







论文题目:一种统一的无监督图像融合网络
一、摘要
本研究提出了一种新的统一的和无监督的端到端图像融合网络,称为U2 Fusion,它能够解决不同的融合问题,包括多模态,多曝光和多焦点的情况下。通过特征提取和信息度量,U2 Fusion自动估计对应源图像的重要性,并给出自适应的信息保持度。因此,不同的融合任务统一在同一个框架。基于自适应度,训练网络以保持融合结果与源图像之间的自适应相似性。因此,将深度学习应用于图像融合的绊脚石,例如,极大地减轻了对地面实况和专门设计的度量的要求。通过避免损失以前的融合能力时,训练一个单一的模型为不同的任务顺序,我们得到了一个统一的模型,适用于多个融合任务。此外,还发布了一个新的红外和可见光图像数据集RoadScene(可在https://github.com/hanna-xu/RoadScene获得),为基准评估提供了新的选项。在三个典型图像融合任务上的定性和定量实验结果验证了U2 Fusion的有效性和通用性。
1、存在的问题
(1)在传统的图像融合方法中,融合规则选择的有限性和人工设计的复杂性限制了性能的提高。
(2)在端到端模型中,融合问题通过依赖于用于监督学习的地面实况或用于非监督学习的专门设计的度量来解决。
(3)端到端的图像融合模型通常是为特定融合任务定制的端到端模型,例如FusionGAN,DDcGAN等这类融合任务通常针对红外和可见光图像融合而设计,通常不存在地面实况,因此,它是将监督学习应用于多模态图像融合的主要障碍。
2、挑战
不存在用于多个任务的通用地面实况或无参考度量。这些问题构成了模型统一性和监督或无监督学习应用的主要绊脚石。
3、主要贡献
(1)我们提出了一个用于各种图像融合任务的统一的框架。更具体地说,我们用统一的模型和统一的参数来解决不同的融合问题。我们的解决方案缓解了一些缺点,例如不同问题的单独解决方案,训练的存储和计算问题,以及持续学习的灾难性遗忘。
(2)本文提出了一种新的无监督图像融合网络,通过约束融合图像与源图像之间的相似性,克服了大多数图像融合问题中普遍存在的问题,缺乏通用地面实况和无参考度量.。
(3)我们发布了一个新的红外和可见光对齐图像数据集RoadScene,为图像融合基准评估提供了一个新的选择。可在https://github.com/hanna-xu/RoadScene上获取。
(4)我们在六个多模态、多曝光和多聚焦图像融合数据集上测试了所提出的方法。定性和定量结果验证了U2Fusion算法的可行性和通用性。
4、方法的主要优点
(1)不受人工设计的融合规则限制的端到端模型。
(2)用于各种融合任务而不是特定目标的统一模型,例如,独特的问题、度量的特殊性、二进制掩码的需要等。
(3)是不需要地面实况的无监督模型。
(4)通过持续学习来解决新任务而不丢失旧能力,它用统一的参数来解决多个任务。
二、提出的方法
1、问题陈述
针对图像融合的主要目标,即,为了保持源图像中的重要信息,我们的模型基于度量来确定这些信息的丰富度。如果源图像包含丰富的信息,那么融合结果就显得尤为重要,它应该与源图像具有很高的相似度。因此,探索一种统一的度量方法来确定源图像的信息保持程度是本文方法的关键。该方法不是在监督学习中最大化融合结果与地面真实值之间的相似度,而是依赖于这种程度来保持与源图像的自适应相似度。而且,作为一个无监督的模型,它适用于多个融合问题,地面真值是很难获得。
2、模型架构
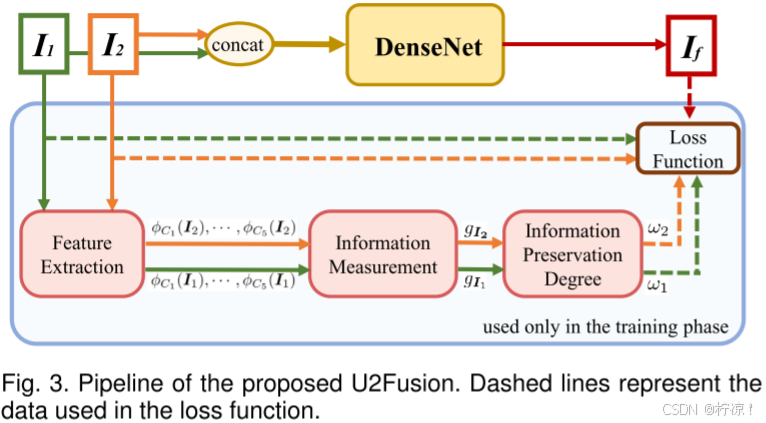
U2Fusion的流水线总结如图3所示。利用表示为![]() 和
和![]() 的源图像,训练DenseNet以生成融合图像
的源图像,训练DenseNet以生成融合图像![]() 。特征提取的输出是特征图
。特征提取的输出是特征图![]() 和
和![]() 。然后对这些特征图执行信息测量,产生由
。然后对这些特征图执行信息测量,产生由![]() 和
和![]() 表示的两个测量。通过后续处理,最终的信息保留度表示为ω1和ω2。I1、I2、If、ω1和ω2用于损失函数中,而不需要地面实况。在训练阶段,测量ω1和ω2并应用于定义损失函数。然后,优化DenseNet模块以最小化损失函数。在测试阶段,由于DenseNet已经过优化,因此不需要测量ω1和ω2。
表示的两个测量。通过后续处理,最终的信息保留度表示为ω1和ω2。I1、I2、If、ω1和ω2用于损失函数中,而不需要地面实况。在训练阶段,测量ω1和ω2并应用于定义损失函数。然后,优化DenseNet模块以最小化损失函数。在测试阶段,由于DenseNet已经过优化,因此不需要测量ω1和ω2。
3、特征提取
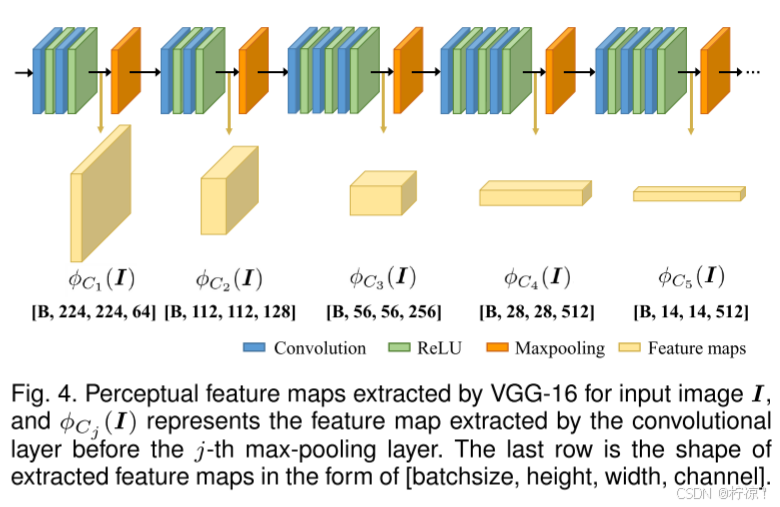
采用了预训练的VGG-16网络[37]进行特征提取,如图4所示。在我们的模型中,输入I已统一在单个通道中(我们将在第3.5进行讨论),我们将其复制到三个通道中,然后将其送入VGG-16。最大合并层之前的卷积层的输出是用于后续信息测量的特征图,如图4所示为![]() ,其图如下所示。
,其图如下所示。
4、信息测量
为了测量所提取的特征图中包含的信息,使用它们的梯度来进行评估。与一般信息论中的实体相比,图像梯度是一种基于局部空间结构的小感受野的度量。在深度学习框架中使用时,梯度在计算和存储方面都要高效得多。因此,它们更适合应用于CNN中的信息测量。信息度量定义如下:
![]()
其中![]() 是图4中第j个最大池
是图4中第j个最大池
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









