







1.One-Hot 编码
# 导入用于对象保存和加载的包
from sklearn.externals import joblib
# 导入keras中的词汇映射器Tokenizer
from keras.preprocessing.text import Tokenizer
# 初始化一个词汇表
vocab = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# 实例化一个词汇映射器
t = Tokenizer(num_words=None, char_level=False)
# 在映射器上拟合现有的词汇表
t.fit_on_texts(vocab)
# 循环遍历词汇表, 将每一个单词映射为one-hot张量表示
for token in vocab:
# 初始化一个全零向量
zero_list = [0] * len(vocab)
# 使用映射器转化文本数据, 每个词汇对应从1开始
token_index = t.texts_to_sequences([token])[0][0] - 1
# 将对应的位置赋值为1
zero_list[token_index] = 1
print(token, "的one-hot编码为:", zero_list)
# 将拟合好的词汇映射器保存起来
tokenizer_path = "./Tokenizer"
joblib.dump(t, tokenizer_path)

使用one-hot
# 导入用于对象保存于加载的包
from sklearn.externals import joblib
# 将之前已经训练好的词汇映射器加载进来
t = joblib.load("./Tokenizer")
token = "李宗盛"
# 从词汇映射器中得到李宗盛的index
token_index = t.texts_to_sequences([token])[0][0] - 1
# 初始化一个全零的向量
zero_list = [0] * 6
zero_list[token_index] = 1
print(token, "的one-hot编码为:", zero_list)
2.word2vec:

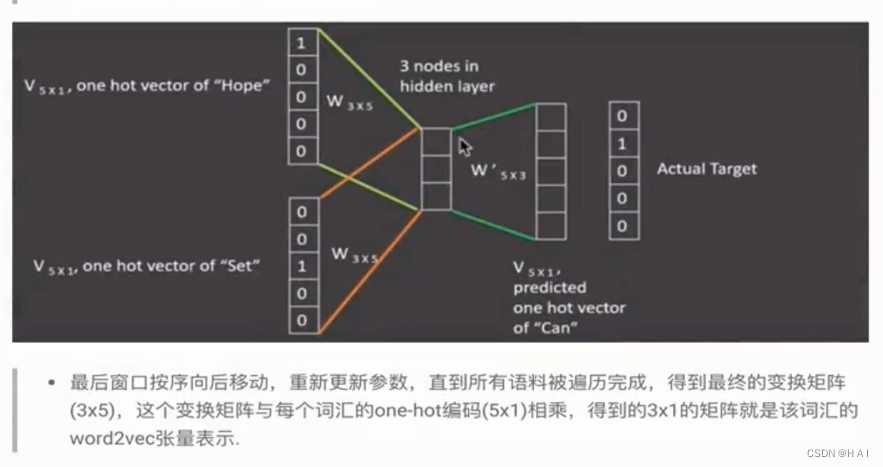
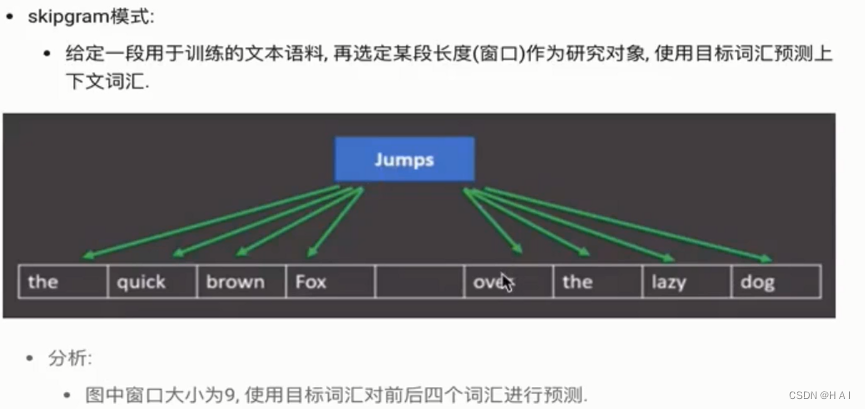
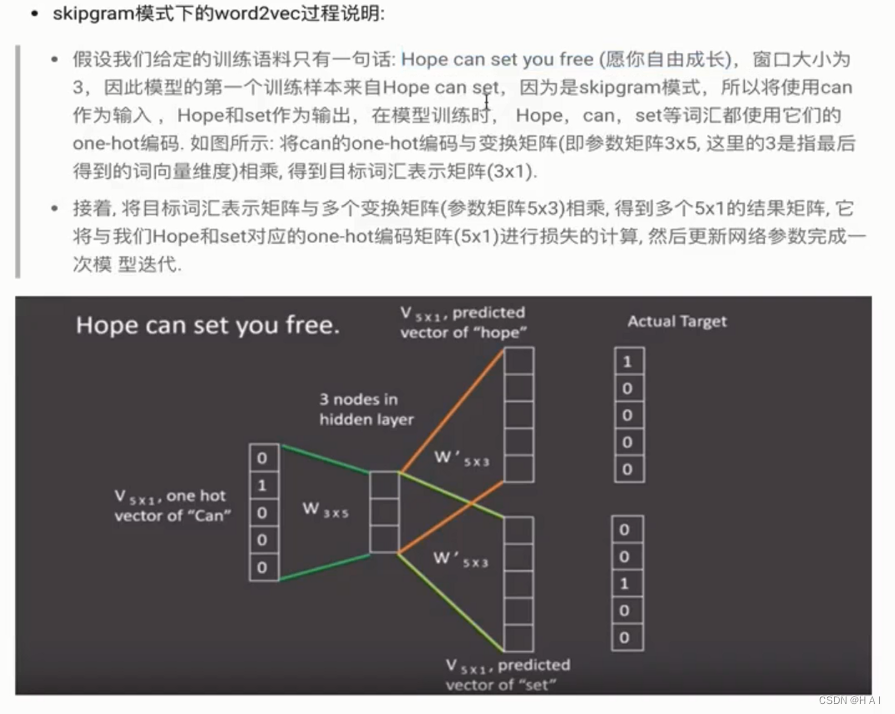
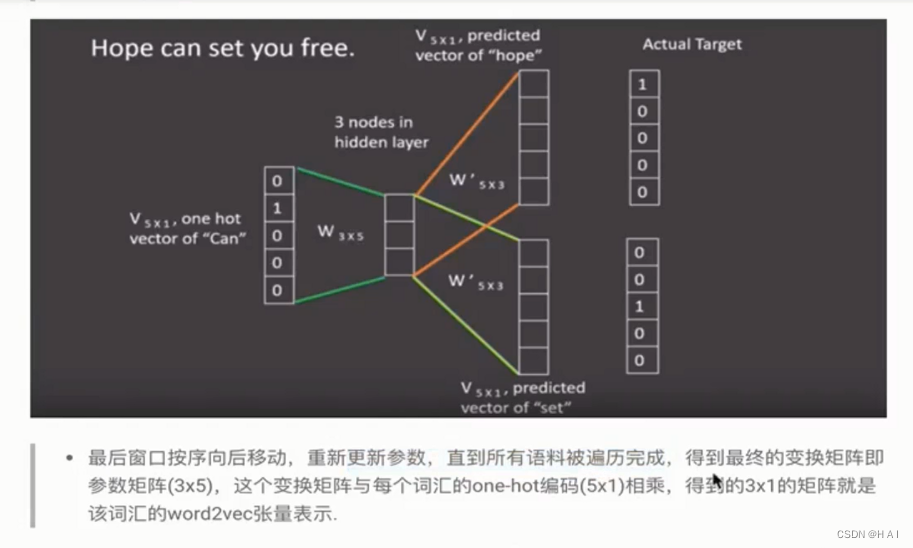
word embedding

# 导入torch和tensorboard导入进来
import torch
import json
import fileinput
from torch.utils.tensorboard import SummaryWriter
# 实例化一个写入对象
writer = SummaryWriter()
# 随机初始化一个100*5的矩阵, 将其视作已经得到的词嵌入矩阵
embedded = torch.randn(100, 50)
# 导入事先准备好的100个中文词汇文件, 形成meta列表原始词汇
meta = list(map(lambda x: x.strip(), fileinput.FileInput("./vocab100.csv")))
writer.add_embedding(embedded, metadata=meta)
writer.close()
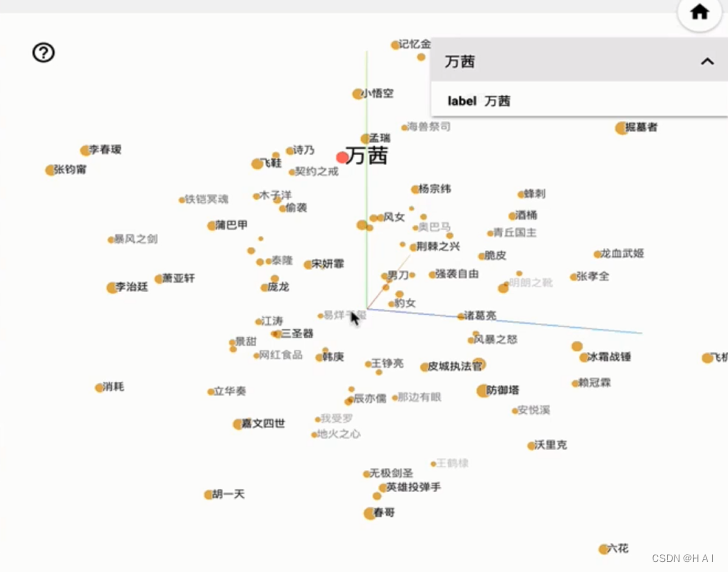
tensorbord可视化embedding 结果

















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









