







最近了解到了动态卷积的这一概念,觉得使用动态卷积来替换常规卷积能够减少很多的计算量,所以便记录一下有关动态卷积三篇论文的学习笔记。
目录
一:CondConv: Conditionally Parameterized Convolutions for Efficient Inference
二:Dynamic Convolution: Attention over Convolution Kernels
三:Omni dimensional dynamic convolution
一:CondConv: Conditionally Parameterized Convolutions for Efficient Inference
卷积是当前CNN网络的基本构成单元之一,其有一个基本的假设就是卷积参数对所有样例共享。本文提出了一种动态卷积,它可以为每一个样例学习一个特定的卷积核参数。
以往的CNN的性能提升更多源自于模型尺寸和容量的提升以及更大的数据集。但是模型尺寸的进一步提升会加大计算开销。
作者提出了一种条件参数卷积来解决上述问题,通过计算卷积核参数打破了传统的静态卷积的特性。作者将CondConv中的卷积核参数化为多个专家知识的线性组合(其中是通过梯度下降学习的加权系数):
为更有效的提升模型容量,在网络设计中可以提升专家数量,同时专家知识只需要进行一次组合,这就可以在提升模型容量的同时保持高效。
方法
在传统的卷积中,卷积核参数经训练确定且对所有输入样本一视同仁,而在动态卷积CondConv中卷积核参数通过对输入的变换得到,这个过程可以用公式表述为:
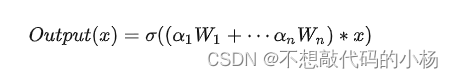
其中 是一个样本依赖加权参数。在动态卷积ConConv中,每个卷积核
具有与标准卷积核参数相同的维度。
常规卷积容量提升依赖于卷积核尺寸与通道数的提升,这将进一步提升网络的整体计算,而CondConv则只需要在执行卷积计算之前通过多个专家对输入样本计算加权卷积核。关键的是,每个卷积核只需计算一次并作用于不同位置即可。这意味着:通过提升专家数据量达到提升网络容量的目的,而代码仅仅是很小的推理耗时:每个额外参数仅需一次乘加。
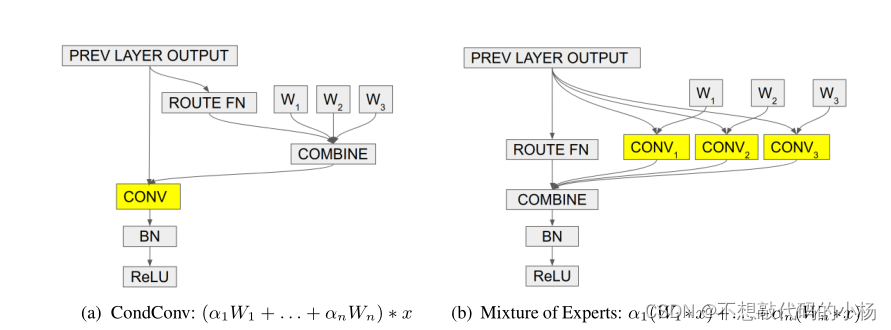
本文提出的方法如图(a)。图中的ROUTE FN指的是Routing Function可以理解为一个注意力机制相当于GAP+FC+Sigmod。在图(b)中,不同的W相当于不同的权重,不同的卷积核。每一条路径就是一个专家,然后通过Combine加权操作。但是这样计算量过大。但是作者证明了图(a)图(b)两种方法是等效的但是本文提出的图(a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









