






学习过程
一 模型背景
Transformer是一种由编解码模块构成的神经网络,由Vaswani等人在2017年的论文“Attention Is All You Need”中提出,在机器翻译、语言建模和文本生成等自然语言处理任务中扮演重要角色。Transformer与传统NLP特征提取类模型的区别主要在以下两点:
- Transformer是一个纯基于注意力机制的结构,并将自注意力机制和多头注意力机制的概念运用到模型中;
- 由于缺少RNN模型的时序性,Transformer引入了位置编码,在数据上而非模型中添加位置信息;
以上的处理带来了几个优点:
- 更容易并行化,训练更加高效,使得句子的多步可以同步进行;
- 在处理长序列的任务中表现优秀,得益于位置编码和多头注意力机制可以快速捕捉长距离中的关联信息。
二 模型构建
整体模型由
1.由下列三个元素构成的注意力机制模块
query:任务内容key:索引/标签(帮助定位到答案)value:答案
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor
from mindspore import dtype as mstype
class ScaledDotProductAttention(nn.Cell):
def __init__(self, dropout_p=0.):
super().__init__()
self.softmax = nn.Softmax()
self.dropout = nn.Dropout(p=dropout_p)
self.sqrt = ops.Sqrt()
def construct(self, query, key, value, attn_mask=None):
"""scaled dot product attention"""
embed_size = query.shape[-1]
scaling_factor = self.sqrt(Tensor(embed_size, mstype.float16)) # 910b不支持float32的数据类型,需要将所有float32数据转换为float16,后续相同修改不再标注。
attn = ops.matmul(query, key.swapaxes(-2, -1) / scaling_factor)
if attn_mask is not None:
attn = attn.masked_fill(attn_mask, -1e9)
attn = self.softmax(attn)
attn = self.dropout(attn)
output = ops.matmul(attn, value)
return (output, attn)
主要逻辑,涉及到通过计算key和qury的相似度评估,从而生成注意力占比,将目标聚集到注意力所在的区域,该相似度的区间限制与0到1之间,并令其作用在value上:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
m
o
d
e
l
)
V
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{model}}}\right)V
Attention(Q,K,V)=softmax(dmodelQKT)V
2.位置编码结构
Transformer模型不包含RNN,所以无法在模型中记录时序信息,这样会导致模型无法识别由顺序改变而产生的句子含义的改变,如“我爱我的小猫”和“我的小猫爱我”。
为了弥补这个缺陷,我们选择在输入数据中额外添加表示位置信息的位置编码。
位置编码 P E PE PE的形状与经过word embedding后的输出 X X X相同,对于索引为[pos, 2i]的元素,以及索引为[pos, 2i+1]的元素,位置编码的计算如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE_{(pos,2i)} = \sin\Bigg(\frac{pos}{10000^{2i/d_{\text{model}}}}\Bigg) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE_{(pos,2i+1)} = \cos\Bigg(\frac{pos}{10000^{2i/d_{\text{model}}}}\Bigg) PE(pos,2i+1)=cos(100002i/dmodelpos)
2.1 编码模块
编码模块由输入词嵌入、位置编码完成初步的特征转换和位置信息连接,进而通过输入多头注意力模块聚焦特征,再经过ADD和非线性变化完成一次编码,实际构建中会多次重复这个编码层,因为主要机制为多头注意力模块,因而被称为基于注意力机制
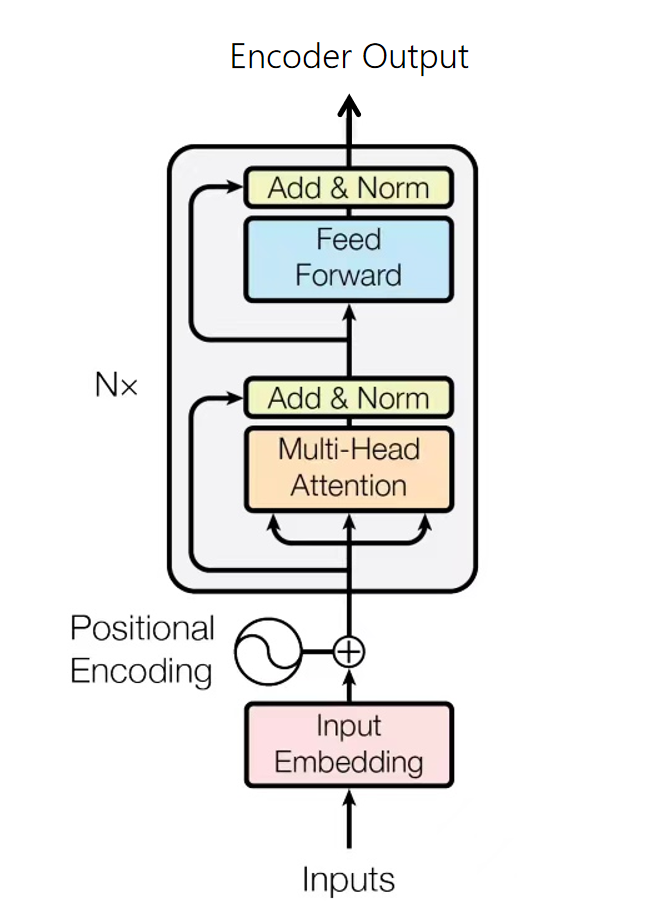
class EncoderLayer(nn.Cell):
def __init__(self, d_model, n_heads, d_ff, dropout_p=0.):
super().__init__()
d_k = d_model // n_heads
if d_k * n_heads != d_model:
raise ValueError(f"The `d_model` {d_model} can not be divisible by `num_heads` {n_heads}.")
self.enc_self_attn = MultiHeadAttention(d_model, d_k, n_heads, dropout_p)
self.pos_ffn = PoswiseFeedForward(d_ff, d_model, dropout_p)
self.add_norm1 = AddNorm(d_model, dropout_p)
self.add_norm2 = AddNorm(d_model, dropout_p)
def construct(self, enc_inputs, enc_self_attn_mask):
"""
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
"""
residual = enc_inputs
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
enc_outputs = self.add_norm1(enc_outputs, residual)
residual = enc_outputs
enc_outputs = self.pos_ffn(enc_outputs)
enc_outputs = self.add_norm2(enc_outputs, residual)
return enc_outputs, attn
2.2 解码模块
解码部分的输入由两部分组成,前一部分编码结构的输出和目标句子的前n-1个序列,模型同样通过相似流程后,预测下一个单词。
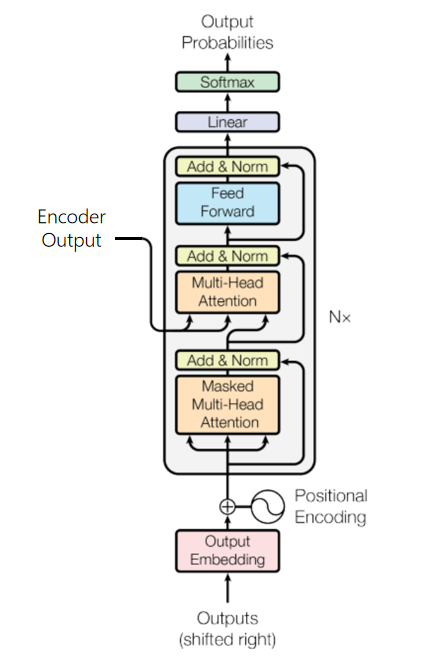
class DecoderLayer(nn.Cell):
def __init__(self, d_model, n_heads, d_ff, dropout_p=0.):
super().__init__()
d_k = d_model // n_heads
if d_k * n_heads != d_model:
raise ValueError(f"The `d_model` {d_model} can not be divisible by `num_heads` {n_heads}.")
self.dec_self_attn = MultiHeadAttention(d_model, d_k, n_heads, dropout_p)
self.dec_enc_attn = MultiHeadAttention(d_model, d_k, n_heads, dropout_p)
self.pos_ffn = PoswiseFeedForward(d_ff, d_model, dropout_p)
self.add_norm1 = AddNorm(d_model, dropout_p)
self.add_norm2 = AddNorm(d_model, dropout_p)
self.add_norm3 = AddNorm(d_model, dropout_p)
def construct(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
dec_inputs: [batch_size, trg_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, trg_len, trg_len]
dec_enc_attn_mask: [batch_size, trg_len, src_len]
"""
residual = dec_inputs
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs = self.add_norm1(dec_outputs, residual)
residual = dec_outputs
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.add_norm2(dec_outputs, residual)
residual = dec_outputs
dec_outputs = self.pos_ffn(dec_outputs)
dec_outputs = self.add_norm3(dec_outputs, residual)
return dec_outputs, dec_self_attn, dec_enc_attn
三 数据处理
实验中使用的数据集为Multi30K数据集,它是一个大规模的图像-文本数据集,包含30K+图片,每张图片对应两类不同的文本描述:
- 英语描述,及对应的德语翻译;
- 五个独立的、非翻译而来的英语和德语描述,描述中包含的细节并不相同;
- 因其收集的不同语言对于图片的描述相互独立,所以训练出的模型可以更好地适用于有噪声的多模态内容,在这次实验中,其提取德语和英语文本作为实验数据,主要流程包括:
1.单词提取
2.单词频数计算
3.构建单词字典
4.生成词典index
注意其中的语句通过占位符实现序列等长,以及插入开始和结束符号
四 模型训练与评估
模型训练中为了保证在t时刻,只有t-1个词元作为输入参与多头注意力分数的计算,我们需要在第一个多头注意力中额外增加一个时间掩码,使目标序列中的词随时间发展逐个被暴露出来。该注意力掩码通过三角矩阵实现,对角线以上的词元表示为不参与注意力计算的词元,标记为1。
0
1
1
1
1
0
0
1
1
1
0
0
0
1
1
0
0
0
0
1
0
0
0
0
0
\begin{matrix} 0 & 1 & 1 & 1 & 1\\ 0 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 1\\ 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0\\ \end{matrix}
0000010000110001110011110
通过这种设计使得能够实现在时间序列上的批量
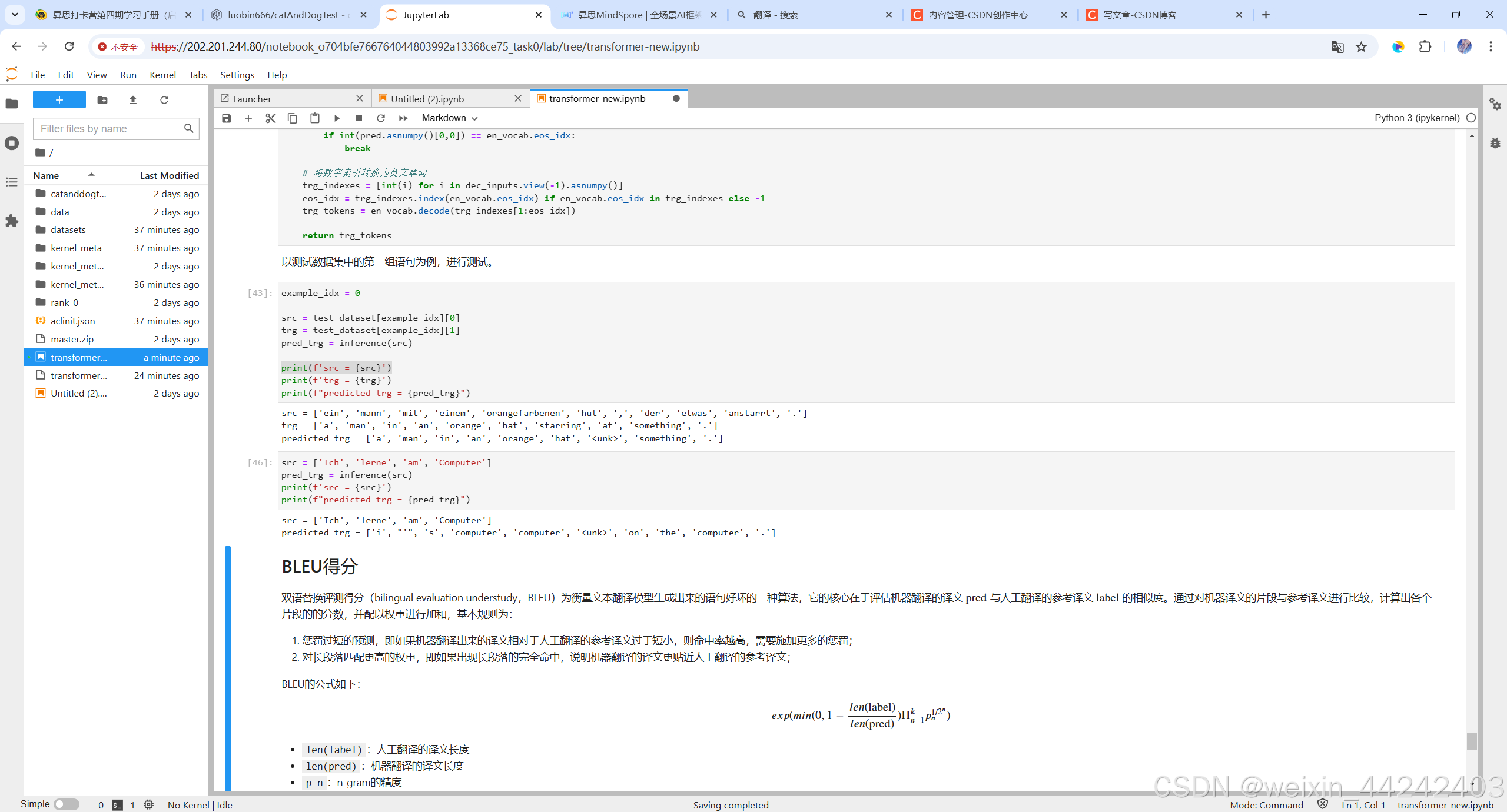
模型翻译测试
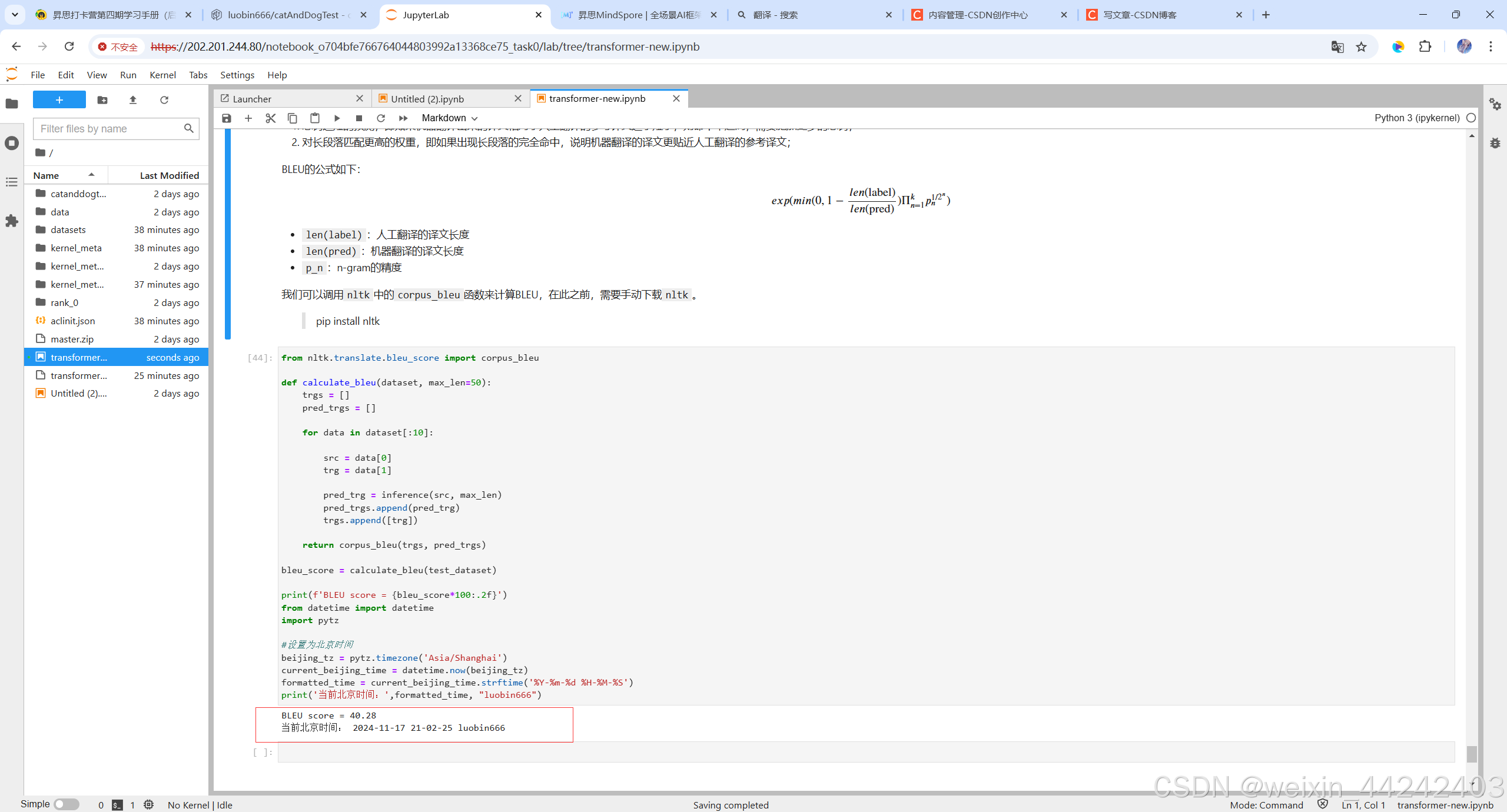
2.模型评估测试
心得体会
第一次完整地学习了transfomer,并在mindspore框架上进行了代码学习实现,代码注释流程很清晰,尤其是逐步解析多头注意力机构的实现,能够将数学原理和代码实践结合,尤其是其中时间序列掩码get_attn_subsequent_mask 函数生成的后续掩码(subsequent mask),确保在解码阶段,模型只能关注到当前位置之前的输出,而不能“看到”未来的输出。
在自回归解码过程中,模型需要逐步生成序列,并且在生成某个位置的输出时,只能依赖已经生成的序列部分。然而,在训练过程中,通常使用“教师强制”策略,即使用真实的标签序列(而非模型之前生成的输出)作为解码器的输入,以加速训练和提高稳定性,但后续掩码仍然需要,以确保模型在生成每个输出时不会“作弊”看到未来的信息,因此该部分被嵌入模型解码阶段使用,从而实现并行训练,总的来说学习还比较浅,后续会进一步学习。
[1]学习文档


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









