






1.数据准备
本次学习尝试将常见的猫狗分类的pytorch代码通过MindTorch进行迁移,总体迁移过程非常简单,基本函数支持很全面,首先对猫狗数据进行下载,并在openi启智平台创建项目,包括数据上传,模型迁移,数据训练,数据测试评估:
创建项目后,在数据集页面进行数据上传,需要注意这里大文件(超过500MB),需要通过SDK进行上传:
pip install -U openi -i https://pypi.tuna.tsinghua.edu.cn/simple
openi dataset upload OpenIOSSG/OpenI_Cloudbrain_Example d:/example/MnistDataset_mindspore.zip
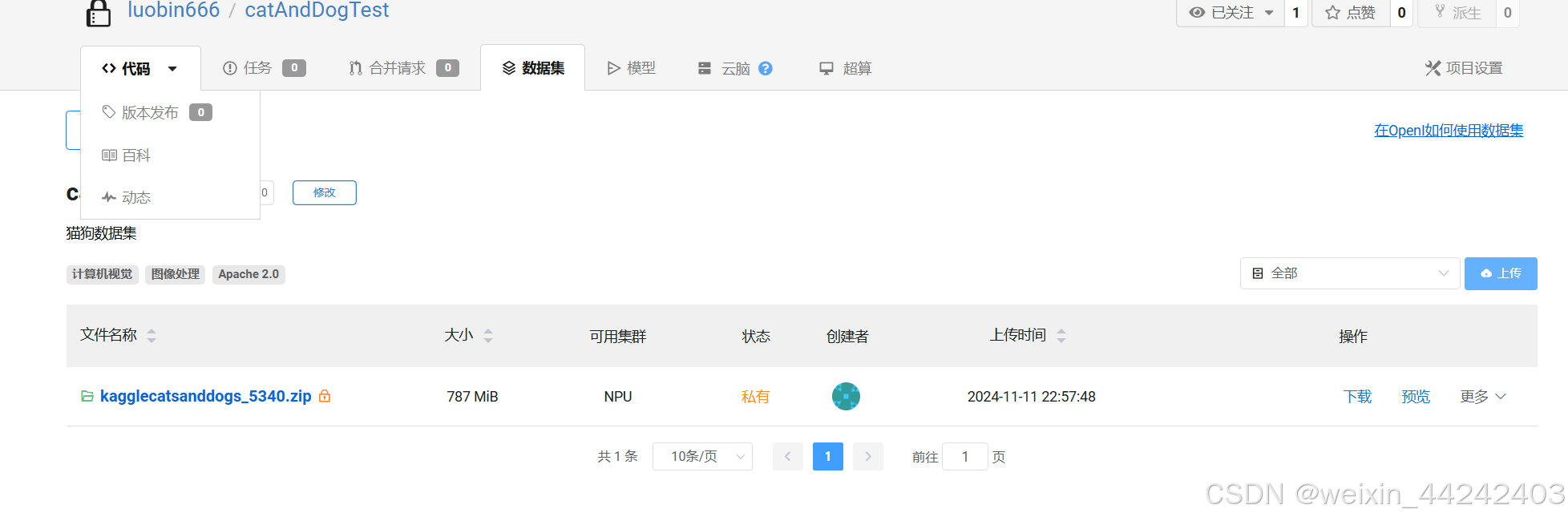
上传成功之后,可以在jupyter中直接使用
# 导入包
from c2net.context import prepare
# 初始化导入数据集和预训练模型到容器内
open_context = prepare()
# 获取数据集路径
dataset_path = open_context.dataset_path + "/"+ "kagglecatsanddogs_5340"
print(dataset_path)
2.环境构建
由于此次实验是选择MindTorch进行代码迁移,建议选择交互式环境,然后镜像默认调用mindspare和MindTorch配置好的环境,如果是自己手动配置环境需要设置环境变量,否则会报错

export GLOG_v=2
# Conda environmental options
LOCAL_ASCEND=/usr/local/Ascend # the root directory of run package
# lib libraries that the run package depends on
export LD_LIBRARY_PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/lib64:${LOCAL_ASCEND}/driver/lib64:${LOCAL_ASCEND}/ascend-toolkit/latest/opp/built-in/op_impl/ai_core/tbe/op_tiling:${LD_LIBRARY_PATH}
# Environment variables that must be configured
## TBE operator implementation tool path
export TBE_IMPL_PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/opp/built-in/op_impl/ai_core/tbe
## OPP path
export ASCEND_OPP_PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/opp
## AICPU path
export ASCEND_AICPU_PATH=${ASCEND_OPP_PATH}/..
## TBE operator compilation tool path
export PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/compiler/ccec_compiler/bin/:${PATH}
## Python library that TBE implementation depends on
export PYTHONPATH=${TBE_IMPL_PATH}:${PYTHONPATH}
3.代码迁移
代码迁移目标选择https://zhuanlan.zhihu.com/p/388676784知乎好心人提供的简要代码,整体迁移工作几乎没有,主要迁移点在两个地方:
1.包名进行替换,需要注意要偷懒直接只修改import mindtorch.torch as torch,会出现错误引用
import mindtorch.torch as torch
import mindtorch.torch.optim as optim
import mindtorch.torch as torch
import mindtorch.torch.nn as nn
import mindtorch.torch.nn.functional as F
from mindtorch.torchvision import datasets, transforms
#pytorch代码
from torchvision import transforms,datasets
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
2.去除to(Divce)函数,ascend默认调用后台GPU计算,不需要进行指定,当然也可以在环境变量中设定目标驱动
for idx,(t_data,t_target) in enumerate(train_loader):
t_data,t_target=t_data,t_target
pred=model(t_data)#batch_size*2
loss=F.nll_loss(pred,t_target)
#torch
for idx,(t_data,t_target) in enumerate(train_loader):
t_data,t_target=t_data.to(device),t_target.to(device)
pred=model(t_data)#batch_size*2
loss=F.nll_loss(pred,t_target)
4.模型训练
模型训练与pytoch可以通过设置环境变量实现,一键支持backward计算,也可以替换为MIndSpore的写法,这里采用最简单的一键替换
os.environ['ENABLE_BACKWARD']="1"
完整代码如下:
# 导入包
from c2net.context import prepare
# 初始化导入数据集和预训练模型到容器内
open_context = prepare()
# 获取数据集路径
dataset_path = open_context.dataset_path + "/"+ "kagglecatsanddogs_5340"
print(dataset_path)
import os,shutil
def mymovefile(srcfile,dstfile):
if not os.path.isfile(srcfile):
print("src not exist!")
else:
fpath,fname=os.path.split(dstfile) #分离文件名和路径
if not os.path.exists(fpath):
os.makedirs(fpath) #创建路径
shutil.copy(srcfile,dstfile) #移动文件
test_rate=0.2#训练集和测试集的比例为8:2。
img_num=12500
test_num=int(img_num*test_rate)
import random
test_index = random.sample(range(0, img_num), test_num)
train_idex = [i for i in range(0, img_num) if i not in test_index]
file_path=dataset_path+'/PetImages'
save_path = r'data'
tr="train"
te="test"
cat="Cat"
dog="Dog"
#将上述index中的文件都移动到/test/Cat/和/test/Dog/下面去。
for i in range(len(test_index)):
#移动猫
srcfile=os.path.join(file_path,cat,str(test_index[i])+".jpg")
dstfile=os.path.join(save_path,te,cat,str(test_index[i])+".jpg")
mymovefile(srcfile,dstfile)
#移动狗
srcfile=os.path.join(file_path,dog,str(test_index[i])+".jpg")
dstfile=os.path.join(save_path,te,dog,str(test_index[i])+".jpg")
mymovefile(srcfile,dstfile)
for i in range(len(train_idex)):
#移动猫
srcfile=os.path.join(file_path,cat,str(train_idex[i])+".jpg")
dstfile=os.path.join(save_path,tr,cat,str(train_idex[i])+".jpg")
mymovefile(srcfile,dstfile)
#移动狗
srcfile=os.path.join(file_path,dog,str(train_idex[i])+".jpg")
dstfile=os.path.join(save_path,tr,dog,str(train_idex[i])+".jpg")
mymovefile(srcfile,dstfile)
import numpy as np
#from torchvision import transforms,datasets
# from mindtorch.torch.utils.data import DataLoader
from mindtorch.torch.utils.data import DataLoader
from mindtorch.torchvision import datasets, transforms
import os
#定义transforms
transform = transforms.Compose([
transforms.RandomResizedCrop(150),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
]
)
train_data = datasets.ImageFolder(os.path.join(save_path,tr), transform)
test_data=datasets.ImageFolder(os.path.join(save_path,te), transform)
#删除cat 666
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True,pin_memory=True)
test_loader = DataLoader(test_data,batch_size=batch_size)
#模型构建
batch_size=256
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True,pin_memory=True)
test_loader = DataLoader(test_data,batch_size=batch_size)
import mindtorch.torch as torch
import mindtorch.torch.optim as optim
import mindtorch.torch as torch
import mindtorch.torch.nn as nn
import mindtorch.torch.nn.functional as F
from mindtorch.torchvision import datasets, transforms
#架构会有很大的不同,因为28*28-》150*150,变化挺大的,这个步长应该快一点。
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1=nn.Conv2d(3,20,5,5)#和MNIST不一样的地方,channel要改成3,步长我这里加快了,不然层数太多。
self.conv2=nn.Conv2d(20,50,4,1)
self.fc1=nn.Linear(50*6*6,200)
self.fc2=nn.Linear(200,2)#这个也不一样,因为是2分类问题。
def forward(self,x):
#x是一个batch_size的数据
#x:3*150*150
x=F.relu(self.conv1(x))
#20*30*30
x=F.max_pool2d(x,2,2)
#20*15*15
x=F.relu(self.conv2(x))
#50*12*12
x=F.max_pool2d(x,2,2)
#50*6*6
x=x.view(-1,50*6*6)
#压扁成了行向量,(1,50*6*6)
x=F.relu(self.fc1(x))
#(1,200)
x=self.fc2(x)
#(1,2)
return F.log_softmax(x,dim=1)
model=CNN()
optimizer=optim.Adam(model.parameters(),lr=lr)
def train(model,train_loader,optimizer,epoch,losses):
model.train()
for idx,(t_data,t_target) in enumerate(train_loader):
#t_data,t_target=t_data,t_target
pred=model(t_data)#batch_size*2
#loss=F.nll_loss(pred,t_target)
def forward_fn(images, target):
output = model(images)
loss = F.nll_loss(output, target)
return loss, output
grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
def train_step(data, label):
(loss, output), grads = grad_fn(data, label)
optimizer(grads)
return torch.cast_to_adapter_tensor(loss), torch.cast_to_adapter_tensor(output)
#Adam
#optimizer.zero_grad()
loss, output = train_step(t_data, t_target)
# loss.backward()
# optimizer.step()
if idx%10==0:
print("epoch:{},iteration:{},loss:{}".format(epoch,idx,loss.item()))
losses.append(loss.item())
num_epochs=5
losses=[]
from time import *
begin_time=time()
for epoch in range(num_epochs):
train(model, train_loader, optimizer, epoch,losses)
# test(model,device,test_loader)
end_time=time()
训练总结
这次迁移工作很快就结束了,总体而言未发现很大问题,后续可以尝试将更复杂的模型进行迁移测试,可能最大的问题还是mind平台环境的构建吧

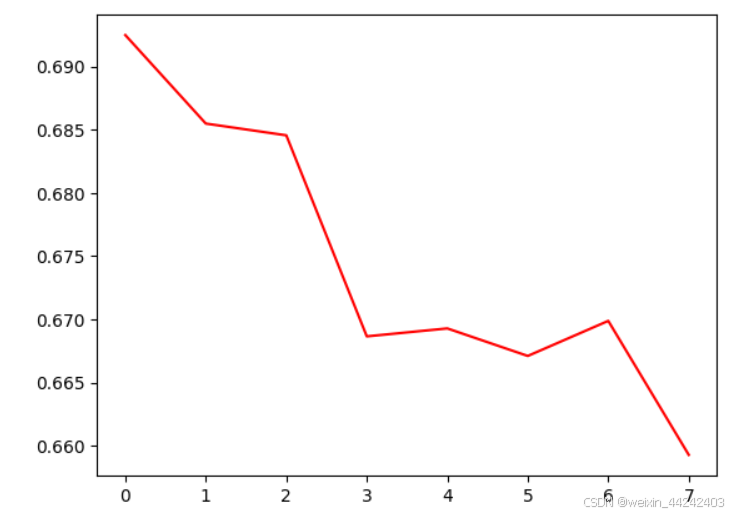
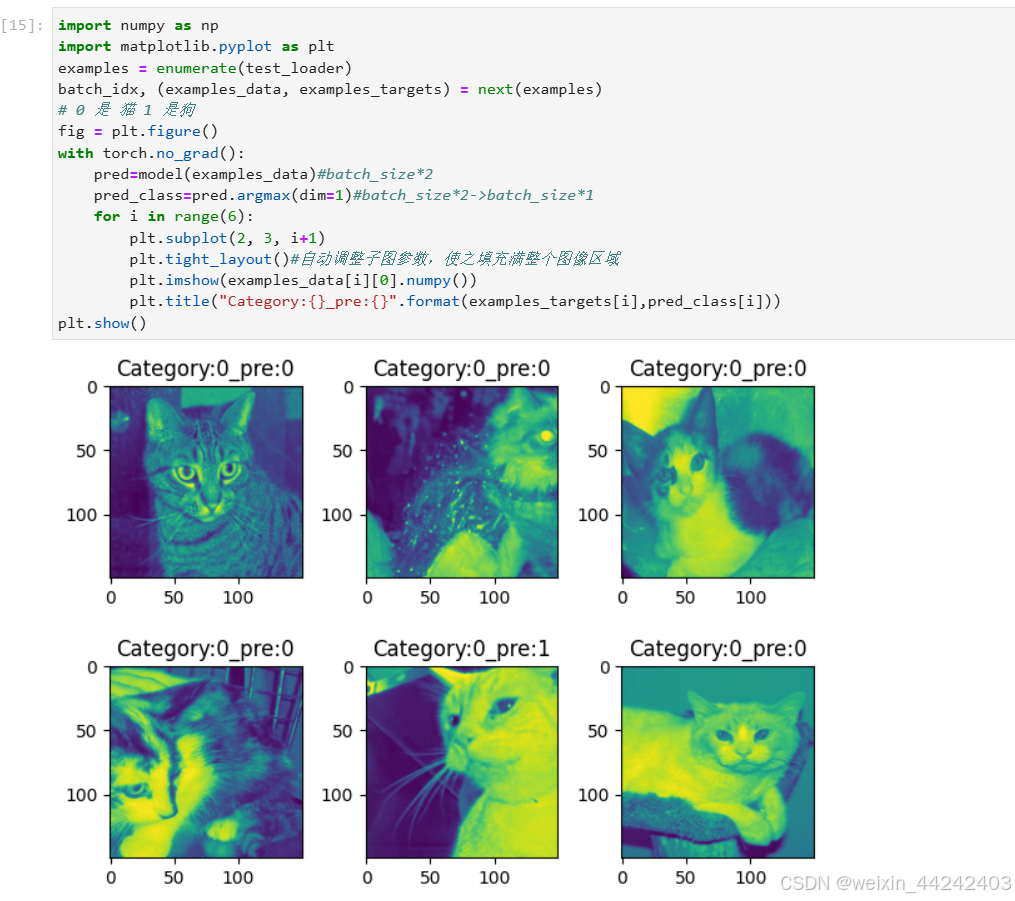
虽然此次测试训练的批次不足,但是还是算一个完整的测试案例,还是很有收获的,Openi的平台各方面使用也很便捷,最后上一波预测的评估图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









