






阅读本教程之前,请你确定你还能进入你想阅读的问题。
下面,我要开始教大家爬虫了(本教程只作为免费的学术分享,本人不承担其他责任。请大家将代码和爬虫结果仅用于个人自学或学术用途,请遵守知乎使用规范。)。
想学吗?(手动坏笑)
安装Python/Anaconda软件(可以二选一,不过笔者两个都安装了),以及Python的IDE,Pycharm是用的最多的Python。
找到你想爬取评论的问题,并在问题中定位问题的编号。
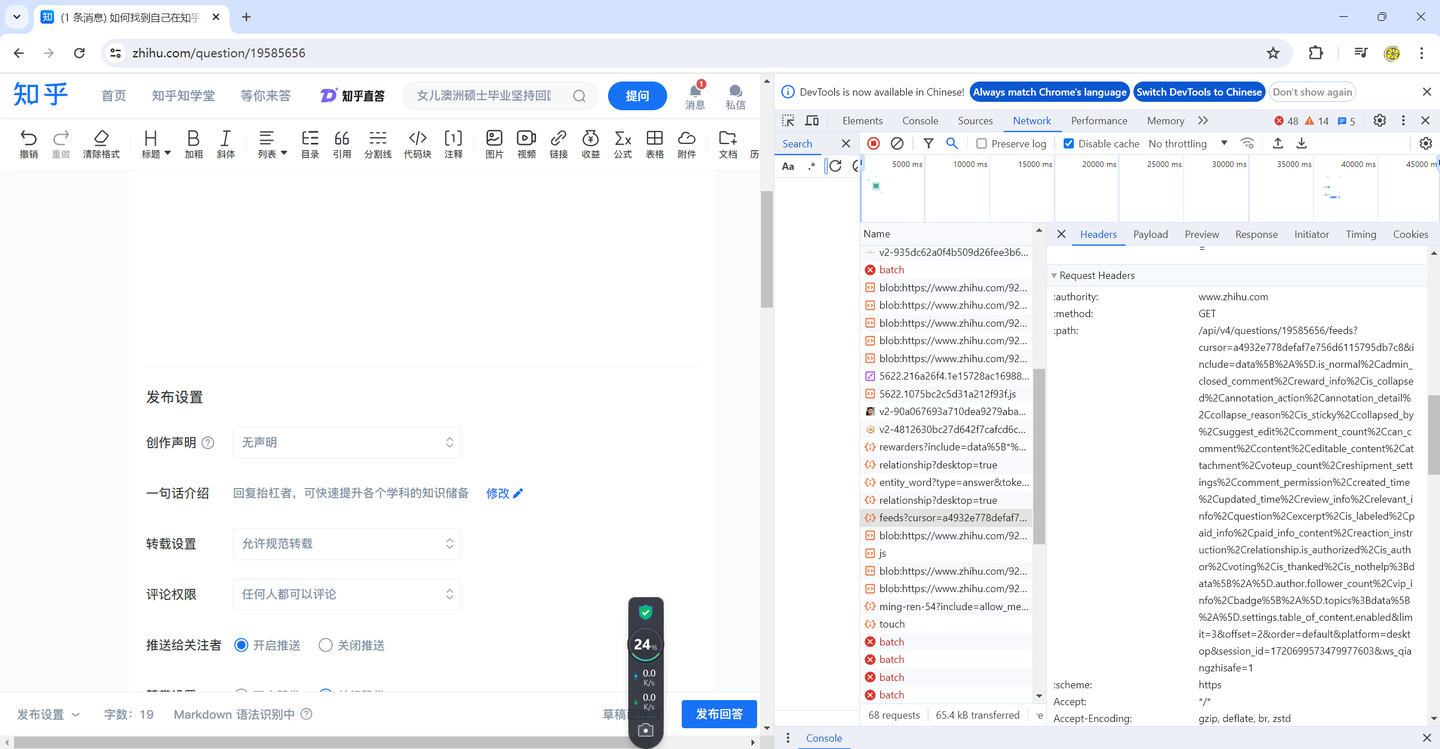
按F12(推荐谷歌浏览器),选择network选项卡。
不断下拉,一直看到有东西增加为止。
随便点开一个feed开头的东东。
找到path中的cursor信息
cookie缓存信息,
爬虫需要你自己粘贴替换cursor信息,cookie缓存信息,以及问题的编码。
将我的代码从网站上复制到你的Python IDE里。保存为py文件。
在py所在的文件夹的地址栏输入cmd,回车,
输入python+空格键+文件名。
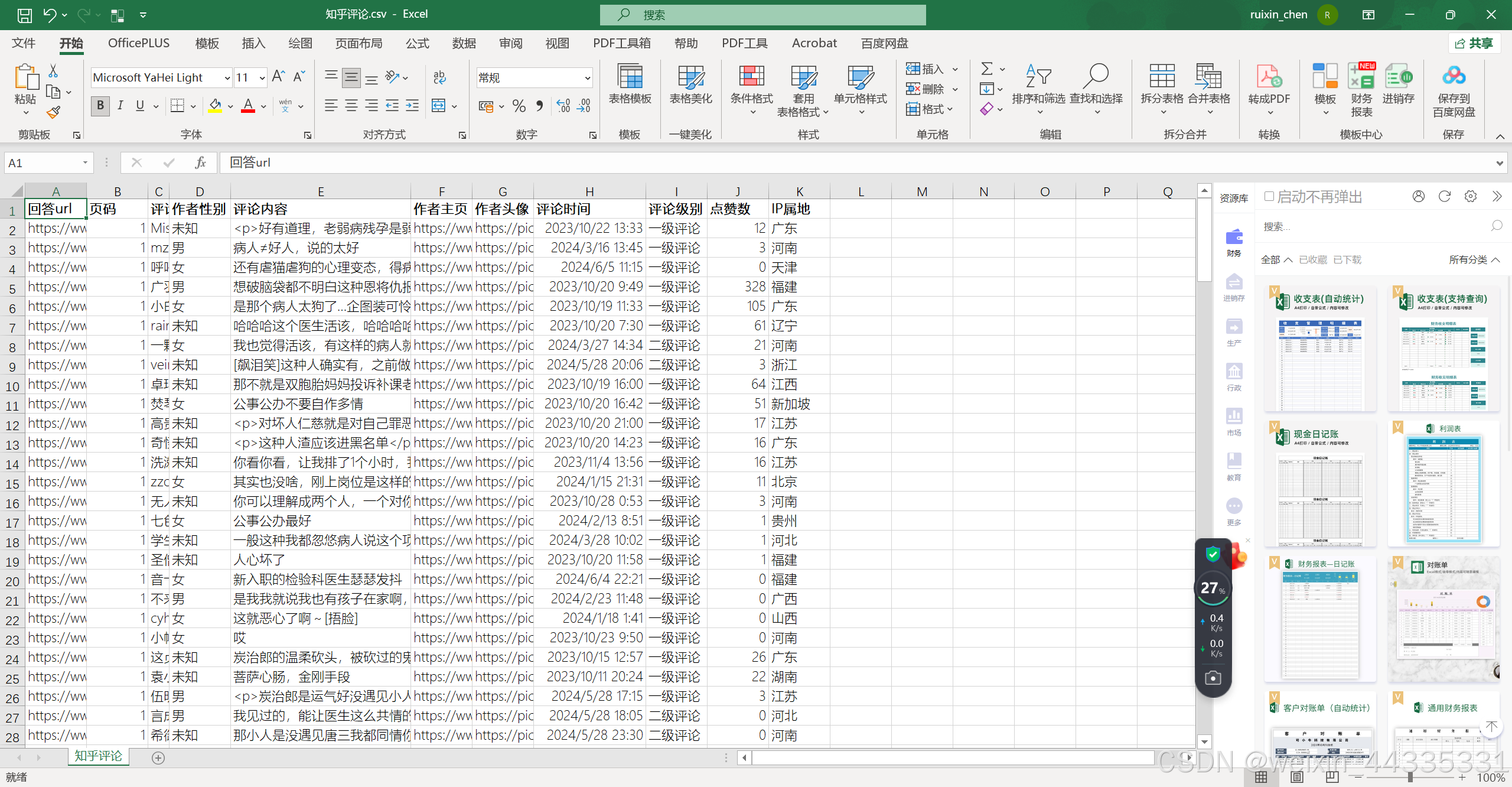
运行后得到csv文件。
然后,你在里面搜你的ID,就可以看到你的评论了。
代码是我自己反复调试的,保证真实有效。
需要修改的地方已经在代码里标记了,自己仔细看。
import requests
import time
import os
import pandas as pd
template = 'https://www.zhihu.com/?api开头的cursor信息'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
cookies = {
# 填自己的z_0 cookie
'cookie': r`#?`
}
# Initialize lists
answer_ids = []
# Fetch the initial page
url0 = template
resp0 = requests.get(url0, headers=headers, cookies=cookies)
next_page = resp0.json()['paging']['next']
for page in range(1, 3):
resp = requests.get(next_page, headers=headers, cookies=cookies)
print('正在爬取第' + str(page) + '页')
for data in resp.json()['data']:
answer_id = data['target']['id']
answer_ids.append(answer_id)
next_page = resp.json()['paging']['next']
time.sleep(3) # Adjust sleep time as needed
# 请求头
headers = {
'x-zse-93': '101_3_3.0',
'x-ab-param': 'se_ffzx_jushen1=0;zr_expslotpaid=1;top_test_4_liguangyi=1;qap_question_author=0;tp_dingyue_video=0;tp_topic_style=0;tp_contents=2;qap_question_visitor= 0;pf_noti_entry_num=2;tp_zrec=1;pf_adjust=1;zr_slotpaidexp=1',
'x-ab-pb': 'CroB1wKmBDMFdAHgBAsE4wQZBRsAaQFWBVIL5ArHAjMEEQU0DLULdQSiAwoE0QT0C58C7AqbCz8AQAG5AtgCVwTBBNoE4AsSBU8DbAThBMoCNwVRBUMA9wNFBNcLzwsqBEIEoANWDNwL9gJsAzQEBwyEAjIDFAVSBbcD6QQpBWALfQI/BY4DZAS0CvgDFQUPC1ADVwPoA9YEagGMAnIDMgU3DMwCVQUBC0cAzAQOBbQAKgI7AqED8wP0A4kMEl0AAAAAAAABAAAAAAEAAAAAAAMAAAEFAAIBAAABFQABAQEAAQAAAgAAABUBAQALAAEAAQAAAAABAAACBAABAAABAAEBAAEAAQAAAAIBAAEAAQAAAQABAAAAAQAAAAA=',
'x-zst-81': '3_2.0ae3TnRUTEvOOUCNMTQnTSHUZo02p-HNMZBO8YD_ycXtucXYqK6P0E79y-LS9-hp1DufI-we8gGHPgJO1xuPZ0GxCTJHR7820XM20cLRGDJXfgGCBxupMuD_Io4cpr4w0mRPO7HoY70SfquPmz93mhDQyiqV9ebO1hwOYiiR0ELYuUrxmtDomqU7ynXtOnAoTh_PhRDSTFHOsaDH_8UYq0CN9UBFM6Hg1f_FOYrOGwBoYrgcCjBL9hvx1oCYK8CVYUBeTv6u1pgcMzwV8wwt1EbrL-UXBgvg0Z9N__vem_C3L8vCZfMS_Uhoftck1UGg0Bhw1rrXKZgcVQQeC-JLZ28eqWcOxLGo_KX3OsquLquoXxDpMUuF_ChUCCqkwe7396qOZ-Je8ADS9CqcmUuoYsq98yqLmUggYsBXfbLVL3qHMjwS_mXefOComiDSOkUOfQqX00UeBUcnXAh3mMD31bgOYSTSufuCYuDgCjqefWqHYeQSC',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-app-version': '6.42.0',
'sec-ch-ua-mobile': '?0',
'x-requested-with': 'fetch',
'x-zse-96': '2.0_aHtyee9qUCtYHUY81LF8NgU0NqNxgUF0MHYyoHe0NG2f',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'accept': '*/*',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'accept-language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'cookie': r`#?`
}
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
def tran_gender(gender_tag):
"""转换性别"""
if gender_tag == 1:
return '男'
elif gender_tag == 0:
return '女'
else: # -1
return '未知'
def comment_spider(v_result_file, v_answer_list):
for answer_id in v_answer_list:
url0 = 'https://www.zhihu.com/api/v4/answers/{}/root_comments?order=normal&limit=20&offset=0&status=open'.format(
answer_id)
r0 = requests.get(url0, headers=headers) # 发送请求
total = r0.json()['common_counts'] # 一共多少条评论
print('一共{}条评论'.format(total))
if total == 0:
continue
# 判断一共多少页(每页20条评论)
max_page = (total + 19) // 20 # 计算总页数,确保即使评论总数小于20,也能进入循环爬取
print('max_page:', max_page)
# 开始循环爬取
for i in range(max_page):
offset = i * 20
url = 'https://www.zhihu.com/api/v4/answers/{}/root_comments?order=normal&limit=20&offset={}&status=open'.format(
answer_id,
str(offset))
r = requests.get(url, headers=headers)
print('正在爬取第{}页'.format(i + 1))
j_data = r.json()
comments = j_data['data']
# 如果没有评论了,就结束循环
if not comments:
print('无评论,退出循环')
break
# 否则开始爬取
# 定义空列表用于存数据
answer_urls = [] # 回答url
authors = [] # 评论作者
genders = [] # 作者性别
author_homepages = [] # 作者主页
author_pics = [] # 作者头像
create_times = [] # 评论时间
contents = [] # 评论内容
child_tag = [] # 评论级别
vote_counts = [] # 点赞数
ip_list = [] # IP属地
for c in comments: # 一级评论
# 回答url
answer_urls.append('https://www.zhihu.com/answer/' + str(answer_id))
# 评论作者
author = c['author']['member']['name']
authors.append(author)
print('作者:', author)
# 作者性别
gender_tag = c['author']['member']['gender']
genders.append(tran_gender(gender_tag))
# 作者主页
homepage = 'https://www.zhihu.com/people/' + c['author']['member']['url_token']
author_homepages.append(homepage)
# 作者头像
pic = c['author']['member']['avatar_url']
author_pics.append(pic)
# 评论时间
create_time = trans_date(c['created_time'])
create_times.append(create_time)
# 评论内容
comment = c['content']
contents.append(comment)
print('评论内容:', comment)
# 评论级别
child_tag.append('一级评论')
# 点赞数
vote_counts.append(c['vote_count'])
# IP属地
ip_list.append(c['address_text'].replace('IP 属地', ''))
if c['child_comments']: # 如果二级评论存在
for child in c['child_comments']: # 二级评论
# 回答url
answer_urls.append('https://www.zhihu.com/answer/' + str(answer_id))
# 评论作者
print('子评论作者:', child['author']['member']['name'])
authors.append(child['author']['member']['name'])
# 作者性别
genders.append(tran_gender(child['author']['member']['gender']))
# 作者主页
author_homepages.append(
'https://www.zhihu.com/people/' + child['author']['member']['url_token'])
# 作者头像
author_pics.append(child['author']['member']['avatar_url'])
# 评论时间
create_times.append(trans_date(child['created_time']))
# 评论内容
print('子评论内容:', child['content'])
contents.append(child['content'])
# 评论级别
child_tag.append('二级评论')
# 点赞数
vote_counts.append(child['vote_count'])
# IP属地
ip_list.append(child['address_text'].replace('IP 属地', ''))
# 保存数据到csv
header = True
if os.path.exists(csv_file): # 如果csv存在,不写表头,避免重复写入表头
header = False
df = pd.DataFrame(
{
'回答url': answer_urls,
'页码': [i + 1] * len(answer_urls),
'评论作者': authors,
'作者性别': genders,
'评论内容': contents,
'作者主页': author_homepages,
'作者头像': author_pics,
'评论时间': create_times,
'评论级别': child_tag,
'点赞数': vote_counts,
'IP属地': ip_list,
}
)
# 保存到csv文件
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
if __name__ == '__main__':
csv_file = '知乎评论.csv'
# 如果csv存在,先删除,避免由于追加产生重复数据
if os.path.exists(csv_file):
print('文件存在,删除:{}'.format(csv_file))
os.remove(csv_file)
# 开始爬取
comment_spider(v_result_file=csv_file, # 保存文件名
v_answer_list=answer_ids) # 使用第一步爬取的answer_ids
print('爬虫执行完毕!')
学R语言3天就够了,至少可以画地图热图了;
学Python 3天也够了,至少可以爬取知乎的回答和评论了。
(当然,两个语言爬虫我都会)

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









