









写在前面
这同样是一个使用GAN生成CTA图像的工作。与之前分享的一篇工作CTA-GAN不同的是,该工作聚焦于颅底小血管,理论上来说更加困难。论文发表在IEEE Access。
代码地址:https://github.com/Flora-huay/VesselTranGAN
主要贡献:
- 设计了GAN架构的生成网络,可根据颅底NCCT生成对应的CTA影像,分为了2D和3D两个版本;
- 提出了一种融合2D-3D生成数据的策略,改善了生成图像的视觉效果(但文中没有做对应的消融实验,也没有展示不采用融合策略的生成结果)。
一、数据及预处理
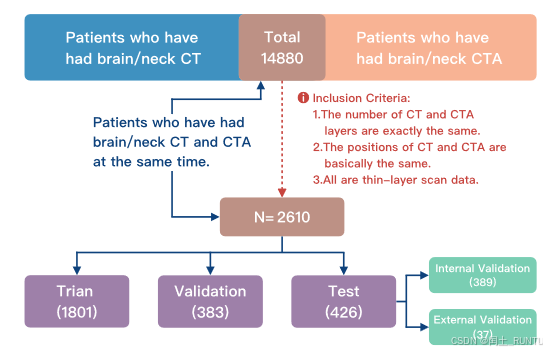
收集了14880例数据,根据纳入标准只纳入了2610例,数据构成:
- 训练集:1801
- 验证集:383
- 测试集:426(进一步分为内部验证389例和外部验证37例)
PS:CT和CTA数据需要精确对齐,并重采样到了0.537mm×0.537mm×0.625mm;文中还提到为保证模型的泛化性,数据集还涉及了多种脑血管疾病,例如颅内动脉瘤、脑动脉粥样硬化、动脉夹层等。但是在诊断性评估中只涉及了动脉瘤和动脉夹层两类疾病的诊断性能。
二、评价指标
1. 定量指标
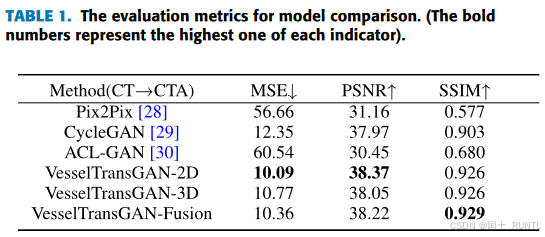
对比了Pix2Pix、CycleGAN和ACL-GAN3种方法,评价指标有MSE、PSNR和SSIM,对比结果如下图所示:
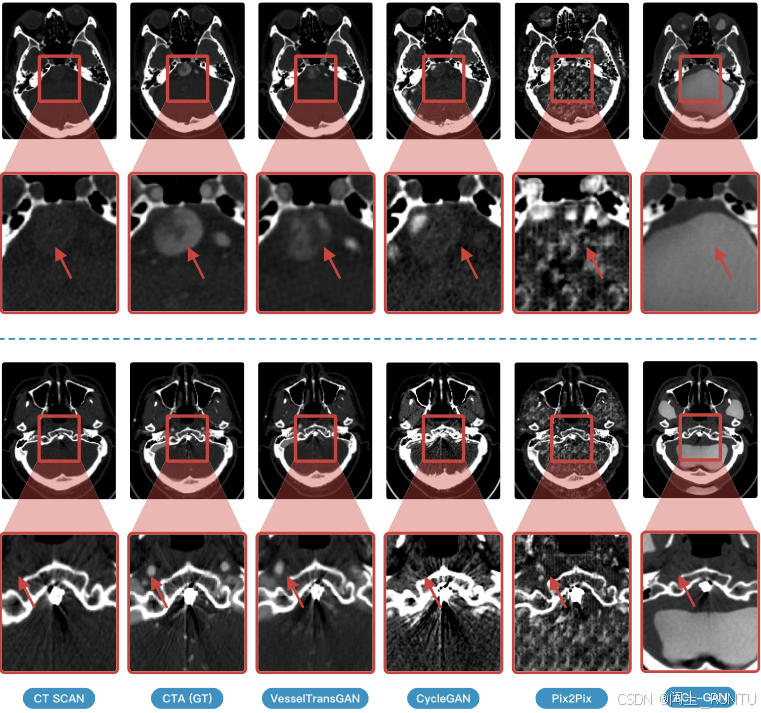
各个方法生成结果对比如下:
2. 定性指标(人类评估)
评估了200个病人的CTA影像,其中100例是模型生成的,另外 100例是真实CTA。两种数据混合后由两名放射医师独立进行打分。具体评估的方面包括血管壁清晰度、血管连续性、血管边界、小血管清晰度、颅内软组织和伪影等。打分1~3,分数越高表示图像质量越高。100例生成CTA的评估结果如下图所示:

3. 诊断评估
两名放射医师根据真实CTA影像诊断颅内动脉瘤、脑动脉硬化和动脉夹层,并将其作为金标准。
为公平起见,由另外两名高级放射医师,排除100例生成CTA中质量较差的10%的数据,对剩余数据进行诊断,统计了颅内动脉瘤和脑动脉硬化两种疾病的诊断结果,如下图所示:
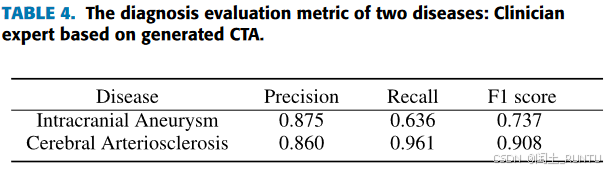
PS:文中并未提及各疾病类别的样本数量。
三、方法
1. VesselTransGAN模型架构
文中提出了2D和3D两个子模型,最终通过提出一种2D-3D融合策略,融合两个模型的输出作为最终的生成结果。模型结构如下图所示:
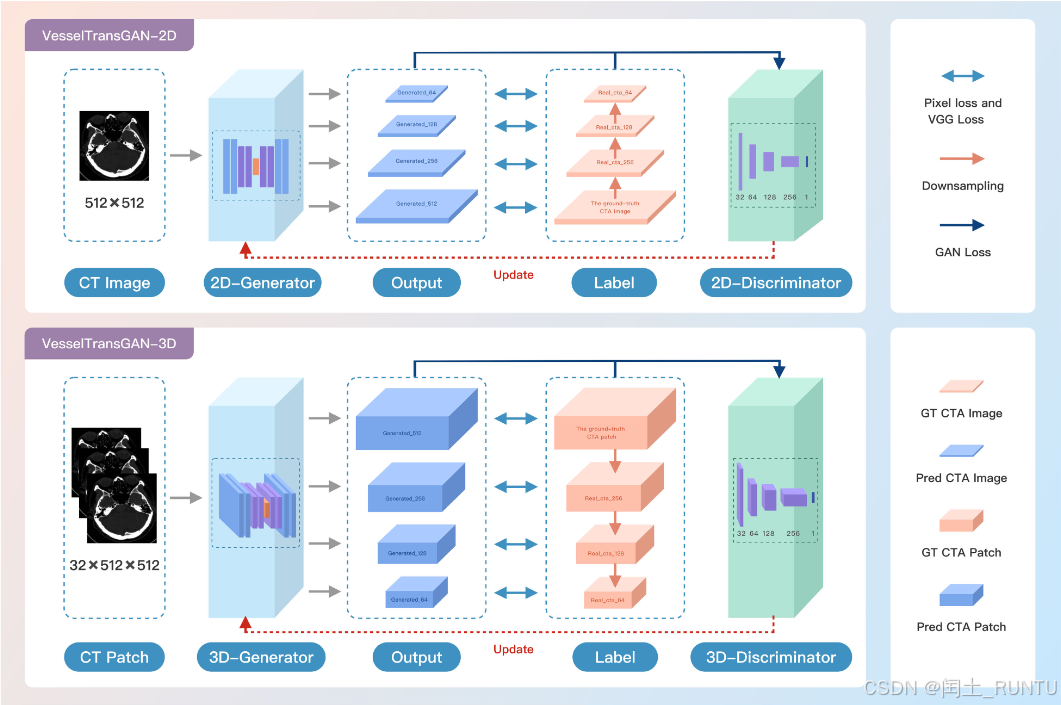
由图可知,2D模型和3D模型均可输出4个不同分辨率的生成图像,而真实CTA也可通过下采样提供不同分辨率的label,用于计算GAN Loss。文中提到生成器decoder部分最后4个子模块有一个额外的ToRGB layer,用于生成不同分辨率的CTAT图像。其他细节没啥可说的。
ToRGB layer这玩意是个啥我不知道~,等以后了解了再来补充。
2. 2D-3D融合策略
(1)整体工作流理解
文中提出了2D和3D两个版本的网络,生成结果也有2D和3D两种形式。
按照文中的说法,2D模型是单层输入,单层输出,图像细节更好,但层与层之间的连续性差,而3D数据特点刚好相反。因此为了兼得鱼和熊掌,需要一种融合策略将二者融合。
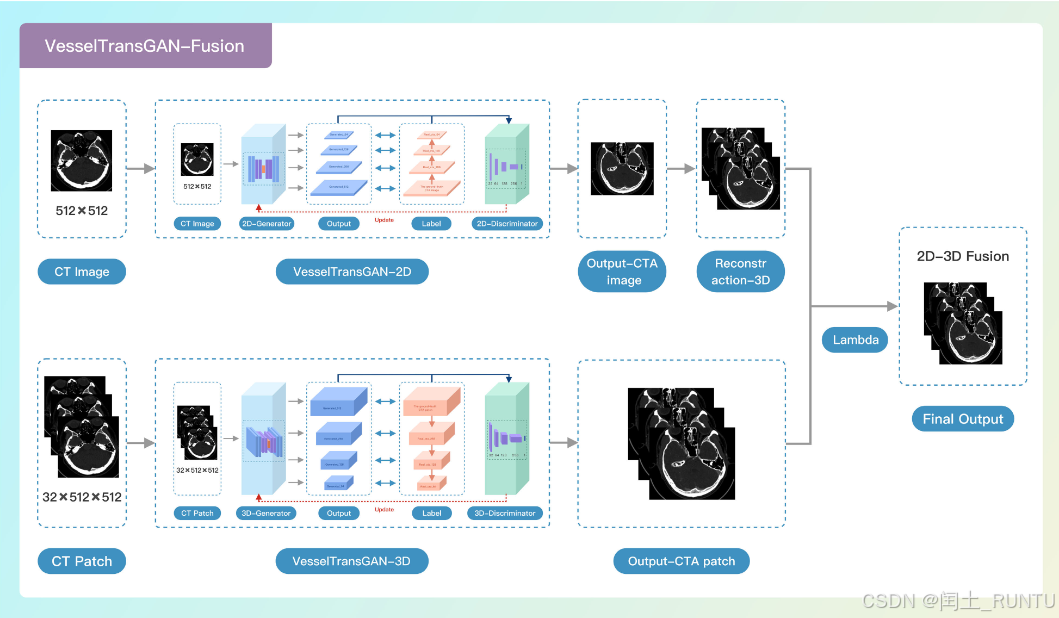
上图是整体的工作流,分别由2D网络和3D网络得到结果,经过融合后得到最终结果。
举个例子:例如一个NCCT体数据共有32层,每层尺寸为512×512;2D网络单张输入,单张输出,最终得到32张独立的生成结果;3D网络则是将32张数据同时输入,然后一起输出32层数据的生成结果,最后再通过文中提出的融合策略将两者融合。
(2)2D-3D融合策略
融合策略总体上的思路是把图像(2D生成结果和3D生成结果)看作低频和高频两部分(文中表述为base和detail),然后确定两者的权重(如何确定权重的?这部分没太理解~),分别得到融合结果的base部分和detail部分,然后再将base和detail加权求和得到最终融合结果。
文中结合公式对提出的策略进行说明,因此在讲解融合策略详细步骤之前,先介绍文中的符号表示:
- 2D网络生成结果:
- 3D网络生成结果:
和
的维度均为
,分别表示CTA切片的高、宽,以及生成数据的层数。
- 2D结果中的一层数据:
- 3D结果中的一层数据:
和
的维度为
。
第一步:在和
应用box filter
我理解就是滑动平均,确定一个滑动窗口,可以是3×3,也可以是5×5,文中没有具体说明。表示滑动窗口的边长。滑动平均过程建模为如下公式:
和
就是滑动平均的结果,只保留了低频信息,称为base images。
第二步:获得细节图像(detail image)
用原图减去base image,公式如下,很好理解:
第三步:应用拉普拉斯滤波获取高频信息(high-frequency)
第四步:对高频信息进行高斯滤波,平滑噪声
PS:后续步骤并没有用到上述结果,不理解~
第五步:通过比较两张图像在每个像素位置的像素值大小来确定权重矩阵(weight map)
接下来论文表述如下:

此处应该是采用了导向滤波的相关技术,文中提到的guide images我个人理解应该是base image和detail image。产生4个引导滤波器,分别用于之前得到的和
上,得到4个输出结果,其中
和
是基础分量权重,
和
是细节分量权重。
最终结果的基础分量和细节分量计算公式如下:
第六步:基于归一化权重,对BASE和DETAIL执行加权求和得到最终的融合图像。
PS:文中没有给出归一化权重的相关信息,但在流程图上有一个Lambda系数,可能是这个。
四、不足和展望
1. 现有工作的不足
- 生成图像血管连续性不是很好,可能导致血管闭塞等情况的漏诊;
- 模型性能受训练时间、计算资源以及数据数量和质量的影响;
- 尽管生成数据表现出高度保真,但仍然达不到临床使用所需的严格要求。
2. 未来研究方向
- 尝试在更早阶段进行融合,而不是最后融合;
- 重点关注小血管的生成;
- 优化网络架构,研究新的loss,更好捕获生成数据的连续性;
- 注意力机制的探索:包括全局、局部、多头、空间和通道注意力的比较和分析。

















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









