







 本文探讨了如何利用LSTM进行目标依赖的情感分类,提出了Target-Dependent LSTM和Target-Connection LSTM模型,强调目标词与上下文的语义关联在情感分析中的重要性。实验表明,通过引入目标连接组件,模型能更好地捕捉情感特征,提高分类准确率。
本文探讨了如何利用LSTM进行目标依赖的情感分类,提出了Target-Dependent LSTM和Target-Connection LSTM模型,强调目标词与上下文的语义关联在情感分析中的重要性。实验表明,通过引入目标连接组件,模型能更好地捕捉情感特征,提高分类准确率。
论文1
Effective LSTMs for Target-Dependent Sentiment Classification(2016)
目录
Effective LSTMs for Target-Dependent Sentiment Classification(2016)
1 方法
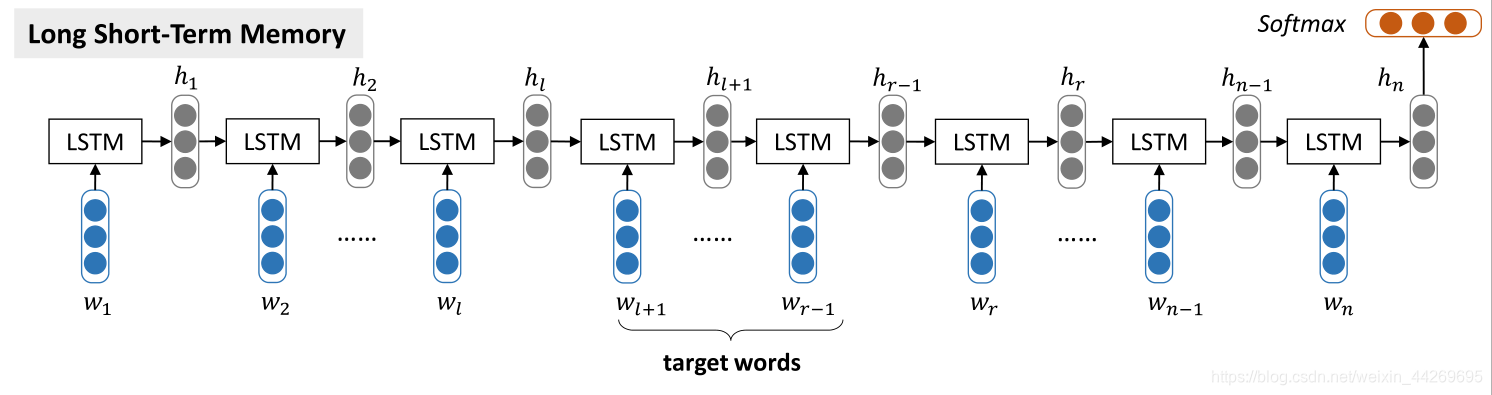
文章目的:有效地建立目标词与其上下文词的语义关联模型。
首先提出了一种基本的长短时记忆(LSTM)方法,建模一个句子的语义表示,而不考虑被评价的目标词。然后,考虑目标词对LSTM进行扩展,得到目标依赖的长短期记忆模型(TD-LSTM)。TD-LSTM是对目标词与其上下文词的相关度进行建模,并选择上下文的相关部分来推断指向目标词的情感极性。该模型采用标准的反向传播方法进行端到端的训练,其损失函数为监督情感分类的交叉熵误差。最后,对目标连接的TD-LSTM进行了扩展,其中目标与上下文词的语义关联被合并。
一个长度为n的句子中,w1,w2,...wn表示每一个词。![]() 表示目标词,
表示目标词,![]() 是上文, {wr, ..., wn−1,wn}是下文, v target是目标表示。
是上文, {wr, ..., wn−1,wn}是下文, v target是目标表示。
1.1 LSTM
![]() ,d是单词向量的维数,|V |是词汇量。用词嵌入算法预先训练词向量。
,d是单词向量的维数,|V |是词汇量。用词嵌入算法预先训练词向量。![]() Wi, bi, Wf, bf, Wo, bo为参数,C是情感类别的数量:3。
Wi, bi, Wf, bf, Wo, bo为参数,C是情感类别的数量:3。
LSTM 方法先将所有变长的句子均表示为一种固定长度的向量,具体做法是将最后一个word对应的计算得到的 hidden vector 作为整句话的表示(sentence vector)。之后,将最后得到的这个 sentence vector 送入一个 linear layer,使其输出为一个维度为情绪种类个数。最后对 linear layer 得出的结果做 softmax 并依次为依据选出该句(同时也是 target)的情绪分类。
![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2839
2839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









