









 本文提出了一种名为SESF-Fuse的无监督深度模型,用于多焦点图像融合。该模型利用编码器-解码器网络提取深层特征,并结合空间频率来度量活动水平,替代了传统的基于特征强度的方法。通过梯度模块和一致性验证,提高了融合图像的质量和鲁棒性。实验证明,SESF-Fuse在保留边缘信息和对比度方面优于16种经典方法,并且在速度和无监督学习方面具有优势,适合于物联网等应用场景。
本文提出了一种名为SESF-Fuse的无监督深度模型,用于多焦点图像融合。该模型利用编码器-解码器网络提取深层特征,并结合空间频率来度量活动水平,替代了传统的基于特征强度的方法。通过梯度模块和一致性验证,提高了融合图像的质量和鲁棒性。实验证明,SESF-Fuse在保留边缘信息和对比度方面优于16种经典方法,并且在速度和无监督学习方面具有优势,适合于物联网等应用场景。
SESF-Fuse: an unsupervised deep model for multi-focus image fusion
-
【引用格式】:Boyuan Ma et al. “SESF-Fuse: an unsupervised deep model for multi-focus image fusion” Neural Computing and Applications 33 (2021): 5793-5804.
-
【开源代码】:https://github.com/Keep-Passion/SESF-Fuse
一、瓶颈问题:
1、融合策略
DenseFuse提出AE架构的无监督图像融合方法,在红外光与可见光融合任务中,特征向量的 l 1 l_1 l1范数用于表示两张源图像对应像素点activity level,从而获得融合特征图,最后通过解码器得到融合图像。
l 1 l_1 l1范数能够度量像素的强度信息,然而,对于多聚焦图像融合任务,通常只假设DOF(景深)内的目标在照片中具有锐利的外观,这种任务场景中,重要的是特征的梯度信息, l 1 l_1 l1不是这一任务的有效度量方法。
2、有监督方法的不足
有监督的方法需要手工生成打标签的多聚焦数据集,同时,人工设计的掩模,与实际的多聚焦图像数据仍然有很大的不同
3、通用融合方法的局限
IFCNN[[1]](IFCNN: A general image fusion framework based on convolutional neural network)提一种基于深度学习的算法来处理不同类型的图像融合任务,但是在融合特定类型的图像时表现出有限的性能
4、提高生成融合图像的鲁棒性
基于决策图的方法也许会比使用解码器生成融合图像方法更鲁棒
二、 本文贡献:
1、提出了一种基于无监督深卷积网络的融合方法
该方法使用从encoder–decoder network中提取的深层特征和空间频率(spatial frequency)来测量活动水平(activity levels)。
2、进行了客观和主观实验
结果表明,与16种经典融合方法相比,该方法实现了最先进的融合性能(尤其是基于梯度的评估),并且略优于监督方法。
三、 解决方案:
本文以无监督的方式训练编码器-解码器网络,以获取输入图像的深层特征。然后,我们利用基于梯度的spatial frequency方法来测量这些深层特征的梯度变化,以反映活动水平。我们采用了一些一致性验证方法来调整决策图,并得出融合结果
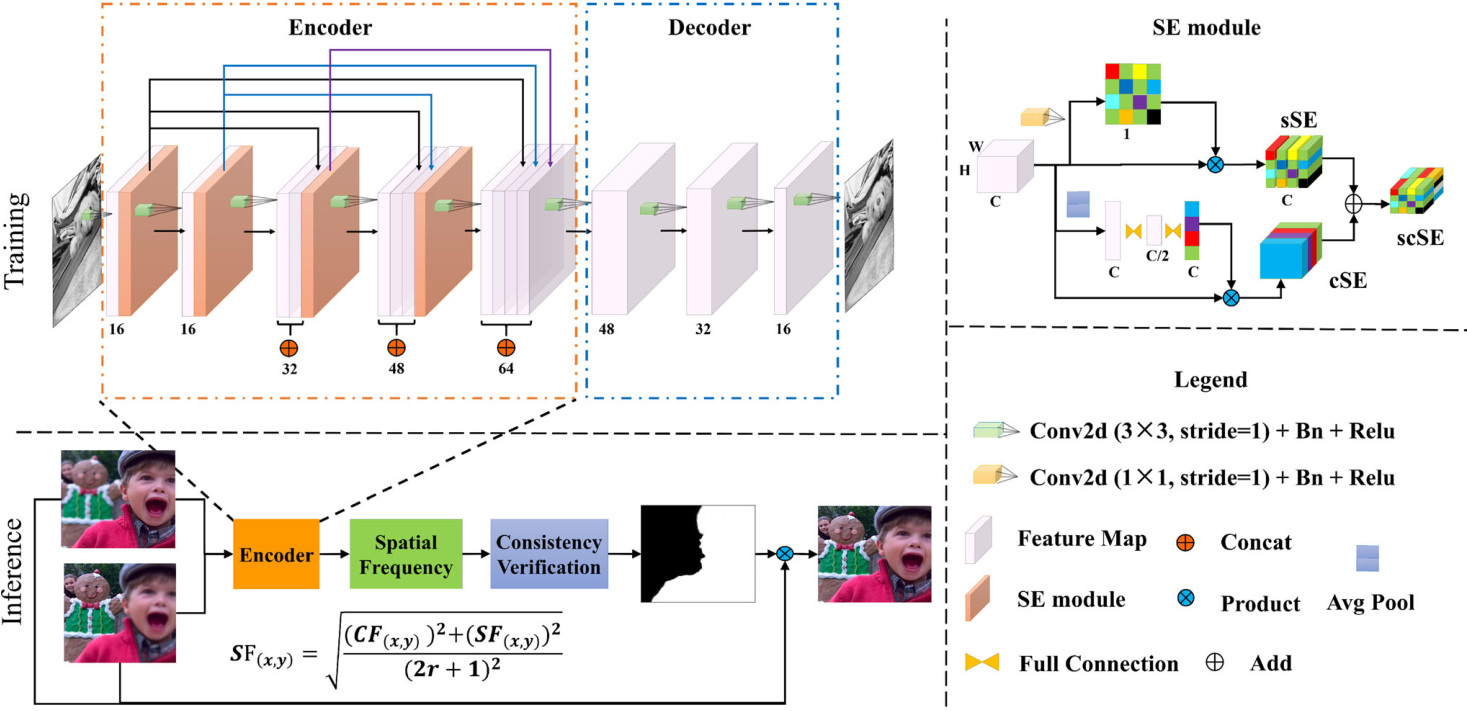
1、Extraction of deep features
(1)Encoder
- 结构: 包含五层卷积,每一层的输出串联到后面每一层中,能够加强特征的传播,降低参数量。
(2)Squeeze and excitation (SE) module
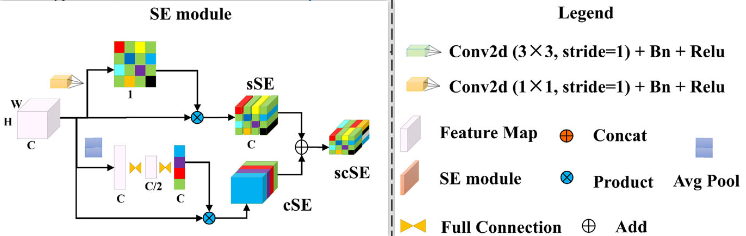
- 作用: SE[[2]](Squeeze-and-Excitation Networks)在图像识别和分割方面表现出了良好的性能。通过自适应地重新校准通道或空间特征响应,它可以有效地增强空间特征编码。
- 三个版本:
- spatial squeeze and channel excitation (sSE)
- channel squeeze and spatial excitation (cSE)
- concurrent spatial and channel squeeze and channel excitation (scSE)
- 结构:
- sSE:使用一个带有1×1核的卷积层来获取投影张量。投影的每个单元指的是空间位置上所有通道C的组合表示,并用于对原始特征地图进行空间校准。
- cSE:使用一个全局平均池层将全局空间信息嵌入到一个向量中,该向量通过两个全连接层来获取一个新的向量。这会对通道相关性进行编码,可用于在通道方向上重新校准原始特征映射。
- **scSE:**是cSE和sSE的元素相加,同时重新校准输入的空间和通道信息。
(3)Decoder
- **结构:**由四个卷积层组成,用于恢复输入图像。
(4)Loss function
-
构成:pixel loss L p L_p Lpand structural similarity (SSIM) loss $ L_{ssim}$
L = λ L s s i m + L p L=\lambda L_{ssim}+L_p L=λLssim+Lp -
L p L_p Lp:欧式距离
L p = ∣ ∣ O − I ∣ ∣ 2 L_p=||O-I||_2 Lp=∣∣O−I∣∣2 -
L s s i m L_{ssim} Lssim:结构相似性
L s s i m = 1 − S S I M ( O − I ) L_{ssim}=1-SSIM(O-I) Lssim=1−SSIM(O−I) -
SSIM
S S I M ( O , I ) = 2 μ O μ I + C 1 μ O 2 + μ I 2 + C 1 ⋅ 2 σ O σ I + C 2 σ O 2 + σ I 2 + C 2 ⋅ σ O , I + C 3 σ O 2 σ I 2 + C 3 SSIM(O,I)=\frac{2\mu_O\mu_I+C_1}{\mu^2_O+\mu^2_I+C_1}·\frac{2\sigma_O\sigma_I+C_2}{\sigma^2_O+\sigma^2_I+C_2}·\frac{\sigma_{O,I}+C_3}{\sigma^2_O\sigma^2_I+C_3} SSIM(O,I)=μO2+μI2+C12μOμI+C1⋅σO2+σI2+C22σOσI+C2⋅σO2σI2+C3σO,I+C3
三部分分别度量亮度、对比度、结构相似性
2、Fusion strategy
在推理阶段,我们从编码器获得图像的两个深层特征。我们利用空间频率来计算初始决策图,并应用一些常见的一致性验证方法来消除小错误。最后,我们得到了融合两幅多聚焦源图像的决策图。
(1)Spatial frequency calculation using deep features
-
活跃水平度量:基于特征梯度方法(代替基于特征强度的方法)
-
修改SF公式,实现像素级的度量(原始公式是图像整体的度量)
-
公式:(RF为行方向的梯度,CF为列方向的梯度)
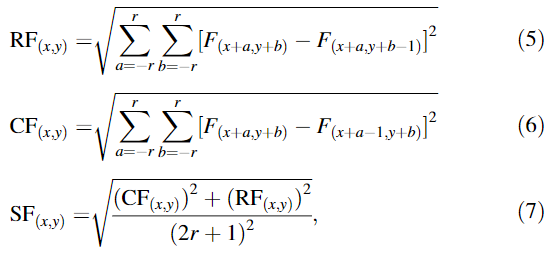
其中,F为encoder输出的特征图,r为核半径;RF为行向量频率;CF为列向量频率
-
生成初始决策图
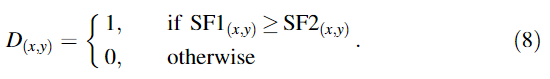
(2)Consistency verification
- 目的:减少图像中存在的噪声造成部分决策错误
- 一致性验证方法:
- ①形态学操作,如开操作和闭操作;
- ②小区域移除策略(阈值:0.01×H×W)
- ③边缘保持过滤(引导过滤):去除聚焦区域和散焦区域边界周围的一些不希望看到的伪影
(3)Fusion
-
像素级加权融合规则:
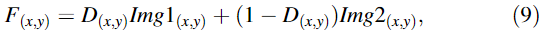
3、示意图:
- 源图像→决策图→融合图

四、 实验结果:
1、实验设置
- 测试集:38对公开的多聚焦图像
- 模型训练:使用MS-COCO训练encoder-decoder network(训练集:82783 images;验证集:40504 images)
- 训练阶段图像格式:转为灰度图,大小变为256×256
- 学习率: 1 × 1 0 − 4 1×10^{-4} 1×10−4,衰减系数0.8(每两轮)
- batch-size:48
- epoch:30
2、对比评估
- 对比方法(16种)
- 质量评估指标: Q g , Q m , Q c b Q_g,Q_m,Q_{cb} Qg,Qm,Qcb
(1) Q g Q_g Qg:评估边缘信息保留程度
①使用Sobel算法计算边缘强度和方向
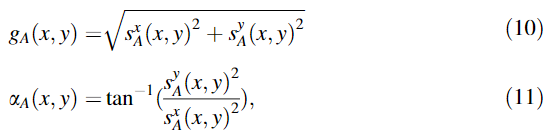
②计算源图像与融合图像的相对强度和方向
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q8YPiSsz-1649154320805)(https://cdn.jsdelivr.net/gh/1732562137/Picture/img/image-20220309164759539.png)]
③计算边缘强度和方向的保留值
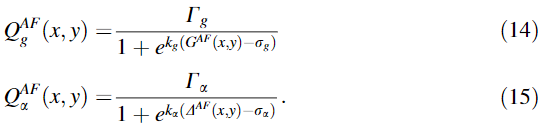
④计算边缘信息保留值
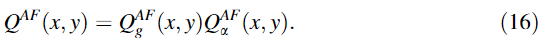
⑤计算两张源图像与融合图像的边缘信息保留值的加权平均值
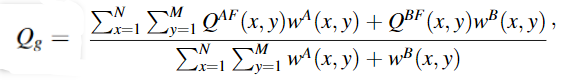
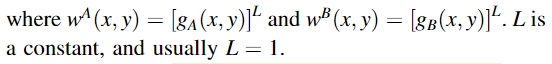
(2) Q m Q_m Qm:基于两级Haar小波的度量,从分解的高通分量和带通分量中检索边缘信息。
①计算第i个尺度水平、垂直、对角边缘保留值
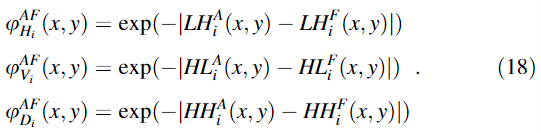
②计算全局边缘保留值
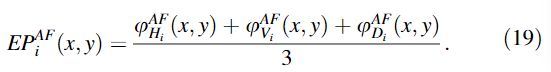
③计算第i个尺度的归一化性能度量
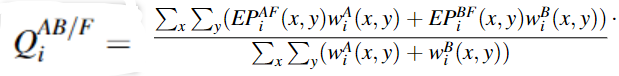
其中,权重系数由输入图像的高频能量定义:
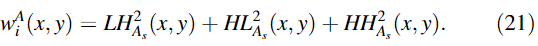
④计算总体度量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GEDQ9U0s-1649154320810)(https://cdn.jsdelivr.net/gh/1732562137/Picture/img/image-20220309175313877.png)]
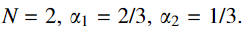
(3) Q c b Q_{cb} Qcb:是一种用于图像融合的感知质量度量
- 所有的图像都由empirical CSF使用DOG滤波器和傅里叶变换进行滤波
①计算局部对比度
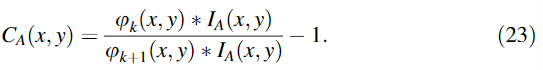
σ k = 2 k \sigma_k=2^k σk=2k的高斯核:
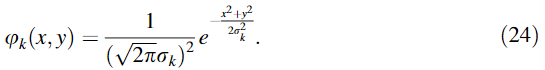
②计算masked contrast map

③计算显著图
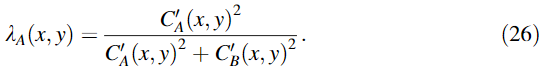
④计算信息保留值
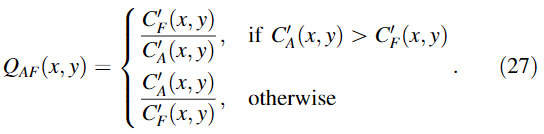
⑤计算全局质量图
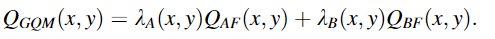
⑥计算度量值(对全局质量图几圈平均)

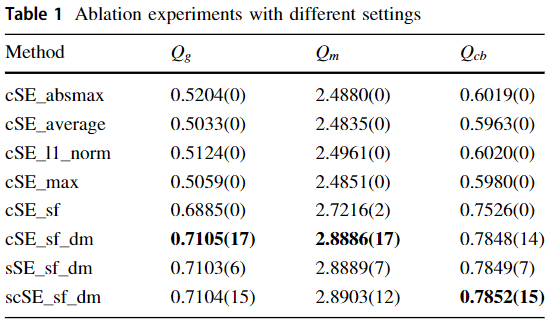
3、消融实验
-
目的:验证gradient module(spatial frequency)的贡献、deep features的利用
-
实验设置:8种融合模式【方法命名格式:(s)©SE_Y(_dm)】
Y表示fusion mode,包括:max, absmax, l1-norm, sf
dm表示采用encoder生成决策图进行图像融合的方法,没有dm表示decoder输出融合结果的方法
(s)©表示squeezeand excitation blocks 的三个版本:sSE, cSE, scS
-
实验结果:(不同方法的平均分数以及第一名的数量)(共38组测试图)
-
实验分析与结论:
①对比前6行:
- 在所有含cSE的方法中,sf超过abs-max,max,average,l1-norm的融合模式。
- 另外,采用决策图融合的方法优于由decoder直接输出融合图像的方法,说明,深度学习方法不能够完美的恢复图像和聚焦区域的细节信息。
②对比后3行:
- 三个版本的SE架构的对比结果表明cSE的效果优于其他两种,作者认为在通道进行特征校正更加重要和鲁棒。
③深层信息的有效性,
- 图像可以看到,使用SF对深层特征计算决策图比直接对源图像得到的融合结果保留更多细节特征,说明提取深层特征的有效性
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GPthQypd-1649154320816)(https://cdn.jsdelivr.net/gh/1732562137/Picture/img/image-20220311170636437.png)]
4、与经典方法的对比
(1)主观评估
①叶子图像边缘结果对比

- 其他方法存在伪影、部分未聚焦区域、亮度异常问题
②进一步观察:融合图像-源图像1→源图像1中的聚焦区域应该不显示

- 检测不佳: CVT,DSIFT, DWT, and DenseFuse-1e3-l1-Norm
- 检测较好(除边缘): SR, MWG, CNN
- SESF Fuse在中心和边界附近聚焦区域都表现良好

- 检测不佳: , CVT, DSIFT, DWT,NSCT, DenseFuse
- 检测较好(除边缘): MWG, CNN
- MWG存在远焦区域识别错误情况(红框)
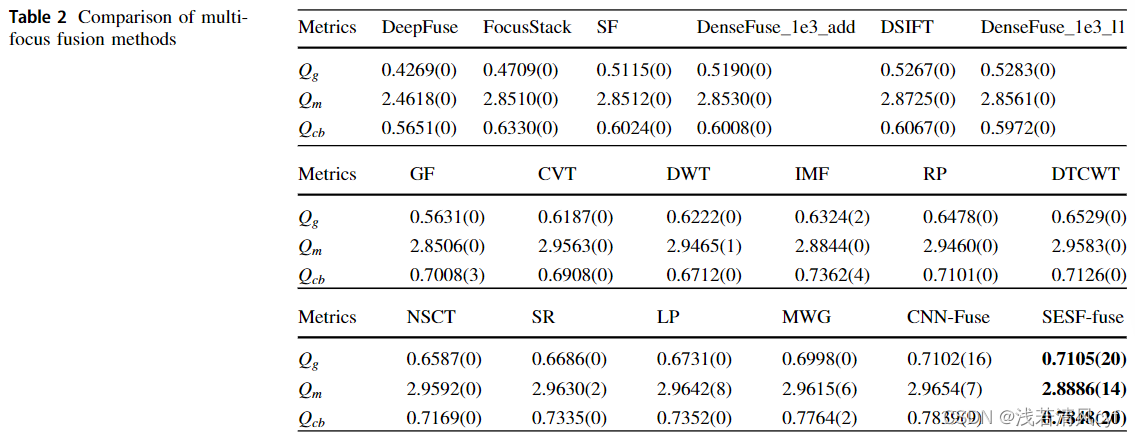
(2)客观评估
①18种方法在三个评估指标上的比较
- 在 Q g Q_g Qg和 Q c b Q_{cb} Qcb两个指标上,CNN-Fuse和SESF-fuse表现超过了其他方法
- 在 Q g Q_g Qg上,CNN-fuse(有监督方法)和SESF-fuse(无监督方法)性能相当
- 在 Q m Q_m Qm上,SESF-fuse在平均分数上低于LP方法,但是取得第一名的测试样本数量多于LP方法
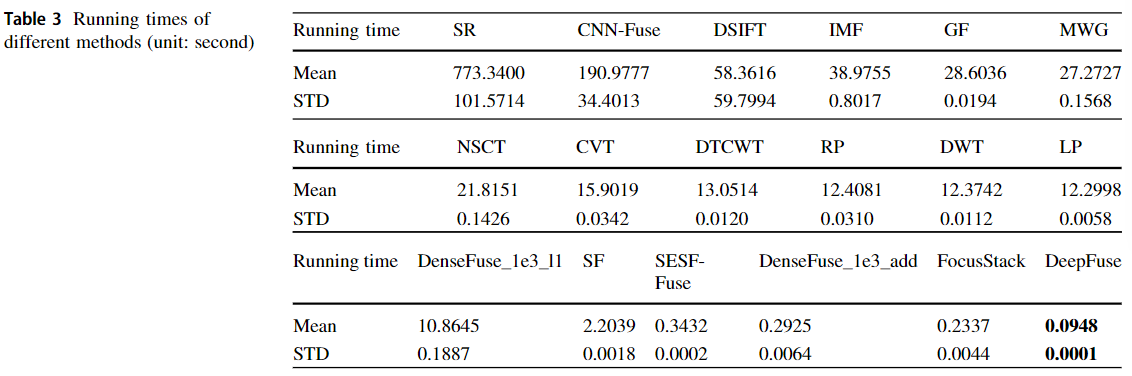
②18种方法的运行时间比较
- 实验条件:
- SESF, CNN-Fuse, DenseFuse, DeepFuse → GTX 1080Ti GPU
- other methods → E5-2620 CPU
- 实验结果:
- 由于卷积网络及其空间频率的并行实现,SESF Fuse的平均运行时间为0.3432秒,比大多数方法都快
- 尽管DeepFuse在这项测试中表现最好,但与DeepFuse相比,SESF Fuse的 Q g Q_g Qg性能提高了28%
- 实验结论:
- SESF Fuse具有快速的运行时间和无监督的网络体系结构,可以很容易地应用于特定应用,例如物联网,因为无需手动或自动生成可扩展的多焦点数据集来训练网络。
五、其他:
1、改进方法:
- 可以设计一种更复杂的梯度计算方法来取代我们的空间频率,以获得更好的性能。
- 更好实现多图像融合:采用多个编码器进行特征提取,然后通过一个解码器进行融合。其中,需要提高解码器的能力,以便更加准确恢复原像素值,而无需后处理。GAN和设计良好的损失函数可能是解决这个问题的好办法。
- 解决散焦扩散效应(defocus spread effect)。(聚焦散焦区域平滑,可获得更好的可视化融合结果,但会降低 Q g Q_g Qg)
2、总结
- **本文方法:**首先,采用无监督的方式训练编解码器网络,从而获取输入图像的深层特征。接着利用空间频率从这些特征中计算活动水平,并根据决策图进行图像融合。
- **实验结果:**与现有的融合方法相比,该方法取得了良好的融合性能,证明了无监督学习与传统图像处理算法相结合的可行性。



















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











