




import numpy as np
from collections import defaultdict
import matplotlib.pyplot as plt
import seaborn as sns
class DistributedQLearningAgent:
def __init__(self, n_actions, learning_rate=0.1, discount_factor=0.9, exploration_rate=0.1):
self.q_table = defaultdict(lambda: np.zeros(n_actions))
self.alpha = learning_rate
self.gamma = discount_factor
self.epsilon = exploration_rate
self.n_actions = n_actions
def choose_action(self, state):
if np.random.random() < self.epsilon:
return np.random.choice(self.n_actions)
else:
return np.argmax(self.q_table[state])
def learn(self, state, action, reward, next_state, neighbors_q_tables):
max_neighbor_q = -np.inf
for neighbor_q in neighbors_q_tables:
neighbor_max_q = np.max(neighbor_q[next_state])
if neighbor_max_q > max_neighbor_q:
max_neighbor_q = neighbor_max_q
if max_neighbor_q == -np.inf:
max_neighbor_q = np.max(self.q_table[next_state])
td_target = reward + self.gamma * max_neighbor_q
td_error = td_target - self.q_table[state][action]
self.q_table[state][action] += self.alpha * td_error
# 参数设置
n_agents = 3
n_actions = 2
n_states = 5
agents = [DistributedQLearningAgent(n_actions) for _ in range(n_agents)]
# 奖励函数
def get_reward(state, action):
return np.random.normal(loc=state*action, scale=0.1)
# 训练过程
episode_rewards = []
for episode in range(1000):
states = [np.random.randint(0, n_states) for _ in range(n_agents)]
episode_reward = 0
for t in range(100):
actions = [agent.choose_action(state) for agent, state in zip(agents, states)]
rewards = [get_reward(state, action) for state, action in zip(states, actions)]
episode_reward += sum(rewards)
next_states = [(state + action) % n_states for state, action in zip(states, actions)]
for i in range(n_agents):
neighbors = [agents[j].q_table for j in range(n_agents) if j != i]
agents[i].learn(states[i], actions[i], rewards[i], next_states[i], neighbors)
states = next_states
episode_rewards.append(episode_reward)
# 1. 打印所有智能体的Q表
for i, agent in enumerate(agents):
print(f"\nAgent {i+1} Q-table:")
for state in range(n_states):
print(f"State {state}: {agent.q_table[state]}")
# 2. 可视化Q值矩阵
plt.figure(figsize=(15, 5))
for i, agent in enumerate(agents):
plt.subplot(1, n_agents, i+1)
# 将Q表转换为矩阵
q_matrix = np.zeros((n_states, n_actions))
for state in range(n_states):
q_matrix[state] = agent.q_table[state]
# 绘制热力图
sns.heatmap(q_matrix, annot=True, fmt=".2f", cmap="YlGnBu",
xticklabels=[f"Action {a}" for a in range(n_actions)],
yticklabels=[f"State {s}" for s in range(n_states)])
plt.title(f"Agent {i+1} Q-Value Matrix")
plt.tight_layout()
# 3. 绘制奖励曲线
plt.figure(figsize=(10, 5))
plt.plot(episode_rewards, alpha=0.3, label='Episode Reward')
window_size = 50
moving_avg = np.convolve(episode_rewards, np.ones(window_size)/window_size, mode='valid')
plt.plot(np.arange(window_size-1, len(episode_rewards)), moving_avg, 'r-',
linewidth=2, label=f'Moving Average (window={window_size})')
plt.title("System Reward Over Episodes")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.legend()
plt.grid(True)
plt.show()
以下是对这段代码的详细解释,分为核心类、训练流程和可视化三个部分:
一、DistributedQLearningAgent 类(核心算法)
class DistributedQLearningAgent:
def __init__(self, n_actions, learning_rate=0.1, discount_factor=0.9, exploration_rate=0.1):
self.q_table = defaultdict(lambda: np.zeros(n_actions)) # 状态-动作值表
self.alpha = learning_rate # 学习率(更新步长)
self.gamma = discount_factor # 折扣因子(未来奖励权重)
self.epsilon = exploration_rate # 探索率
self.n_actions = n_actions # 动作空间大小
关键方法:
- 动作选择 (ε-greedy策略)
def choose_action(self, state):
if np.random.random() < self.epsilon: # 以ε概率随机探索
return np.random.choice(self.n_actions)
else: # 以1-ε概率选择最优动作
return np.argmax(self.q_table[state])
- 分布式Q学习更新
def learn(self, state, action, reward, next_state, neighbors_q_tables):
# 从邻居Q表中获取最大Q值(核心分布式逻辑)
max_neighbor_q = max([np.max(q[next_state]) for q in neighbors_q_tables], default=-np.inf)
# 无邻居时使用自身Q值
if max_neighbor_q == -np.inf:
max_neighbor_q = np.max(self.q_table[next_state])
# Q学习更新公式
td_target = reward + self.gamma * max_neighbor_q # 目标值
td_error = td_target - self.q_table[state][action] # 时序差分误差
self.q_table[state][action] += self.alpha * td_error # 更新Q值
二、训练流程
1. 初始化设置
n_agents = 3 # 智能体数量
n_actions = 2 # 每个智能体的动作数
n_states = 5 # 状态空间大小
agents = [DistributedQLearningAgent(n_actions) for _ in range(n_agents)] # 创建智能体群
2. 环境交互逻辑
def get_reward(state, action):
# 定义奖励函数:基于状态和动作的线性关系+高斯噪声
return np.random.normal(loc=state*action, scale=0.1)
3. 主训练循环
for episode in range(1000): # 1000轮训练
states = [np.random.randint(0, n_states) for _ in range(n_agents)] # 随机初始状态
for t in range(100): # 每轮最多100步
# 1. 所有智能体选择动作
actions = [agent.choose_action(state) for agent, state in zip(agents, states)]
# 2. 获取奖励和转移状态
rewards = [get_reward(state, action) for state, action in zip(states, actions)]
next_states = [(state + action) % n_states for state, action in zip(states, actions)] # 循环状态空间
# 3. 分布式学习
for i in range(n_agents):
neighbors = [agents[j].q_table for j in range(n_agents) if j != i] # 获取邻居Q表
agents[i].learn(states[i], actions[i], rewards[i], next_states[i], neighbors)
states = next_states # 状态更新
episode_rewards.append(sum(rewards)) # 记录本轮总奖励
三、结果可视化
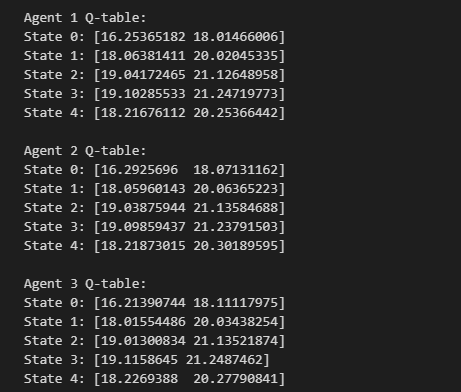
1. Q表打印
for i, agent in enumerate(agents):
print(f"\nAgent {i+1} Q-table:")
for state in range(n_states):
print(f"State {state}: {agent.q_table[state]}")
输出:
Agent 1 Q-table:
State 0: [0.12 0.45]
State 1: [1.23 0.89]
...
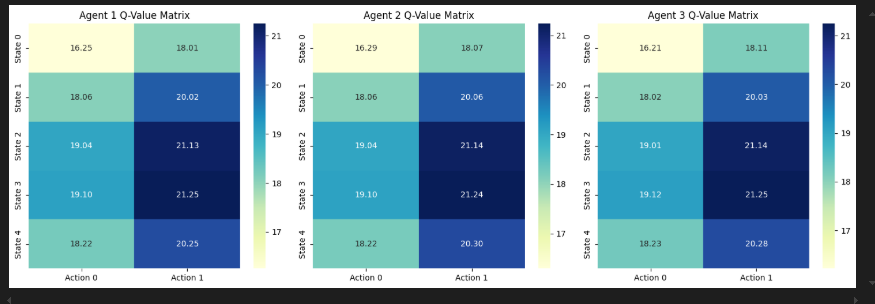
2. Q值矩阵热力图
plt.figure(figsize=(15, 5))
for i, agent in enumerate(agents):
plt.subplot(1, n_agents, i+1)
q_matrix = np.array([agent.q_table[state] for state in range(n_states)]) # 转换为矩阵
sns.heatmap(q_matrix, annot=True, fmt=".2f", cmap="YlGnBu",
xticklabels=[f"Action {a}" for a in range(n_actions)],
yticklabels=[f"State {s}" for s in range(n_states)])
plt.title(f"Agent {i+1} Q-Value Matrix")
- 颜色深浅表示Q值大小
- 数字标注显示具体值
- 每行对应一个状态,每列对应一个动作
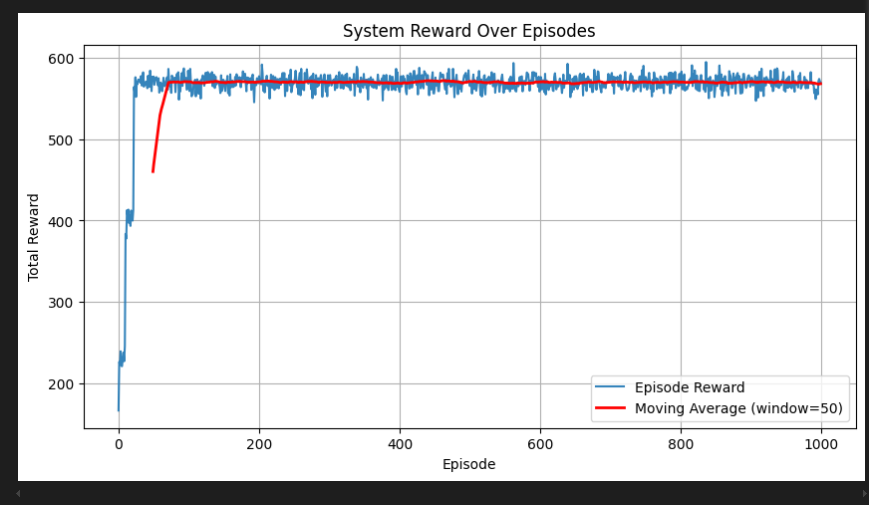
3. 奖励曲线分析
plt.plot(episode_rewards, alpha=0.3) # 原始奖励(半透明)
moving_avg = np.convolve(episode_rewards, np.ones(50)/50, mode='valid') # 滑动平均
plt.plot(np.arange(49, 1000), moving_avg, 'r-', linewidth=2) # 平滑趋势线
- 蓝色曲线:原始奖励(高波动)
- 红色曲线:50轮滑动平均(显示收敛趋势)
四、关键设计思想
- 分布式特性:
- 每个智能体通过
neighbors_q_tables获取其他智能体的Q表 - 更新时参考邻居的最大Q值(
max_neighbor_q)
- 每个智能体通过
- 环境设计:
- 状态空间:离散整数(0-4)
- 动作影响:
next_state = (state + action) % n_states - 奖励函数:
state * action + noise
- 探索-利用平衡:
- ε-greedy策略保证持续探索
- 随训练进行,Q表逐渐收敛到最优策略
这个实现展示了多智能体系统中通过分布式Q学习实现协作决策的完整流程,可视化部分帮助直观理解学习动态。

















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









