




Abstract
在单目深度估计中,图像环境中的干扰,如移动的物体或反射的材料,很容易导致错误的预测。因此,每个像素的不确定性估计是必要的,特别是对于自动驾驶等安全关键应用。我们提出了一种事后不确定性估计方法,用于已经训练的固定深度估计模型,该模型由深度神经网络表示。用辅助损失函数提取的梯度估计不确定性。为了避免依赖于地面真值信息的损失定义,我们提出了一个基于图像深度预测与其水平翻转对应的对应关系的辅助损失函数。我们的方法在KITTI和NYU Depth V2基准测试中实现了最先进的不确定性估计结果,而无需重新训练神经网络。模型和代码可在https://github.com/jhornauer/GrUMoDepth上公开获得。
1 Introduction
深度神经网络在深度预测等3D感知任务中表现出惊人的性能[9,15]。单幅图像的深度估计特别引人注目,因为与LiDAR传感器相比,RGB相机更便宜,同时提供更高的分辨率和帧率。然而,图像环境中的干扰,如遮挡、移动物体或反射材料,很容易影响神经网络,从而导致错误的预测[20]。因此,估计深度估计的不确定性至关重要,特别是对于自动驾驶等安全关键应用。
bootstrap ensembles[16]和Monte Carlo Dropout[6]是众所周知的不确定性估计方法,它们已经被用于计算昂贵的任务,如深度估计[22]。这两种方法都依赖于模型分布的采样,由于计算成本高,不适合实时应用。预测方法,如最大值.另一方面,似然最大化[13,14]要求训练过程适应对数据中包含的不确定性进行估计。此外,以不确定性估计为目标对神经网络进行再训练是不可能的。例如,由外部来源提供的模型参数通常是不可访问的,因此是不可修改的。对于目标系统专用的神经网络模型(例如,通过修剪)或必须满足某些系统要求的神经网络模型,参数修改是不可行的。由于这些原因,我们的目标是在一个事后的方式已经训练模型的不确定性估计的问题。
一种无需训练的不确定性估计方法是仅在推理过程中使用dropout[18]。虽然这种方法不需要对训练协议进行任何调整,但不确定性估计仍然是基于模型分布的采样,因此不适合实时应用。相比之下,我们建议基于从神经网络中提取的梯度来估计不确定性,这种方法的计算强度要小得多,并且只需要额外的一次反向传递。
受分类中基于梯度的分布外检测方法的启发[17,11],我们使用梯度来估计与单目深度估计模型获得的逐像素深度相关的不确定性。给定一个训练好的模型,我们的目标是在不依赖于真实深度值的情况下提取有意义的梯度。因此,我们基于图像深度预测与水平翻转图像的对应关系定义了一个辅助损失函数。将损失定义为两个深度预测之间的误差,我们通过神经网络反向传播来计算导数的w.r.t.特征映射。然后,我们依靠从深度估计模型的解码器层的特征映射中提取的梯度来获得最终的不确定性评分。重要的是,我们的方法在不需要重新训练神经网络的情况下获得了最先进的不确定性估计结果。
总的来说,我们总结了本文的贡献如下:
首先,我们提出了一种基于从已训练模型中提取的梯度的事后不确定性估计方法。从本质上讲,我们的方法与模型的训练方式无关。
其次,对于梯度生成,我们定义了一个不依赖于真地深度值的辅助损失函数。在此背景下,我们通过经验证明了基于梯度的不确定性估计的意义。
最后,在对两种常用深度估计基准KITTI[7]和NYU depth V2[19]的现有方法进行广泛比较后,我们展示了最先进的不确定性估计结果。
2 Related Work
Depth Estimation Uncertainty
与分类任务相比,高维预测(如深度估计)的不确定性更难确定。一般来说,认知不确定性和任意不确定性是有区别的。认知不确定性来自模型权重,并且可以通过更多的训练数据来减少,而任意不确定性则是由于模型输入中的噪声。bootstrap ensembles[16]和Monte Carlo (MC) Dropout[6]通过对参数分布建模来估计认知不确定性。对于自举集成,这是通过训练多个模型来实现的,从指定的分布中采样初始权值,而对于MC Dropout,在训练和推理期间应用Dropout层。深度估计和不确定性估计分别通过从模型分布中抽样和计算均值和方差得到。一种考虑选择性不确定性的预测方法是通过最大化负对数似然来学习具有均值和方差的分布,该分布表示数据相关误差,而不是单个输出值[14]。Kendall和Gal[13]展示了如何将这两种不确定性结合起来。最近的研究探索了计算密集型任务的不确定性集成,如深度估计[4,28]、语义分割[10]、光流[26]或多任务学习[31]。此外,Poggi等[22]广泛比较了自监督深度估计的不同经验和预测不确定性估计方法。其中,Godard等人[8]提出的图像翻转后处理作为一个简单的基线,以获得两个输出的方差作为不确定性度量。此外,Poggi等人[22]提出了他们的自我训练方法,其中通过使用从教师模型中获得的知识(将其预测作为标签),通过对数似然最大化学习到的方差得到改善。
这些方法的一个缺点是模型设计的适应性[14]或特定的训练管道[6,16]。此外,经验方法具有额外的计算开销[6,16]和增加的内存占用[16],使其不适合自动驾驶或机器人等实时应用。相比之下,在这项工作中,我们探索了梯度作为独立于所进行的训练过程的事后不确定性估计方法的使用。由于模型再训练并不总是可行的,Mi等人[18]探索了不同的无训练策略,通过数据增强、推理时间dropout和中间网络层的加性噪声来生成模型输出上的分布。我们还探索了无需训练的不确定性估计,但放弃了计算密集的采样,依赖于用辅助损失函数提取的梯度。
3 Method
考虑一个深度神经网络d = f(x;θ),参数为θ,它以宽度为w,高度为h的图像x∈Rw×h×3为输入,并预测像素深度d∈Rw×h×1。基于训练好的深度预测模型fθ,我们的目标是预测每个预测深度值的不确定性u∈Rw×h×1。
Post Hoc Uncertainty Estimation
在这项工作中,我们的目标是事后不确定性估计。我们不调整模型参数,而只假设访问由特征映射ai给出的内部模型表示,其中i表示从深度解码器的第i层获得的特征映射。本质上,我们估计了已经训练好的深度估计模型的不确定性,因此不需要调整训练协议或网络设计。此外,我们的方法独立于底层模型训练策略。例如,深度估计模型可以用单目或立体监督的监督或自监督的方式进行训练。图1概述了我们的方法。
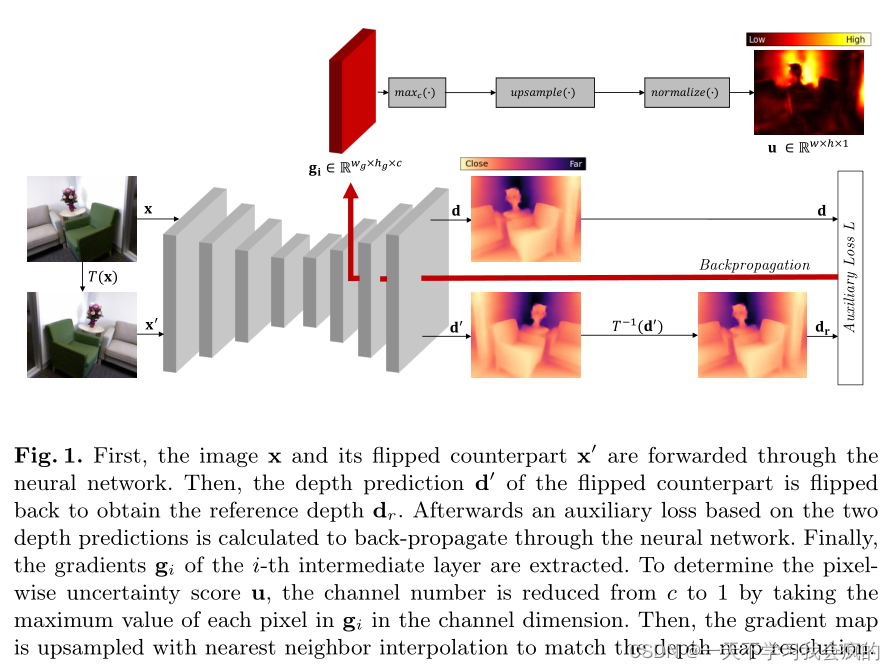
图1 首先,图像x和翻转后的图像x '通过神经网络转发。然后,对翻转后的对应深度预测d '进行反向翻转,得到参考深度dr.,然后计算基于这两个深度预测的辅助损失,通过神经网络进行反向传播。最后,提取第i中间层的梯度gi。为了确定像素不确定性评分u,通道数从c减少到1,方法是取通道维度中gi中每个像素的最大值。然后,用最近邻插值对梯度图进行上采样,以匹配深度图的分辨率。
3.1 Gradient-based Uncertainty
Gradient Generation
我们建议使用从特征图中提取的梯度来估计深度预测的像素不确定性。对于梯度生成,必须首先定义像素级损失函数,然后使用反向传播对各自的特征映射进行损失函数的导数。我们的目标是将模型损失转换为逐像素的不确定性估计。我们假设像素不确定性与深度估计误差一致。我们后来在评估中以经验证明我们的主张。
一般来说,最有意义的损失函数是深度预测d与真地深度y∈Rw×h×1之间的误差。尽管如此,我们在训练期间可以获得基本事实信息,但在推理期间却不能。因此,我们为梯度生成定义了一个辅助损失函数L。对于该损失函数的定义,我们考虑参考图像x ',其结构等于原始图像x的结构。我们假设x和x '预测的深度映射d和d '匹配。为了生成参考图像x ',我们定义了水平翻转操作T(·),它执行左右翻转。逆函数T−1(·)将翻转操作还原。图像x上的深度预测与水平翻转版本x ’ = T (x)应该是一致的,因为线性变换保留了原始图像的像素信息,从而保留了场景的结构。
总的来说,参考深度dr是翻转图像x预测的深度d ',它被翻转回来以匹配原始输入图像x获得的深度d。更准确地说,我们进行两次前向传递,一次与原始图像x一起获得d = f(x);θ)和一个翻转版本x ’ = T (x),得到d ’ = f(x ';θ)。然后,我们应用逆函数T−1(d ')来获得参考深度dr。然后根据深度d和参考深度dr之间的差定义辅助损失函数(参见3.2节)。为了得到梯度,我们计算损失w.r.对各自特征映射ai的导数:

式中gi∈Rw~g~×h~g~×c,其中wg为特征图宽度,hg为特征图高度,c为通道号。
Uncertainty Score
接下来,从神经网络中提取的梯度gi中确定像素不确定性估计u。由于每个像素都需要一个不确定性值,因此梯度图必须匹配深度图的分辨率。首先,我们定义函数maxc(·):Rw~g~×h~g~×c→Rw~g~×h~g~×1在通道维度上执行最大池化:

其中g(max) i∈Rw~g~×h~g~×1。我们感兴趣的是使用最大池化操作来收集具有最大幅度的梯度用于不确定性估计。然后,我们定义函upsample(·):Rw~g~×h~g~×1→Rw×h×1通过最近邻插值来upsample g(max) i。最后,我们提出了不确定性估计作为自归一化梯度映射:
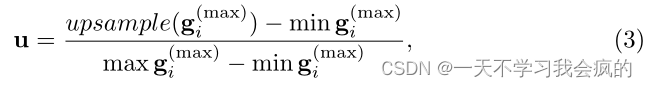
其中Max g(Max) i和min g(Max) i分别是梯度图的最大值和最小值。然后将最终的不确定性归一化为[0,1]的范围。
3.2 Training Strategy
我们实例化了基于预测深度d和参考深度dr的梯度生成的辅助损失函数。首先,我们定义了仅预测深度d = fr(x;θr)。然后,我们考虑贝叶斯深度估计模型d, σ = fb(x;θb),其中d是深度,σ是作为不确定性度量的方差。
Depth Estimation Model
对于不预测不确定性而只预测深度的标准深度估计模型fθr,其辅助损失函数定义如下:

不确定性估计可以通过后处理步骤生成,其中应用图像翻转来估计不确定性为两个输出的方差(Post)[9]。这里,方差也是两个深度预测的逐像素差异。我们声称,与仅由损失给出的不确定性相比,由特征映射的梯度给出的信息更高。第4.2节的结果支持了这一点,其中我们通过经验证明,与简单地依赖图像翻转作为后处理步骤相比,特征映射的梯度给出的信息对于不确定性估计更有效。
Bayesian Depth Estimation Model
由于我们的方法独立于底层训练策略,我们不仅考虑传统的深度估计模型,而且还考虑贝叶斯版本fθb,它已经预测了方差作为不确定性度量。提出了不同的训练贝叶斯模型的策略。一种是对数似然最大化目标(Log)训练,另一种是Poggi等人[22]提出的自我教学范式(Self)。对于贝叶斯深度预测网络,我们的目标是改进方差给出的不确定性估计。由于这些模型不仅输出逐像素深度d,而且还输出逐像素方差σ,因此我们也利用方差来生成梯度。在这种情况下,我们将方差平方加到损失项中。贝叶斯模型的辅助损失如下:

其中λ控制方差损失项的影响。由于σ代表数据固有的误差,方差越大梯度越大,方差越小梯度越小。

















 7832
7832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









