外一个是ringThread,时间轮线程,除了一部分任务直接触发外,大部分人任务都有时间轮线程执行调度。
4.1.1、 调度集群解决重复调度
如果要解决集群重复调度问题,我们可以使用分布式锁来解决。xxl-job采用的是通过数据库for update来实现。
执行成功代表抢到了行锁,等到调度任务执行完成后再去关闭连接,从而释放锁。

4.1.2、 任务扫描线程读取任务
任务扫描线程启动后,就会循环读取任务

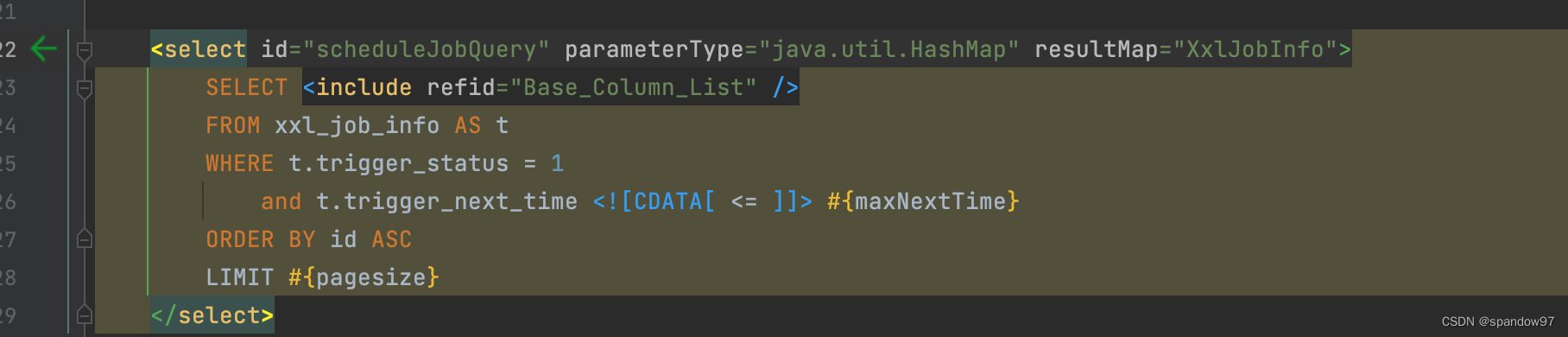
通过两边的两段代码,我们可以看到扫描线程会查询xxl_job_info表中处于启动状态的任务,下次执行时间在未来5s内需要触发的任务,并且最多可以获取到pagesize大小的列表。
这里的tigger_next_time是定时任务保存、更新时根据corn表达式计算的。
预读5s是因为如果采用系统时间精确匹配的话,线程执行过程中,可能会丢失一部分在线程执行过程生效的任务。所以采用预读的方式解决。
pagesize默认支持的定时任务数量是6000。作者给出一个数据,就是任务的执行时间耗时维持在50ms以下,所以qps是20。再根据pagesize的计算公式可以看到,(快线程池数量+慢线程池数量)* 20 = 6000。
4.1.3、扫描线程多久触发一次
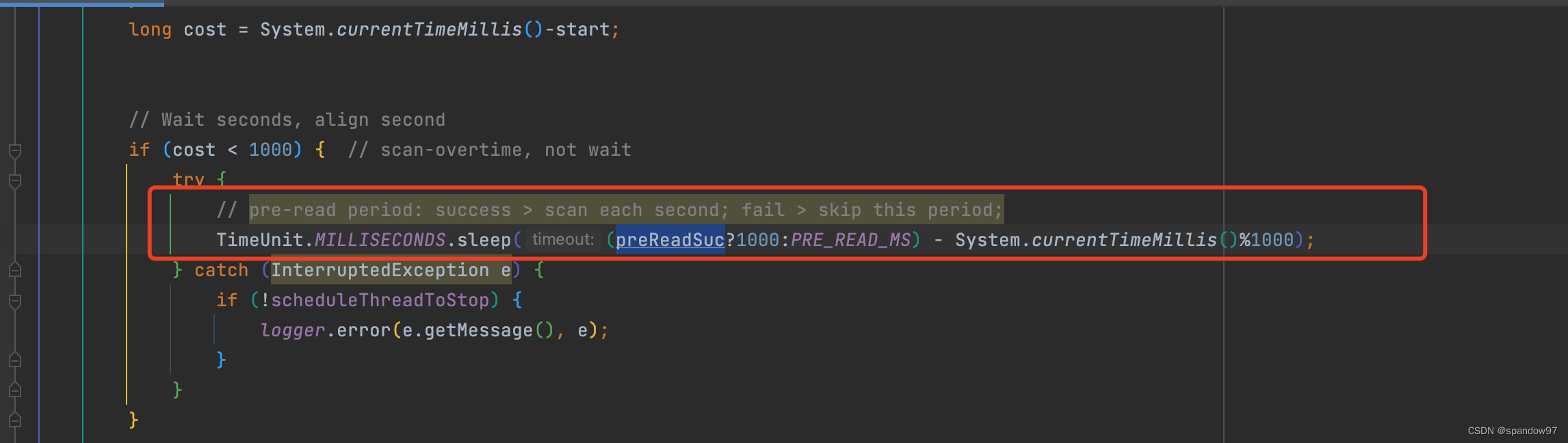
不间断的循环查询数据库,可能会出现大量无效的查询。所以我们需要加上一个间隔时间,但是这个时间怎么定呢?
我们可以看到xxl-job的间隔时间分别是1s或者5s(预读时间);
当本次查询到任务数据,并且执行时间少于1s时,就会等到1s后再进入下一次循环;如果没有查询到任务数据,则等待5s,这样可以减少无效的查询,并且5s内的任务数据可以通过预读的方式去解决,不会影响任务触发也可以减少数据库的压力。
4.1.4、计算任务触发时机
在扫描任务执行后,由于存在预读方式,可以将查询出来的任务数据分为三类:
1、 已经超时5s以上的任务;
2、 已经超时但是还未超过5s的任务;
3、 还未到触发时间;
接下来看一下xxl-job针对这三类任务分别做了哪些逻辑。
1、 已经超过5s以上的任务
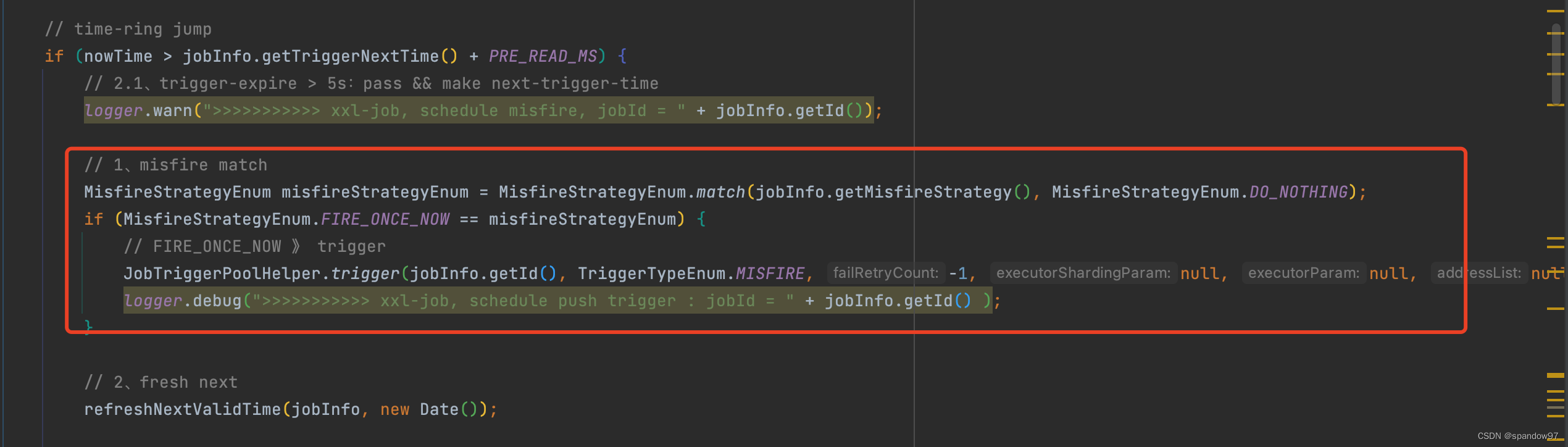
通过代码块可以看到,过期的定时任务是通过管理后台配置定时任务的调度过期策略决定的。
如果选择的是立即执行一次的话,就会触发定时任务执行。如果策略是忽略的话,就会跳过这个任务。不管过期策略是什么,都会根据corn表达式重置下次触发时间。
2、 超时未过5s的任务
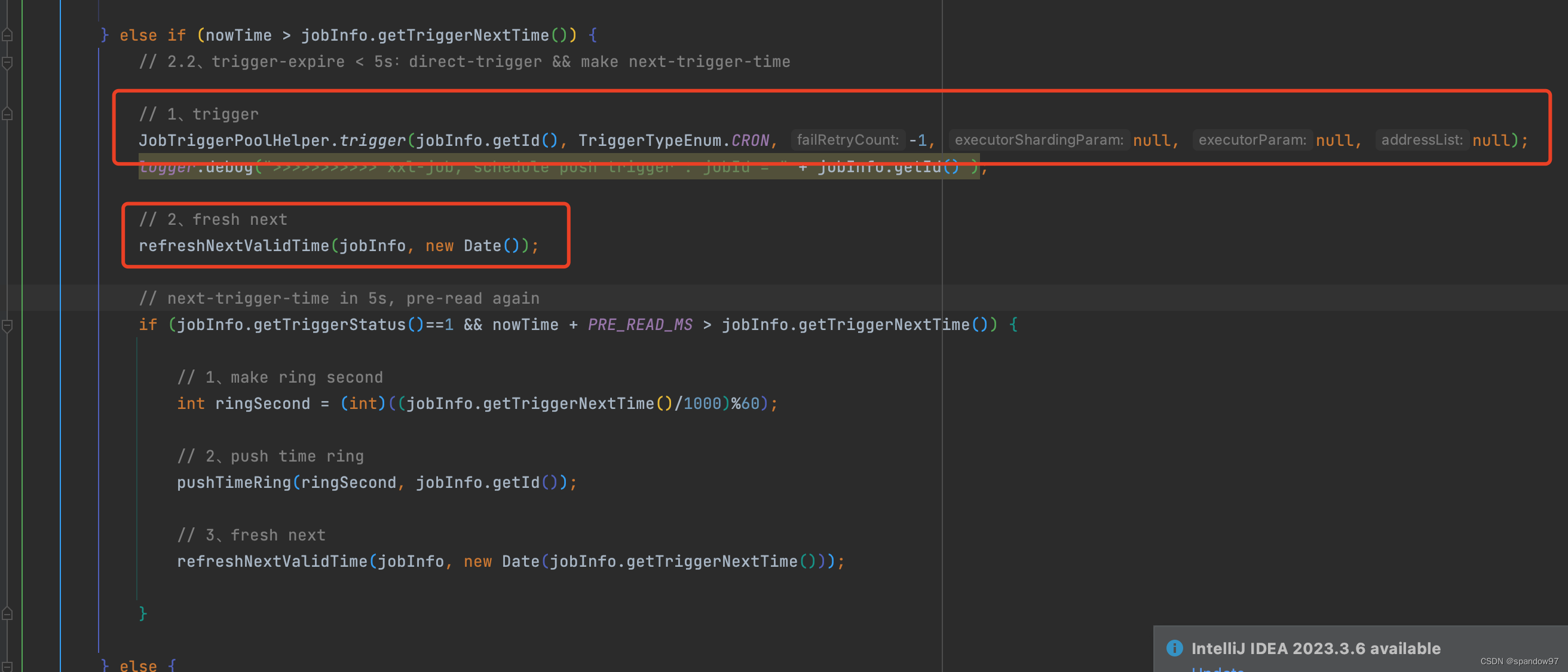
定时任务会直接触发,并且更新下次触发时间。如果下次触发时间在5s内的话,就会将这个任务直接放入时间轮中,由时间轮进行下一次调度,并且再次更新下次触发时间。
3、未开始的任务 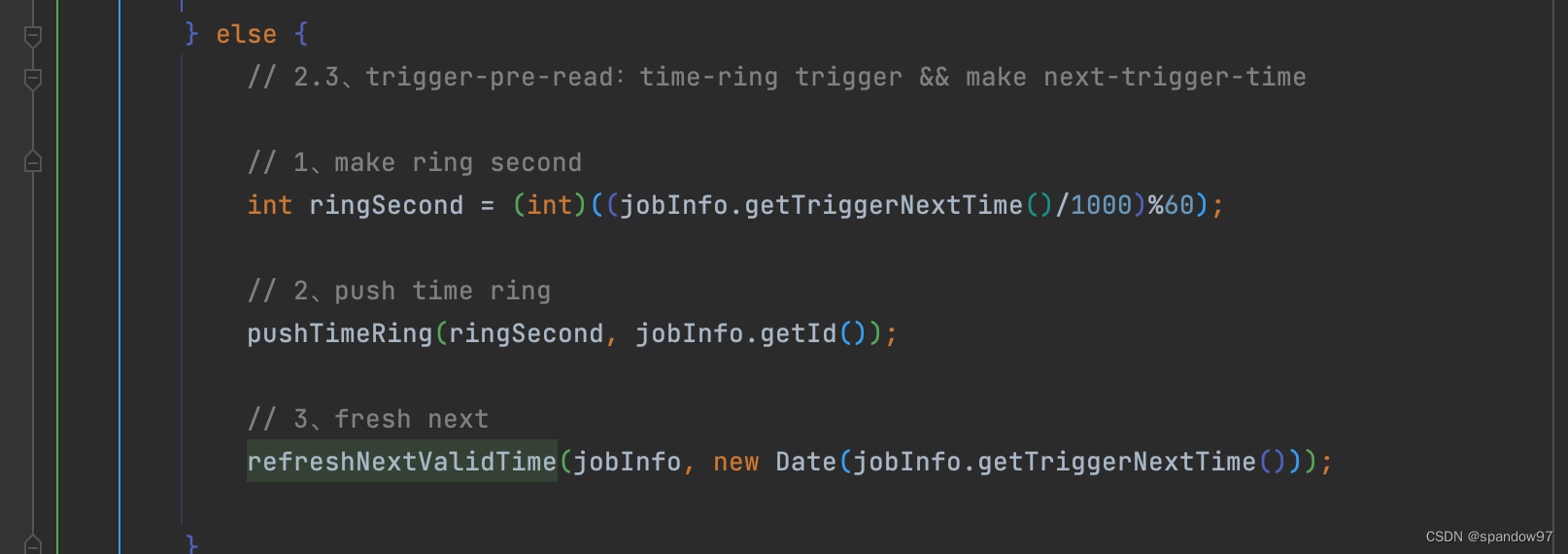
将任务放入时间轮中,并且重置下次触发时间。
时间轮是一种用于实现定时器、延时调度的一种常用算法。
通过算法算出next_tigger_time对应的秒数。范围在[0, 59].
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);然后以ringSecond为key,jobId为value存入到Map中。
private void pushTimeRing(int ringSecond, int jobId){
// push async ring
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
logger.debug(">>>>>>>>>>> xxl-job, schedule push time-ring : " + ringSecond + " = " + Arrays.asList(ringItemData) );
}接下来看一下时间轮线程是如何处理的:
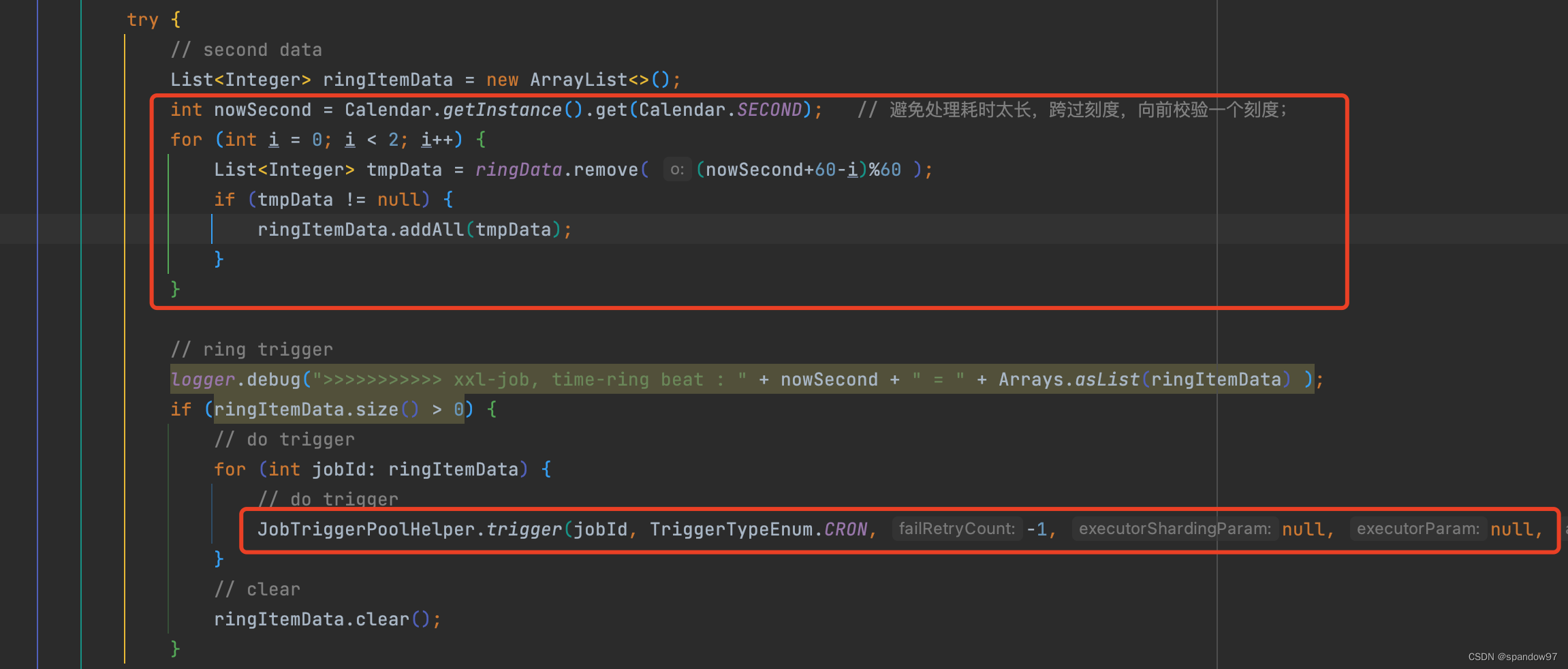
先获取当前时间的秒数,然后从时间轮中读取当前秒和前一秒的任务数据,然后执行。
为了避免任务执行时间长,所以读取前一秒的数据容错。
定时任务的查询和触发机制总结: 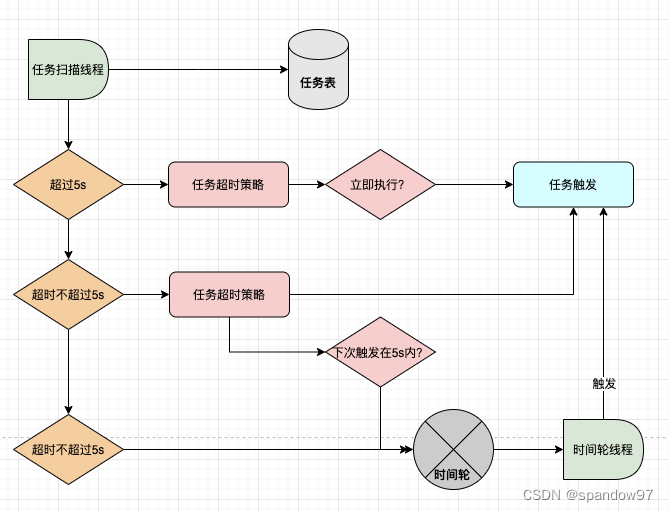
4.1.5、 任务触发
任务触发是将任务扔到线程池中异步执行。从代码中我们可以看到两个线程池,分别为快慢线程池。
目的是为了做隔离,将正常执行的任务放到快线程池中执行,将执行较慢的放到慢线程池中执行。避免任务执行过慢,影响其他任务正常调度。
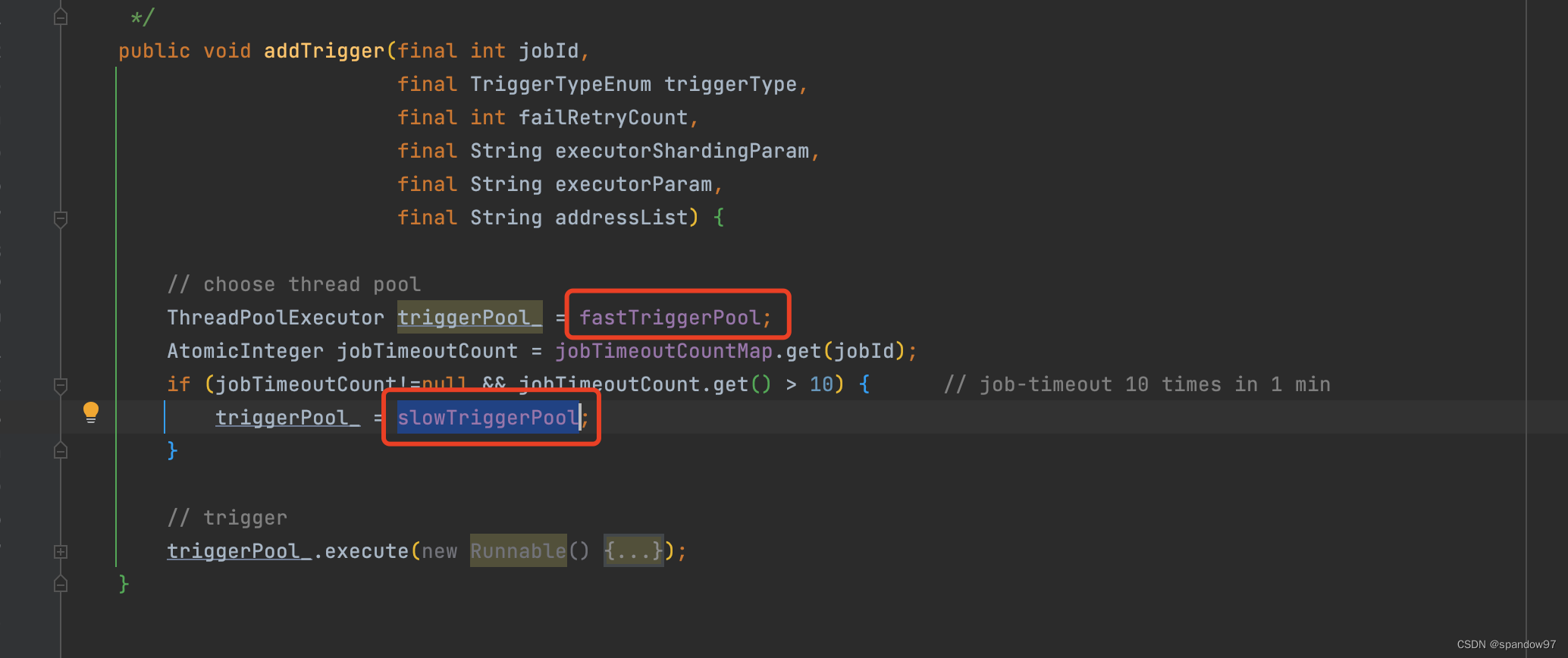
那什么样的任务算作是慢任务呢? xxl-job维护了一个计数器(jobTimeoutCountMap),其中key为jobId,value为超时次数。任务执行超过500ms时超时次数+1。当同一个任务在1min内超过10次,就人为是慢任务。
通过jobTimeoutCountMap判断当前任务类型从而使用对应的线程池执行触发逻辑。
任务触发执行的流程:
1、 使用jobId查询任务信息;
2、 参数处理
3、 根据路由策略找到对应的address。(通过路由策略确定对应的执行器实例)
4、 发送请求。
4.2、 执行器执行定时任务
我们平常用的都是SpringBoot为基础创建的项目,所以我们在创建任务处理器的时候,选择的都是Bean模式的执行器。
在前边的Demo中,我们初始化了一些执行器的参数,在那里我们用到了一个类XxlJobSpringExecutor。这个就是整个执行器的启动入口。
这个类实现了SmartInitializingSingleton接口,这个是spring提供的一个拓展点,在spring容器初始化对象完成后,可以额外做一些操作。在重写的afterSingletonsInstantiated方法中,xxl-job对任务处理器做了一些初始化的操作。
包含:
1、 初始化任务处理器;
2、 创建Http服务器;(这个我们前边3.2.2已经介绍过了)
3、 注册到调度中心;(这个我们前边3.2.2已经介绍过了)
4.2.1、 任务处理器初始化
这里我们主要介绍一下初始化任务处理器的逻辑。
JobHandler是一个定时任务的封装。一个定时任务对应一个IJobHandler对象。当执行器执行任务的时候,就会调用JobHandler的execute方法。
JobHandler有三种实现:MethodJobHandler、GlueJobHandler、ScriptJobHandler。
我们常用的就是MethodJobHandler,通过反射来调用方法执行任务。 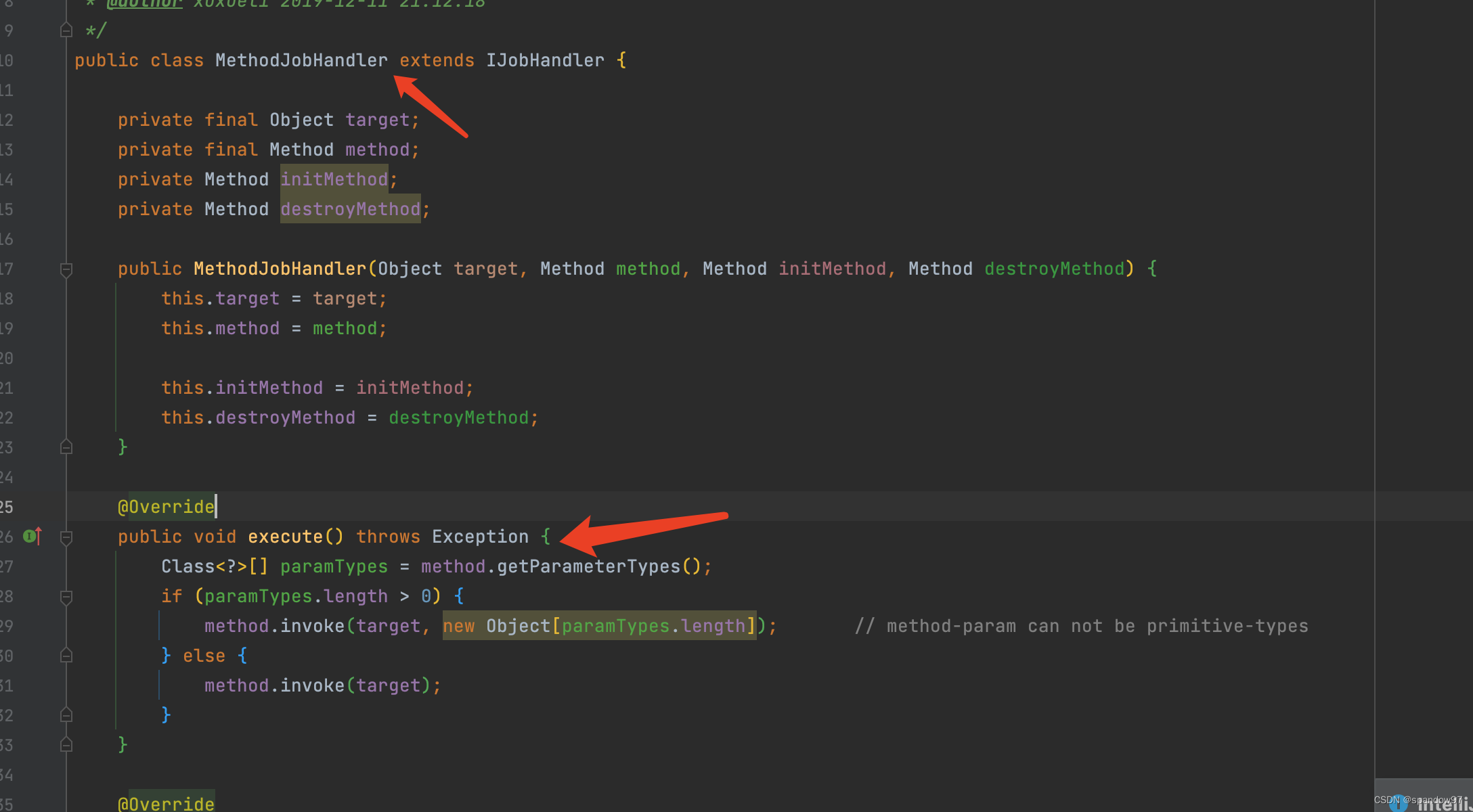
所以最终我们的定时任务都被封装成了一个MethodJobHandler。
在初始化执行器的时候,执行器会去spring容器中找到对应加了@XxlJob注解的Bean。解析注解,然后封装成一个MethodJobHandler对象,存储到XxlJobExecutor成员变量jobHandlerRepository中。
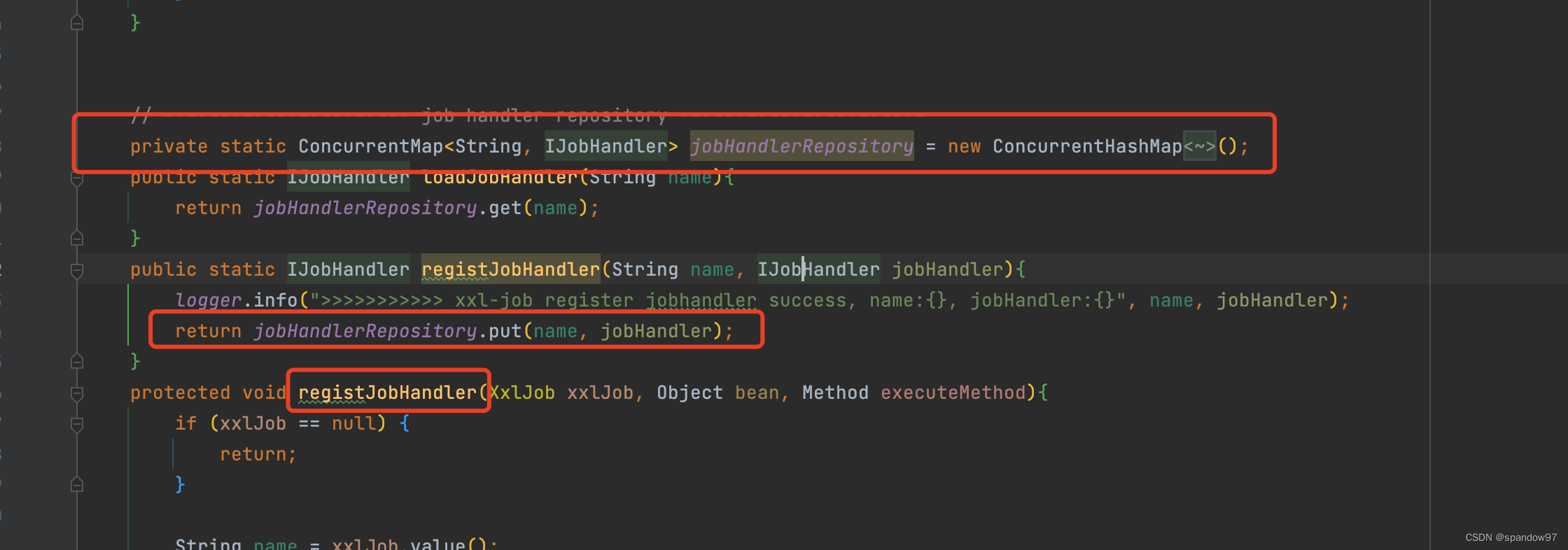
4.2.2、执行器处理定时任务
我们看一下收到请求后,xxl-job是如何处理请求的。
xxl-job给每一个任务处理器都分配了一个单独的线程做任务处理。好处就是任务之间解耦,互不影响。每次收到请求,都会根据jobId获取对应的任务线程,如果没有就创建一个放入线程池Map中。
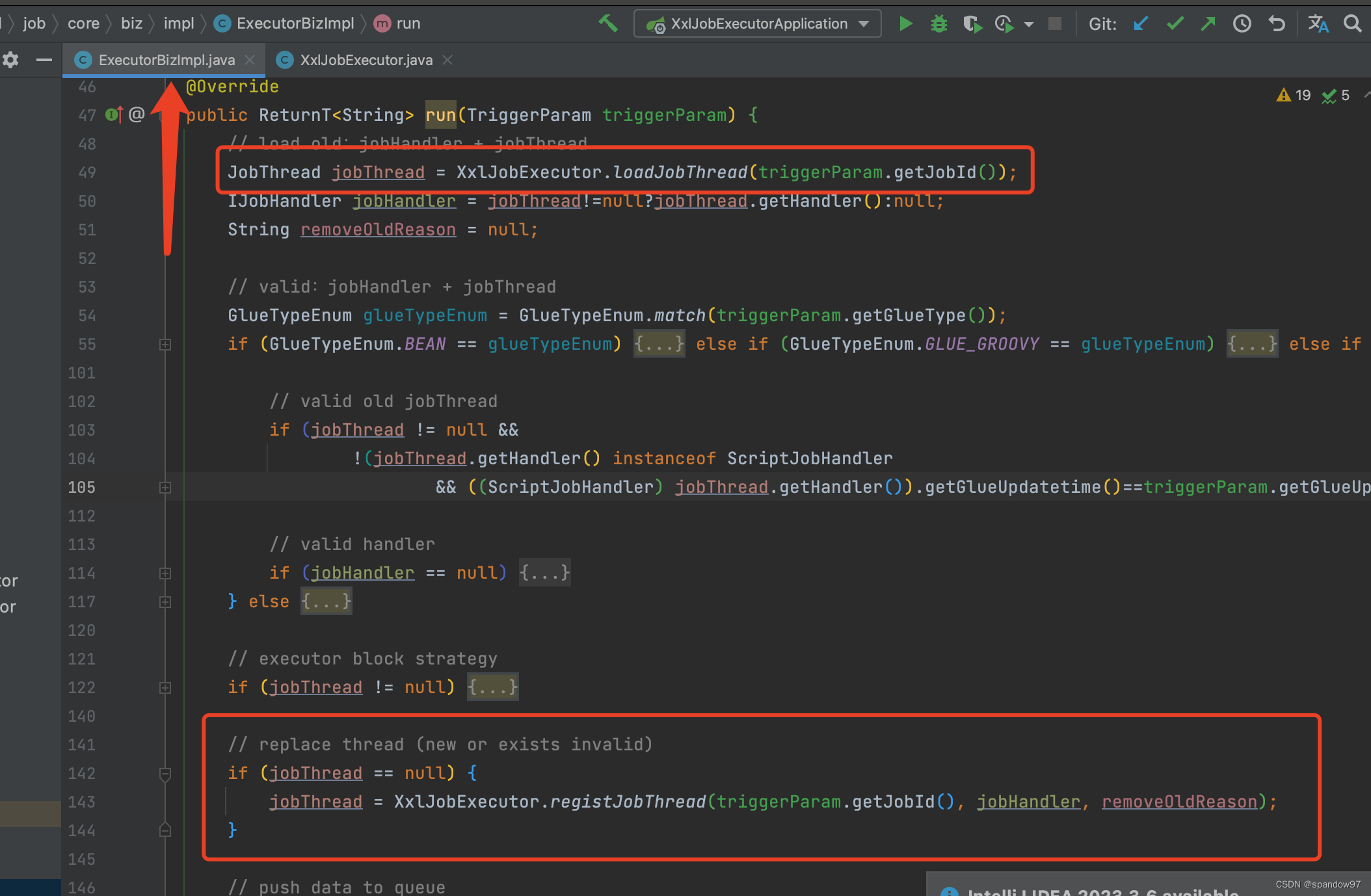
执行器收到请求后,任务并不会立即执行,而是会放到一个内存队列中去,执行线程从队列中获取要执行的任务。
通过增加一个内存队列,解决如果新任务到来,上一个任务还未处理完成的场景。通过队列对任务增加一个缓冲,而我们通过内存队列也可以对任务做一些策略处理。
接下来我们看过XXL-JOB提供了三种阻塞策略的判断,分别是:
- 单机串行:前一个任务执行完成后,才会执行下一个任务;将本次请求push到triggerQueue中。
- 丢弃后续地导读: 前一个任务还未完成,终止当前任务;如果triggerQueue中还有正在执行的任务,则不会将本次任务放入队列。
- 覆盖之前调度: 不管前一个任务是否完成,直接执行当前任务;重新创建一个jobThread执行任务,先前的线程通过Thread#interrupt方法打断,而后等待GC回收。
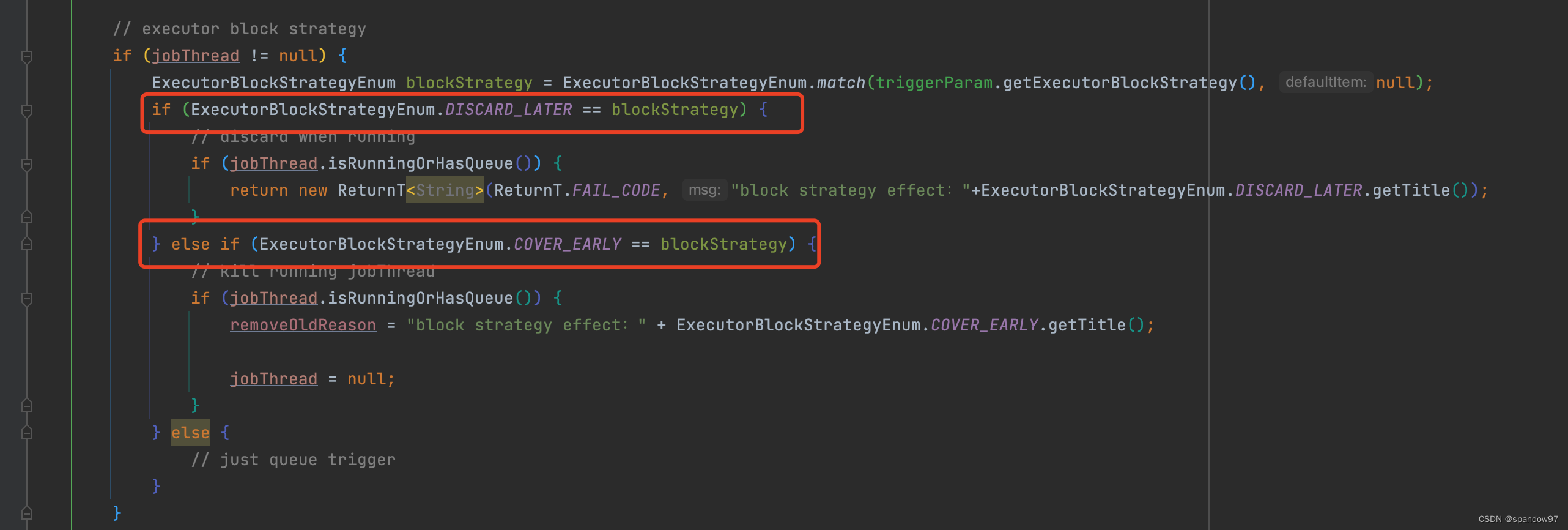
triggerQueue的类型是LinkedBlockingQueue,是一种阻塞队列。根据阻塞队列的特性,使用poll()方法获取队列头的任务,如果队列为空,那么当前线程会被阻塞,直到有新的任务push到队列中才会唤醒线程。
所以xxl-job使用了一个循环来获取队列中的任务,然后去执行。
代码中triggerQueue.poll(3L, TimeUnit.SECONDS)是 Java 中用于从队列中获取元素的操作,它的作用是尝试从队列中获取一个元素,在指定的时间内等待元素的到来。
接下来代码会判断是够任务设置了超时时间(定时任务配置的时候填写),如果设置了超时时间,就不会用当前线程来执行方法调用,而是通过futureTask来做异步调用,在get()方法传入超时时间,如果超过了设置的超时时间没有收到返回值,就会抛出超时异常,外层业务捕获到异常后,会中断此次线程执行,并将异常信息写入上下文中,通过回调流程返回给调度中心。
4.2.3、 任务结果回调
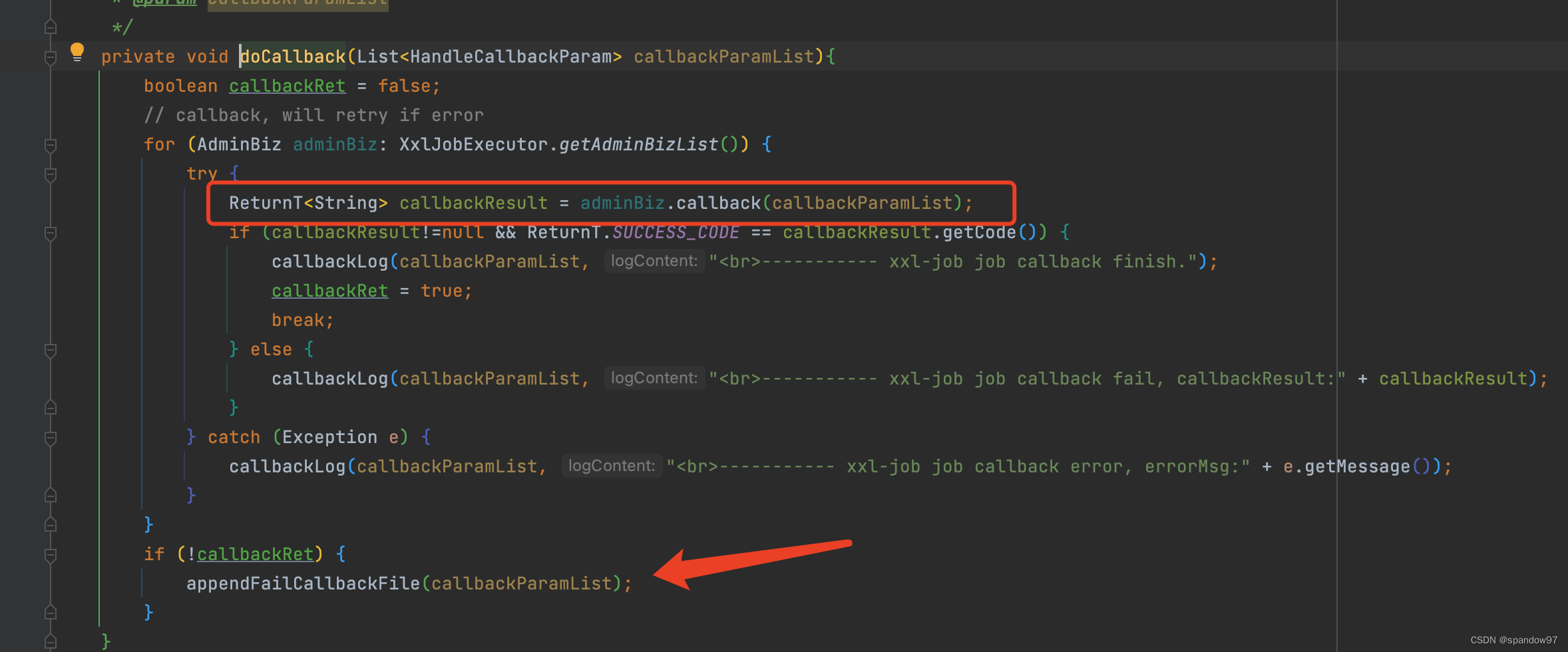
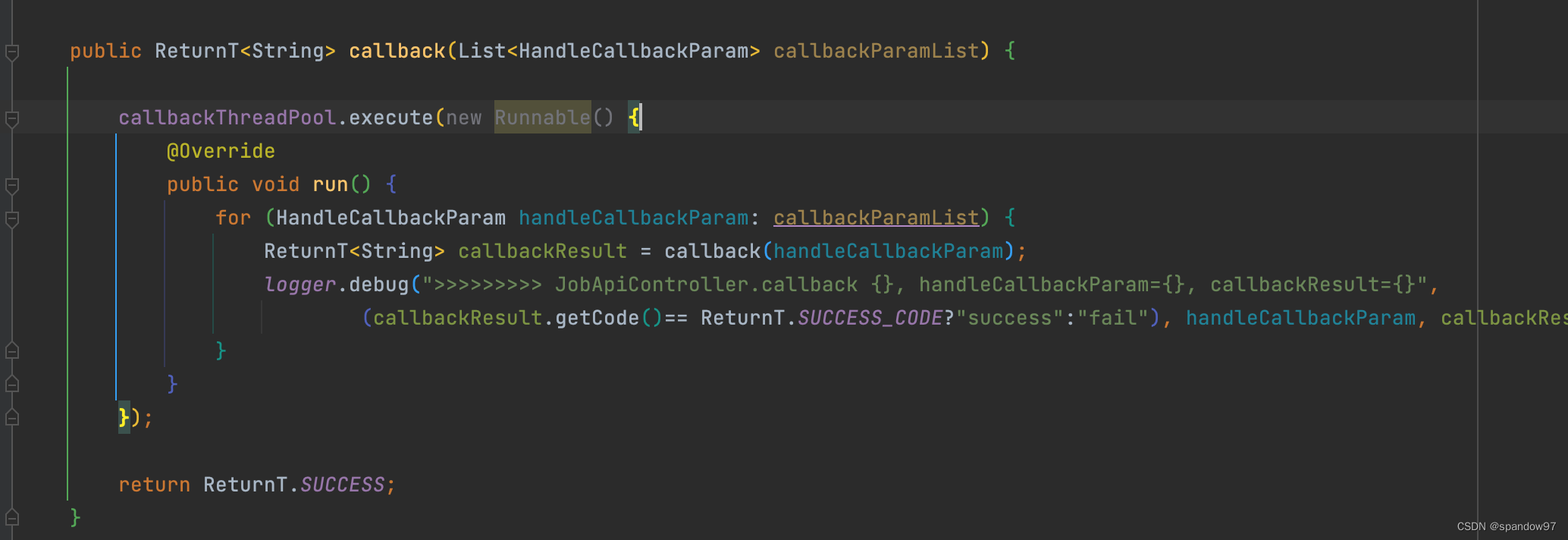
任务执行结果(正常执行完成、执行超时或者失败等),从上下文信息xxlJobContext中push到callBackQueue队列中,回调线程triggerCallBackThread会从队列中获取到信息,通过调用callBack方法回调调度中心。回调线程只有一个,是单例的,因为它只负责回传结果,一个就够用了。
调度中心收到请求后,通过callbackThreadPool线程池对回调请求做异步处理,
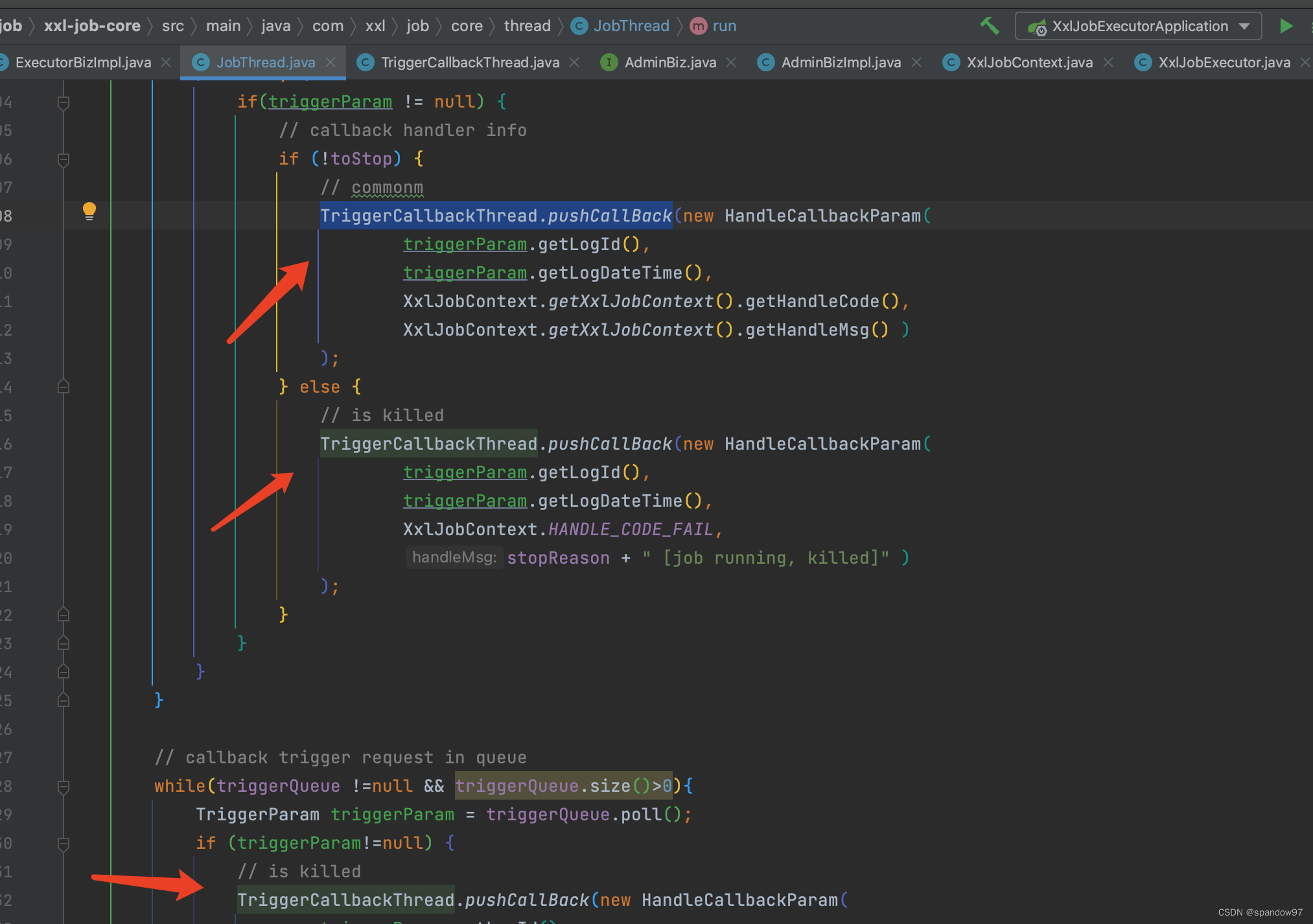
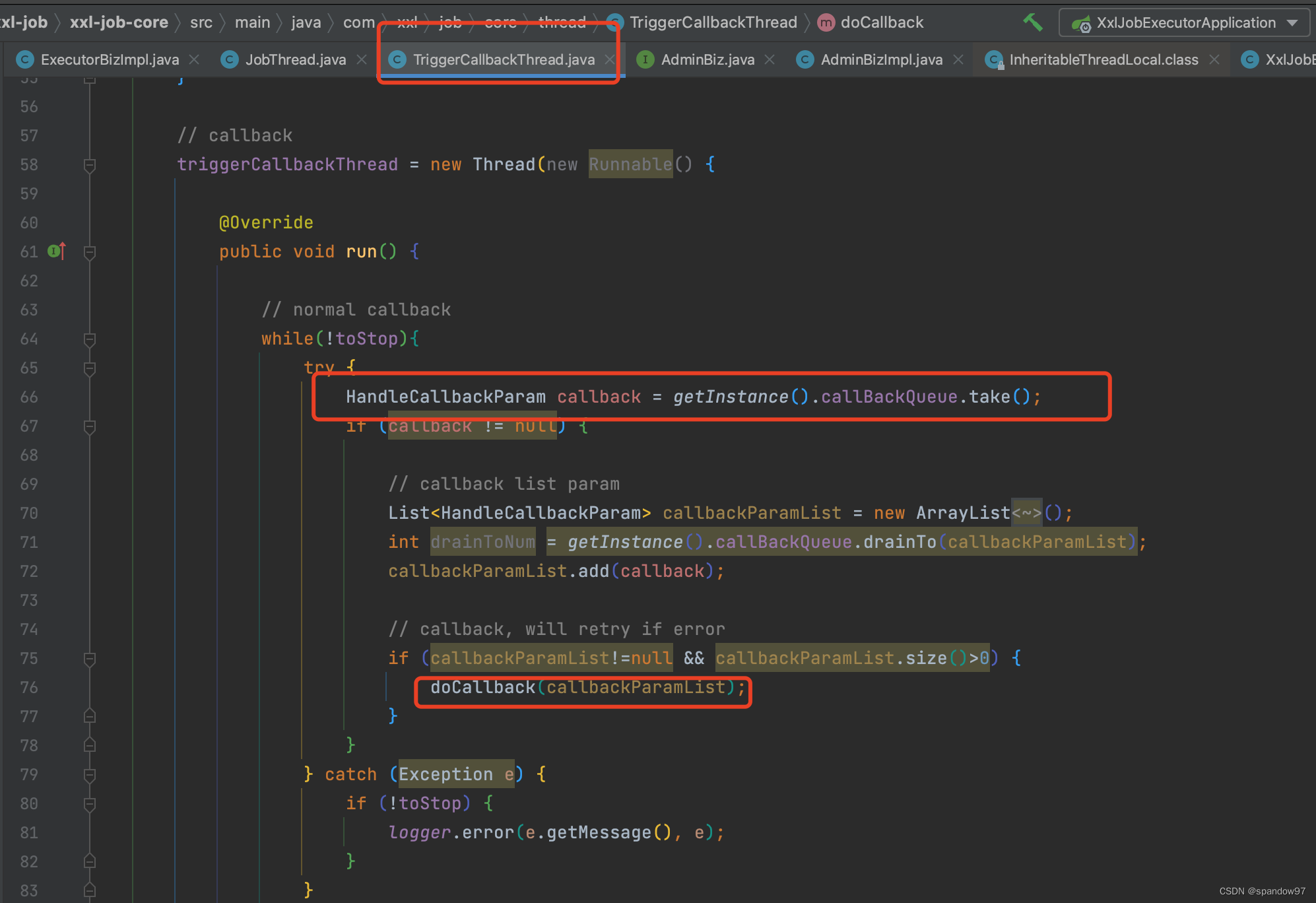
回调线程请求调度中心的回调接口,如果回调失败,会写入到文件中,然后通过一个重试回调线程triggerRetryCallbackThread继续尝试回调。
拓展:
xxlJobContext本质上是通过一个InheritableThreadLocal类似于ThreadLoacl的类存储上下文信息。
InheritableThreadLocal 是 Java 中的一个类,用于在多线程环境中,子线程可以继承父线程中设置的值。当一个线程创建子线程时,子线程会继承父线程的 InheritableThreadLocal 的值。这在某些场景下很有用,例如,当需要在整个线程执行过程中传递一些上下文信息,而不需要显式地传递给每个方法或对象时。同时也要记得使用完毕后及时清理。
五、 总结
XXL-JOB内置了一个类似于注册中心,在整个流程中使用了大量的一异步用法
- 通过线程池执行异步操作;
- 通过自旋线程+阻塞队列方式实现异步处理
XXL-JOB的整个流程梳理下来就是:
- 获取任务:调度线程不断扫描任务表,查询出要执行的任务;
- 前置处理:对每一个任务做一次触发时间的计算,然后将任务分级处理;
- 路由策略:在执行器集群中选择一个节点进行任务执行;
- 触发任务:调度线程不断从时间轮里获取任务并执行。
- 异步调度:调度中心将调度和触发做了异步处理(快慢线程池),使用触发线程池做Http请求。
- 阻塞策略:根据阻塞策略判断当前任务是否执行。
- 任务执行:每个任务创建一个线程去执行
- 任务回调:将执行结果回传到调度中心,更新任务状态。
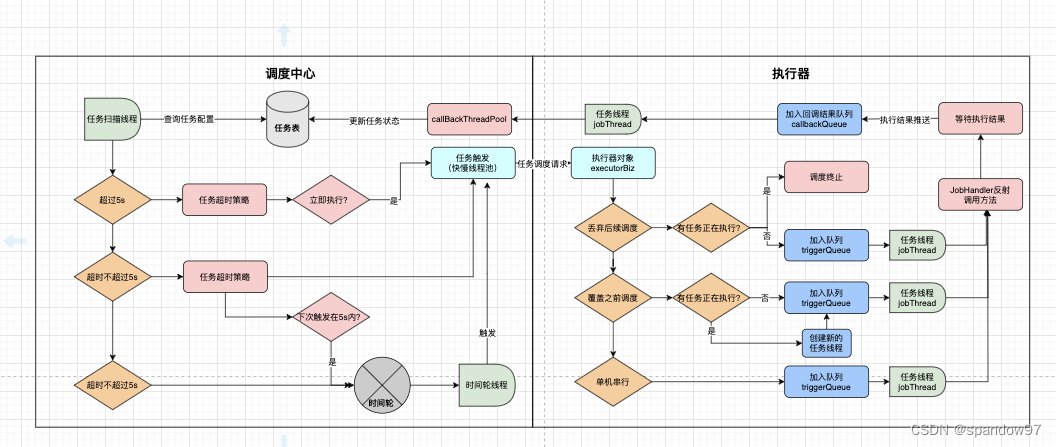
官网的XXL-JOB的架构图:

参考资料:
https://blog.youkuaiyun.com/qq_38249409/category_12171289.html

















 4347
4347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









