import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import sklearn.metrics as metrics
from sklearn.ensemble import RandomForestClassifier
import seaborn as sns
torch.manual_seed(42)
np.random.seed(42)
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))
])
class FeatureExtractorCNN(nn.Module):
def __init__(self):
super(FeatureExtractorCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = F.relu(self.conv3(x))
x = self.pool(x)
x = self.global_avg_pool(x)
x = x.view(x.size(0), -1)
return x
def main():
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=0)
device = torch.device("cuda"if torch.cuda.is_available() else "cpu")
cnn_model = FeatureExtractorCNN().to(device)
fc_classifier = nn.Linear(256, 10).to(device)
optimizer_all = optim.Adam(list(cnn_model.parameters()) + list(fc_classifier.parameters()), lr=0.001)
criterion = nn.CrossEntropyLoss()
train_loss_list = []
val_acc_list = []
num_epochs = 10
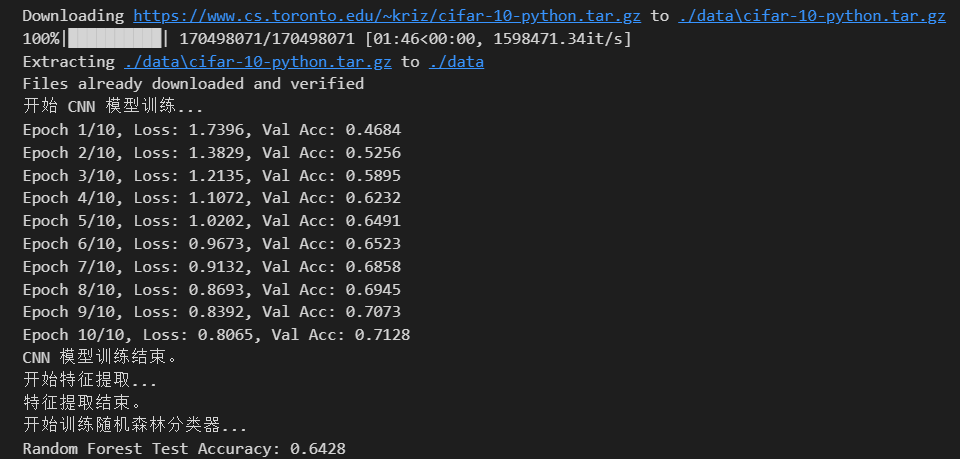
print("开始 CNN 模型训练...")
for epoch in range(num_epochs):
cnn_model.train()
fc_classifier.train()
running_loss = 0.0
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
optimizer_all.zero_grad()
features = cnn_model(images)
outputs = fc_classifier(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer_all.step()
running_loss += loss.item() * images.size(0)
epoch_loss = running_loss / len(trainset)
train_loss_list.append(epoch_loss)
cnn_model.eval()
fc_classifier.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
features = cnn_model(images)
outputs = fc_classifier(features)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_acc = correct / total
val_acc_list.append(val_acc)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}, Val Acc: {val_acc:.4f}")
print("CNN 模型训练结束。")
print("开始特征提取...")
cnn_model.eval()
train_features, train_labels = [], []
with torch.no_grad():
for images, labels in trainloader:
images = images.to(device)
feats = cnn_model(images)
train_features.append(feats.cpu().numpy())
train_labels.append(labels.numpy())
train_features = np.concatenate(train_features, axis=0)
train_labels = np.concatenate(train_labels, axis=0)
test_features, test_labels = [], []
with torch.no_grad():
for images, labels in testloader:
images = images.to(device)
feats = cnn_model(images)
test_features.append(feats.cpu().numpy())
test_labels.append(labels.numpy())
test_features = np.concatenate(test_features, axis=0)
test_labels = np.concatenate(test_labels, axis=0)
print("特征提取结束。")
print("开始训练随机森林分类器...")
rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)
rf_classifier.fit(train_features, train_labels)
rf_pred = rf_classifier.predict(test_features)
rf_pred_proba = rf_classifier.predict_proba(test_features)
rf_acc = metrics.accuracy_score(test_labels, rf_pred)
print(f"Random Forest Test Accuracy: {rf_acc:.4f}")
plt.figure(figsize=(16, 12))
plt.subplot(2, 2, 1)
plt.plot(range(1, num_epochs+1), train_loss_list, marker='o', linestyle='-', color='red')
plt.title("title: Training Loss Curve", fontsize=14)
plt.xlabel("label: Epoch", fontsize=12)
plt.ylabel("Loss", fontsize=12)
plt.grid(True)
plt.subplot(2, 2, 2)
plt.plot(range(1, num_epochs+1), val_acc_list, marker='s', linestyle='-', color='blue')
plt.title("title: Validation Accuracy Curve", fontsize=14)
plt.xlabel("label: Epoch", fontsize=12)
plt.ylabel("Accuracy", fontsize=12)
plt.grid(True)
plt.subplot(2, 2, 3)
cm = metrics.confusion_matrix(test_labels, rf_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="YlGnBu")
plt.title("title: Confusion Matrix", fontsize=14)
plt.xlabel("label: Predicted", fontsize=12)
plt.ylabel("label: True", fontsize=12)
plt.subplot(2, 2, 4)
sample_index = np.random.randint(0, len(test_features))
sample_proba = rf_pred_proba[sample_index]
plt.bar(range(10), sample_proba, color=plt.cm.tab10.colors)
plt.title("title: Prediction Probability", fontsize=14)
plt.xlabel("label: Class", fontsize=12)
plt.ylabel("Probability", fontsize=12)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
main()
1. 代码结构
| 模块 | 功能 |
|---|
| 数据预处理 | 对CIFAR-10数据进行增强(随机裁剪、翻转)和标准化 |
| CNN模型定义 | 3层卷积网络 + 全局平均池化,输出256维特征向量 |
| 主训练流程 | 训练CNN+全连接层分类器,记录损失和验证准确率 |
| 特征提取 | 用训练好的CNN提取训练集/测试集的特征向量 |
| 随机森林分类 | 用CNN提取的特征训练随机森林,评估测试集性能 |
| 可视化 | 绘制训练曲线、混淆矩阵和样本预测概率分布 |
2. 关键代码分析
(1) 数据预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 数据增强:随机裁剪
transforms.RandomHorizontalFlip(), # 数据增强:水平翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR-10均值/标准差
])
- 训练集使用数据增强(提升模型泛化能力),测试集仅做标准化。
(2) CNN模型架构
class FeatureExtractorCNN(nn.Module):
def __init__(self):
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1) # 3通道→64通道
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化替代全连接层
- 输出特征维度:
256x1x1(通过view展平为256维向量)。 - 设计意图:CNN仅作为特征提取器,不直接输出分类结果。
(3) 训练流程
# 联合优化CNN和全连接层
optimizer_all = optim.Adam(list(cnn_model.parameters()) + list(fc_classifier.parameters()), lr=0.001)
for epoch in range(num_epochs):
features = cnn_model(images) # 提取特征
outputs = fc_classifier(features) # 分类
loss = criterion(outputs, labels) # 交叉熵损失
loss.backward() # 反向传播
- 优化目标:最小化交叉熵损失(
nn.CrossEntropyLoss)。 - Batch Size:128,适合中等规模GPU显存。
(4) 随机森林分类
rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=10)
rf_classifier.fit(train_features, train_labels) # 训练随机森林
rf_acc = metrics.accuracy_score(test_labels, rf_pred)
- 输入数据:CNN提取的256维特征(
train_features)。 - 参数选择:100棵树,最大深度10(防止过拟合)。
(5) 可视化
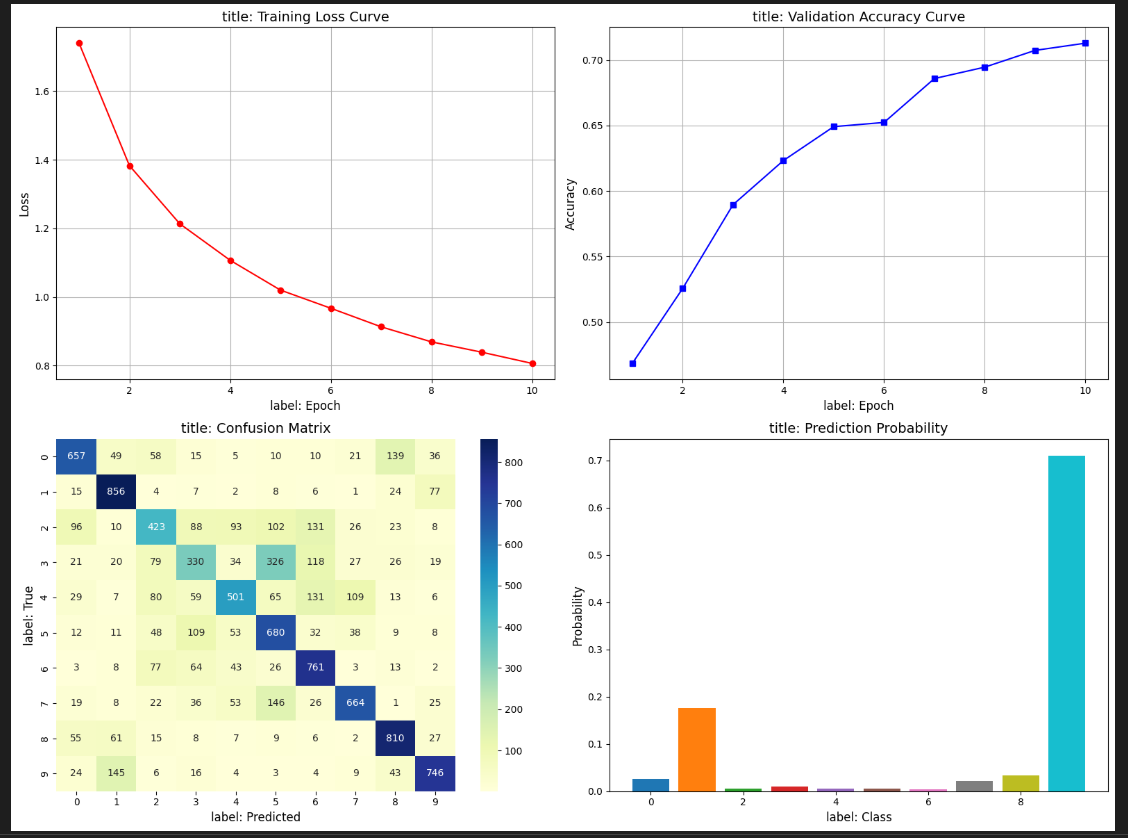
- 训练曲线:损失和准确率随epoch的变化。
- 混淆矩阵:随机森林在测试集上的分类细节。
- 概率分布:随机森林对某个样本的类别概率预测。
3. 问题与改进
| 问题点 | 改进建议 |
|---|
| CNN结构较简单 | 增加深度(如ResNet块)或使用预训练模型(如ResNet18) |
| 随机森林参数固定 | 通过网格搜索优化n_estimators和max_depth |
| 特征提取后未降维 | 可尝试PCA降低特征维度,加速随机森林训练 |
| 设备兼容性 | 显式检查CUDA可用性(如device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")) |


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









