






 本文提出了一系列改进自监督深度估计的方法,包括最小重投影损失、全分辨率多尺度采样和自动屏蔽,以提高模型在处理遮挡和纹理复制伪影方面的性能,尤其在单目视频和立体对训练中,展示了最先进的结果在KITTI数据集上。
本文提出了一系列改进自监督深度估计的方法,包括最小重投影损失、全分辨率多尺度采样和自动屏蔽,以提高模型在处理遮挡和纹理复制伪影方面的性能,尤其在单目视频和立体对训练中,展示了最先进的结果在KITTI数据集上。

Abstract
逐像素地真深度数据的大规模获取具有挑战性。为了克服这一限制,自监督学习已经成为训练模型执行单目深度估计的有希望的替代方法。在本文中,我们提出了一系列改进措施,与竞争的自监督方法相比,这些改进措施在数量和质量上都提高了深度图。
对自监督单目训练的研究通常会探索越来越复杂的架构、损失函数和图像形成模型,所有这些都有助于缩小与全监督方法的差距。我们展示了一个令人惊讶的简单模型,以及相关的设计选择,导致了更好的预测。特别是,我们提出(i)最小的重投影损失,旨在鲁棒地处理遮挡,(ii)减少视觉伪影的全分辨率多尺度采样方法,以及(iii)自动屏蔽损失,以忽略违反相机运动假设的训练像素。我们单独展示每个组件的有效性,并在KITTI基准上显示高质量,最先进的结果。
Introduction
我们试图从单个颜色输入图像中自动推断出密集深度图像。估计绝对深度,甚至相对深度,如果没有第二个输入图像来实现三角测量,似乎是不合适的。因此,人类从现实世界中的导航和交互中学习,使我们能够对新场景进行合理的深度估计[18]。
从颜色中产生高质量的深度是有吸引力的,因为它可以廉价地补充自动驾驶汽车中使用的激光雷达传感器,并实现新的单张照片应用,如图像编辑和ar合成。求解深度也是一种使用大型未标记图像数据集进行深度网络预训练的有效方法,用于下游判别任务[23]。然而,为监督学习收集具有准确地面真值深度的大型、多样的训练数据集[55,9]本身就是一项艰巨的挑战。作为替代,最近几个自我监督方法表明,可以只使用同步立体对[12,15]或单目视频[76]来训练单目深度估计模型。
在两种自我监督方法中,单目视频是一种有吸引力的替代基于立体的监督方法,但它也引入了自己的一系列挑战。除了估计深度外,该模型还需要在训练过程中估计时间图像对之间的自运动。这通常需要训练一个姿态估计网络,该网络以有限的帧序列作为输入,并输出相应的相机变换。相反,使用立体数据进行训练使相机姿势估计成为一次性离线校准,但可能导致与遮挡和纹理复制伪影相关的问题[15]。
我们提出了三个架构和损失的创新,结合起来,当使用单眼视频、立体对或两者同时训练时,可以大大改善单眼深度估计:(1)一种新颖的外观匹配损失,以解决使用单眼监督时出现的遮挡像素问题。(2)一种新颖而简单的自动掩码方法,在单目训练中忽略未观察到相机的相对运动的像素。(3)在输入分辨率下执行所有图像采样的多尺度外观匹配损失,导致深度伪影的减少。总之,这些贡献在KITTI数据集上产生了最先进的单目和立体自监督深度估计结果[13],并简化了现有最佳表现模型中的许多组件。
Related Work
我们回顾了在测试时将单个彩色图像作为输入并预测每个像素的深度作为输出的模型。
2.1. Supervised Depth Estimation
从单个图像估计深度是一个固有的不适定问题,因为相同的输入图像可以投影到多个合理的深度。为了解决这个问题,基于学习的方法已经证明自己能够拟合利用彩色图像与其相应深度之间关系的预测模型。各种方法,如结合局部预测[19,55],非参数场景采样[24],到端到端监督学习[9,31,10]已经进行了探索。基于学习的算法在立体估计[72,42,60,25]和光流[20,63]方面的表现也是最好的。
上述许多方法都是完全监督的,在训练期间需要地面真值深度。然而,在不同的现实环境中,这是具有挑战性的。因此,有越来越多的工作利用弱监督训练数据,例如以已知对象大小[66],稀疏有序深度[77,6],监督外观匹配项[72,73]或未配对的合成深度数据[45,2,16,78]的形式,同时仍然需要收集额外的深度或其他注释。合成训练数据是另一种选择[41],但生成大量包含各种真实世界外观和运动的合成数据并非易事。最近的研究表明,传统的运动结构(SfM)管道可以为相机姿势和深度生成稀疏的训练信号[35,28,68],其中SfM通常作为与学习解耦的预处理步骤运行。最近,[65]在我们的模型的基础上,结合了传统立体算法的噪声深度提示,改进了深度预测。
2.2. Self-supervised Depth Estimation
在没有真实深度的情况下,一种替代方法是使用图像重建作为监督信号来训练深度估计模型。在这里,模型以一组图像作为输入,这些图像可以是立体对的,也可以是单眼序列的。通过对给定图像的深度产生幻觉并将其投射到附近的视图中,通过最小化图像重建误差来训练模型。
自监督立体对训练
自我监督立体训练一种形式来自立体成对。在这里,在训练过程中可以使用同步的立体对,通过预测对之间的像素差,可以训练深度网络在测试时进行单目深度估计。[67]针对新颖视图合成问题提出了这样一种深度离散化的模型。[12]通过预测连续的视差值扩展了该方法,[15]通过包含一个左右深度一致性项产生了优于当代监督方法的结果。基于立体的方法已经扩展到半监督数据[30,39]、生成对抗网络[1,48]、附加一致性[50]、时间信息[33,73,3]和实时使用[49]。
在这项工作中,我们表明,通过仔细选择外观损失和图像分辨率,我们可以仅使用单眼训练达到立体训练的性能。此外,我们的贡献之一延续到立体声训练,从而提高了表现。
自监督单目视频训练
一种约束较少的自我监督形式是使用单眼视频,其中连续的时间帧提供训练信号。在这里,除了预测深度之外,网络还必须估计帧之间的相机姿势,这在物体运动的情况下是具有挑战性的。这个估计的相机姿态只需要在训练期间帮助约束深度估计网络。
在最早的单目自监督方法之一中,[76]训练了一个深度估计网络以及一个单独的姿态网络。为了处理非刚性场景运动,一个额外的运动解释掩模允许模型忽略违反刚性场景假设的特定区域。然而,他们的模型的后来的在线迭代禁用了这个术语,实现了卓越的性能。受[4]的启发,[61]提出了一种使用多个运动蒙版的更复杂的运动模型。然而,这并没有得到充分的评估,因此很难理解它的效用。[71]也将运动分解为刚性和非刚性分量,利用深度和光流来解释物体运动。这改善了流量估计,但当流量和深度联合训练时,他们报告没有改善估计。在光流估计的背景下,[22]表明它有助于明确地建模遮挡。
最近的方法已经开始缩小单目和基于立体的自我监督之间的绩效差距。[70]约束预测深度与预测表面法线一致,[69]强制边缘一致性。[40]提出了一种基于近似几何的匹配损失来促进时间深度一致性。[62]使用深度归一化层来克服[15]中常用的深度平滑项所产生的对较小深度值的偏好。[5]使用预先计算的已知类别的实例分割掩码来帮助处理移动的对象。
基于外观的损失
自监督训练通常依赖于对帧之间物体表面的外观(例如亮度恒定)和材料属性(例如朗伯量)进行假设。[15]表明,与简单的两两像素差相比,包含基于局部结构的外观损失[64]显著提高了深度估计性能[67,12,76]。[28]将该方法扩展到包含误差拟合项,[43]探索将其与基于对抗性的损失相结合,以促进逼真的合成图像。最后,受[72]的启发,[73]使用ground truth depth来训练一个外观匹配项。
Method
在这里,我们描述了我们的深度预测网络,它接受单个颜色输入It并产生深度图Dt。我们首先回顾了用于单目深度估计的自监督训练背后的关键思想,然后描述了我们的深度估计网络和联合训练损失。
3.1. Self-Supervised Training
自监督深度估计通过训练网络从另一个图像的视点预测目标图像的外观,将学习问题框架为一个新的视图合成问题。通过约束网络使用中间变量执行图像合成,在我们的例子中是深度或视差,然后我们可以从模型中提取可解释的深度。这是一个不适定的问题,因为在给定两个视图之间的相对姿态的情况下,每个像素可能存在大量不正确的深度,可以正确地重建新视图。经典的双目和多视角立体方法通常通过在深度图中强制平滑来解决这种模糊性,并且在通过全局优化求解每像素深度时通过计算补丁上的照片一致性来解决这种模糊性[11]。
与[12,15,76]类似,我们也将问题表述为训练时光度重投影误差的最小化。我们将每个源视图It’相对于目标图像It的相对姿态表示为Tt→t’。我们预测了一个密集的深度图Dt,使光度重投影误差Lp最小化,其中
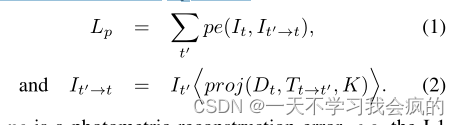
其中pe为光度重建误差,例如像素空间中的L1距离;proj()是It’和投影深度Dt的二维坐标。<>是采样算子。为了简化标记,我们假设所有视图的预先计算的固有K是相同的,尽管它们可能不同。继[21]之后,我们采用双线性采样对源图像进行局部次可微采样,继[75,15]之后,我们采用L1和SSIM[64]使光度误差函数pe,即
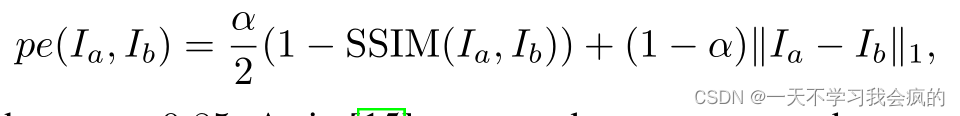
其中α = 0.85。在[15]中,我们使用边缘感知平滑:
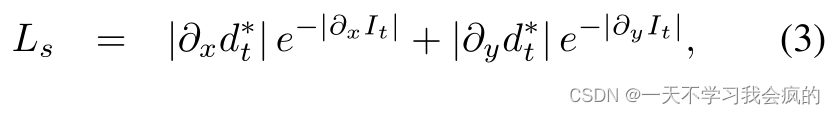
其中d∗t = dt/—dt是来自[62]的平均归一化逆深度,以防止估计深度的萎缩。
在立体训练中,我们的源图像It’是它的立体对中的第二个视图,它有已知的相对姿态。虽然单眼序列的相对姿态是未知的,但[76]表明,可以训练第二个姿态估计网络来预测投影函数项目j中使用的相对姿态Tt→t’。在训练过程中,我们同时求解相机姿态和深度,以最小化Lp。对于单目训练,我们使用在时间上相邻的两帧作为源帧,即It’∈{It−1,It+1}。在混合训练(MS)中,It’包括时间上相邻的帧和相对的立体视图。
3.2. Improved Self-Supervised Depth Estimation
现有的单目方法产生的深度质量比最好的全监督模型要低。为了缩小这一差距,我们提出了几种显著提高预测深度质量的改进方法,而不需要添加同样需要训练的额外模型组件(见图3)。
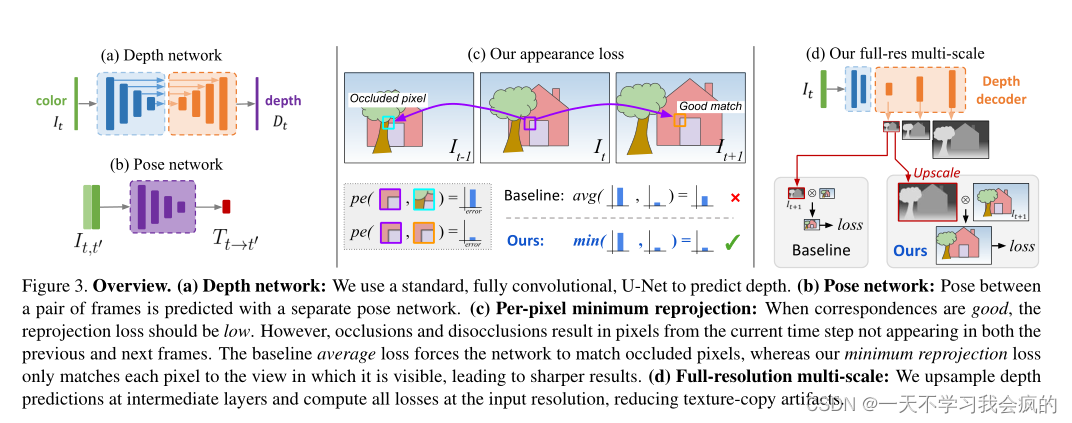
图3 概述。(a)深度网络:我们使用标准的全卷积U-Net来预测深度。(b)姿态网络:用一个单独的姿态网络预测一对帧之间的姿态。©每像素最小重投影:当对应良好时,重投影损失应低。然而,遮挡和解除遮挡导致当前时间步长的像素不会出现在前一帧和下一帧中。基线平均损失迫使网络匹配遮挡的像素,而我们的最小重投影损失仅将每个像素匹配到它可见的视图,从而导致更清晰的结果。(d)全分辨率多尺度:我们在中间层上采样深度预测,并在输入分辨率上计算所有损失,减少纹理复制伪影。
逐像素最小重投影损失
在计算多源图像的重投影误差时,现有的自监督深度估计方法将重投影误差平均到每个可用的源图像中。这可能导致在目标图像中可见的像素出现问题,但在某些源图像中不可见(图3©)。如果网络预测了这样一个像素的正确深度,那么被遮挡的源图像中相应的颜色可能与目标不匹配,从而导致很高的光度误差惩罚。这些有问题的像素主要来自两大类:由于图像边界的自我运动而导致的视线外像素和遮挡像素。视野外像素的影响可以通过在重投影损失中掩盖这些像素来降低[40,61],但这并不能处理咬合,平均重投影会导致模糊的深度不连续。
我们提出了一个解决这两个问题的改进方案。对于每个像素,我们简单地使用最小值,而不是在所有源图像上平均光度误差。
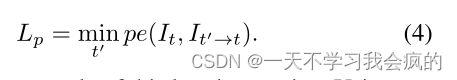
如图4所示,这是实际应用中损耗的一个例子。使用我们的最小重投影损失显著减少了图像边界的伪影,提高了遮挡边界的清晰度,并提高了精度(见表2)。

图4 MS训练中最小重投射损失的益处。圆圈区域中的像素在IR中被遮挡,因此在(IL, IR)之间没有应用损失。相反,像素匹配到I−1,在那里它们是可见的。右上方图像中的颜色表示选择底部哪个源图像进行Eqn匹配。
自动屏蔽静止像素
自监督单目训练通常在移动摄像机和静态场景的假设下进行。当这些假设失效时,例如当相机静止或场景中有物体运动时,性能可能会受到很大影响。这个问题可以在预测的测试时间深度图中表现为无限深度的“洞”,对于在训练期间通常观察到移动的对象38。这激发了我们的第二个贡献:一种简单的自动屏蔽方法,过滤掉序列中从一帧到下一帧外观不改变的像素。这样做的效果是让网络忽略与摄像机移动速度相同的物体,甚至在摄像机停止移动时忽略单目视频中的整个帧
与其他作品[76,61,38]一样,我们也对损失应用逐像素掩码µ,选择性地对像素进行加权。然而,与之前的工作相比,我们的掩码是二进制的,因此µ∈{0,1},并且在网络的前向传递中自动计算,而不是从物体运动中学习或估计。我们观察到,序列中相邻帧之间保持相同的像素通常表示静态摄像机,以等效相对平移移动的对象或低纹理区域。因此,我们设置µ仅包括像素损失,其中扭曲图像It’→t的重投影误差低于原始,未扭曲的源图像I‘t,即。
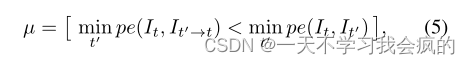
其中**[]为艾弗森括号**。在相机和另一个物体都以相似的速度移动的情况下,µ可以防止图像中保持静止的像素污染损失。同样,当相机静止时,掩模可以滤除图像中的所有像素(图5)。我们通过实验证明,这种简单而廉价的对损耗的修正带来了显著的改善。

图5 Auto-masking。我们展示了在一个epoch后计算的自动遮罩,其中黑色像素从损失中移除(即µ= 0)。遮罩防止物体以与相机(顶部)相似的速度移动,并防止相机静止(底部)的整个帧污染损失。掩码是使用Eqn. 5从输入帧和网络预测计算得到的。
多尺度估计
考虑到双线性采样器的梯度局域性[21],为防止训练目标陷入局部极小值,现有模型采用多尺度深度预测和图像重建。这里,总损耗是解码器中每个尺度的单个损耗的组合。[12,15]在每个解码器层的分辨率下计算图像的光度误差。我们观察到,这倾向于在中等低分辨率深度图中的大型低纹理区域中创建“洞”,以及纹理复制伪影(深度图中的细节错误地从彩色图像转移)。在光度误差不明确的低纹理区域,在低分辨率下会出现深度孔。这使深度网络的任务变得复杂,现在可以自由地预测不正确的深度.
受立体重建技术的启发[56],我们提出了对这种多尺度公式的改进,其中我们解耦了用于计算重投影误差的视差图像和彩色图像的分辨率。我们不是在模糊的低分辨率图像上计算光度误差,而是首先将低分辨率深度图(从中间层)上采样到输入图像分辨率,然后重新投影,重新采样,并在这个更高的输入分辨率下计算误差pe(图3 (d))。这个过程类似于匹配补丁,因为低分辨率的视差值将负责在高分辨率图像中扭曲整个“补丁”像素。这有效地约束了每个尺度的深度图都朝着同一个目标工作,即尽可能准确地重建高分辨率输入目标图像。
最终训练损失
我们将我们的逐像素平滑度和掩蔽光度损失结合为L =µLp + λLs,并对每个像素,尺度和批次进行平均。
额外的注意事项
我们的深度估计网络基于通用的U-Net架构[53],即一个编码器-解码器网络,具有跳过连接,使我们能够既表示深度抽象特征,又表示局部信息。我们使用ResNet18[17]作为我们的编码器,它包含11M个参数,与现有工作中使用的更大、更慢的disnet和ResNet50模型[15]相比。与[30,16]类似,我们从ImageNet[54]上预训练的权重开始,并表明与从头开始训练相比,这提高了我们紧凑模型的准确性(表2)。
我们的深度解码器类似于[15],在输出处使用s形,在其他地方使用ELU非线性[7]。我们将s形输出σ转换为D = 1/(σ + b)的深度,其中选择a和b来约束D在0.1到100个单位之间。
我们在解码器中使用反射填充来代替零填充,当样本落在图像边界之外时,返回源图像中最近的边界像素的值。我们发现,这大大减少了现有方法中的边界伪影,例如[15]。
对于姿态估计,我们遵循[62]并使用轴角表示来预测旋转,并将旋转和平移输出缩放0.01。对于单眼训练,我们使用三帧的序列长度,而我们的姿态网络由ResNet18形成,修改为接受一对彩色图像(或六个通道)作为输入,并预测单个6-DoF相对姿态。我们执行水平翻转和以下训练增强,有50%的机会:随机亮度,对比度,饱和度和色调抖动,各自的范围为±0.2,±0.2,±0.2和±0.1。重要的是,颜色增强只应用于输入网络的图像,而不是用于计算Lp的图像。输入姿态和深度网络的所有三张图像都用相同的参数进行增强。
我们的模型是在PyTorch[46]中实现的,使用Adam[26]训练了20个epoch,批量大小为12,输入/输出分辨率为640 × 192,除非另有说明。对于前15个epoch,我们使用10−4的学习率,然后对于其余的epoch,学习率下降到10−5。这是使用10%数据的专用验证集来选择的。平滑项λ设为0.001。训练需要8、12和15个小时在一个单一的泰坦Xp上,为立体(S),单目(M),和单目加立体模型(MS)。

















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









