







基于MindSpore的BERT模型的情感分析
一 Bert模型原理
语言模型的发展:
①word2vec/Glove将离散的文本数据转换为固定长度的静态词向量,然后根据下游任务训练不同的语言模型
②ELMo预训练模型将文本数据结合上下文信息,转换为动态词向量,根据下游任务训练不同的语言模型
③BERT同样将文本数据转换为动态词向量,能够更好地捕捉句子级别的信息与语境信息,后续只需对BERT参数进行微调,仅重新训练最后的输出层即可适配下游任务
④GPT等预训练语言模型主要用于文本生成类任务,需要通过prompt方法来应用于下游任务,指导模型生成特定的输出。
1.1 模型整体流程
第一步:Tokenization,输入的句子经过分词后,首尾添加[CLS]与[SEP]特殊字符,后转换为数字id
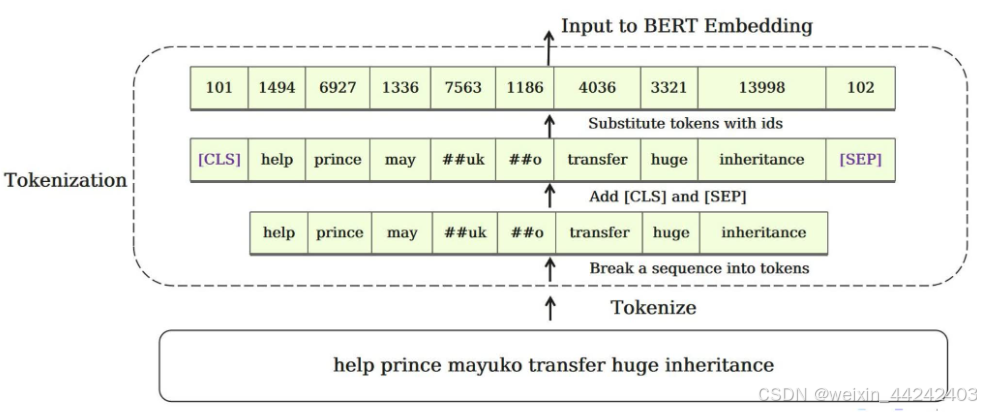
第二步:Embedding,输入到BERT模型的信息由三部分内容组成:
表示内容的 tokenids
表示位置的positionids
用于区分不同句子的tokentypeids
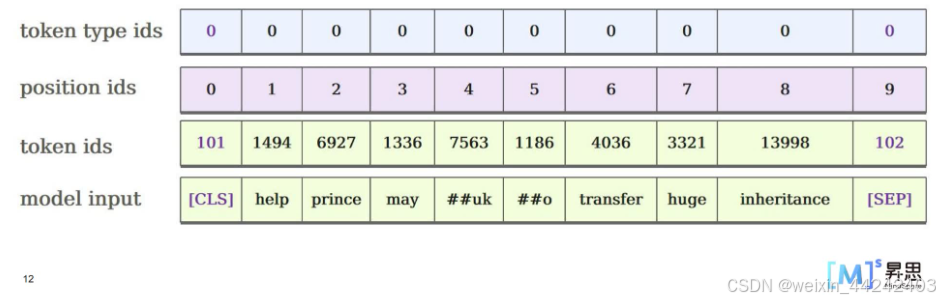
第三步:将三种信息分别输入Embedding层
第四步:BERT会针对每一个位置输出大小为hidden size的向量,在下游任务中,会根据任务内容的不同,选取不同的向量放入输出层
模型结构:
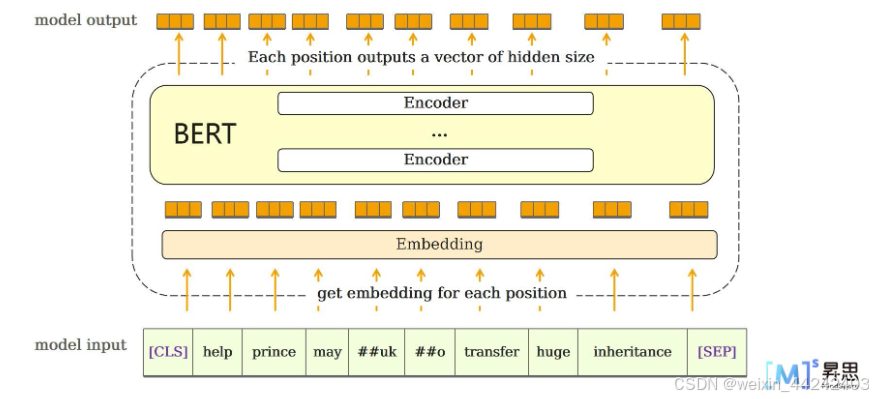
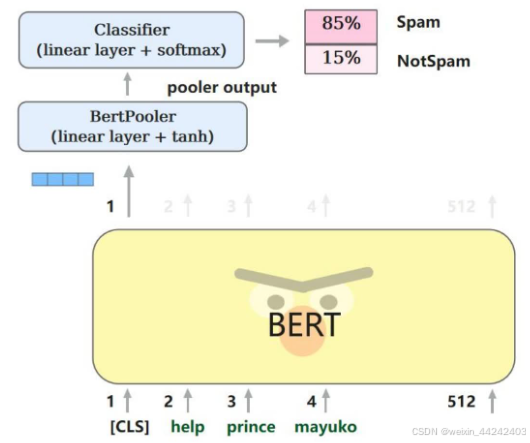
本次学习中,主要通过预训练模型,实现语句情感分析,只需要取输出部分CLS对应的特征进行全连接计算推断类别即可。
二 模型构建
模型构建无需,人工构建,直接通过mindnlp框架中内置的Transfomer中实现的BERT模型进行使用即可:
from mindnlp.transformers import BertForSequenceClassification
# set bert config and define parameters for training
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
三 模型数据
模型所用数据来自百度飞浆,由两列组成,以制表符(‘\t’)分隔,第一列是情绪分类的类别(0表示消极;1表示中性;2表示积极),第二列是以空格分词的中文文本,如下示例,文件为 utf8 编码。
0–谁骂人了?我从来不骂人,我骂的都不是人,你是人吗 ?
数据操作流程包括:数据集读取,数据格式转换,数据 Tokenize 处理和 pad 操作。
import os
import mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn, context
from mindnlp.engine import Trainer
# prepare dataset
class SentimentDataset:
"""Sentiment Dataset"""
def __init__(self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









