







 本文详细介绍了BERT模型,包括其目标是理解句子含义并推断上下文,通过预训练和微调在大量无标签数据中获得通用理解力。文章还涵盖了BERT的前驱工作,如ELMo和GPT,以及BERT的模型架构,特别是预训练策略(包括MLM和NSP任务),以及BERTBASE和LARGE模型的参数配置。
本文详细介绍了BERT模型,包括其目标是理解句子含义并推断上下文,通过预训练和微调在大量无标签数据中获得通用理解力。文章还涵盖了BERT的前驱工作,如ELMo和GPT,以及BERT的模型架构,特别是预训练策略(包括MLM和NSP任务),以及BERTBASE和LARGE模型的参数配置。
BERT
BERT的目的是构建一个具有良好推广性的语言模型。它的主要目的并不是进行预测,而是理解句子的意思从而推断上下文关系。
在大量未进行标注的文本数据进行学习后获得一个强理解力的通用模型,这个过程称为预训练。在应用于下游任务时再次在具体任务的数据集上对预训练的参数进行更新,这个过程叫做微调,以期获得更加符合任务的模型。
1. BERT 之前的相关工作
ELMo双向RNN架构,使用双向特征提取,对每个任务构建神经网络。将训练好的特征和输入一起输入模型进行训练。
GPT已经在未标记的文本进行了预训练,又在训练下游任务时进行参数微调,但只使用从左到右的单向顺序。
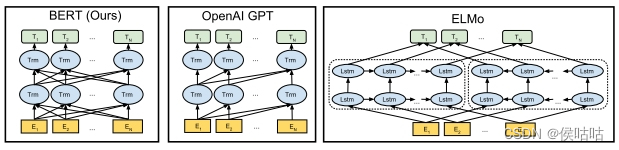
2. BERT 的模型架构
2.1 BERT 的预训练策略
BERT预训练的使用是长篇的文本,预训练会对句子进行切分。切分分为两种级别,一种是单词级的,一种是句子级的。
单词级切分使用的是WordPiece方法,有点像根据词根分割,如果有较长词汇出现,可能会被分成两个常见词或者是一个常见词和一个后缀,最后能够获得一个较小词典。
切词:flightless → flight ##less
playing → play ##ing ##表示该词语是前面词语的后缀
句子切分会在关键位置添加标记。句首 [CLS] ,句子分隔 [SEP],掩模 [MASK]。
BERT的输入由三个部分组成:单词编码,位置编码,句子编码。
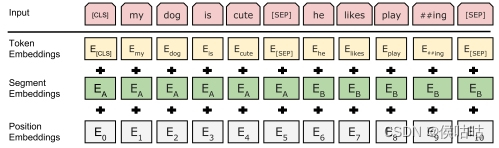
其中位置编码和句子编码都是整型标记
简易模拟编码过程:
# 正则表达
import re
# 数学函数
import math
import torch
# 数组处理
import numpy as np
from random import *
import torch.nn as nn
# 优化算法
import torch.optim as optim
import torch.utils.data as Data
text = (
'Hello, how are you? I am Romeo.\n' # R
'Hello, Romeo My name is Juliet. Nice to meet you.\n' # J
'Nice meet you too. How are you today?\n' # R
'Great. My baseball team won the competition.\n' # J
'Oh Congratulations, Juliet\n' # R
'Thank you Romeo\n' # J
'Where are you going today?\n' # R
'I am going shopping. What about you?\n' # J
'I am going to visit my grandmother. she is not very well' # R
)
# 将标点代替为空格 转小写 分割句子
sentences = re.sub("[.,!?\\-]", ' ', text.lower()).split('\n')
# 使用空格连接元素(每个句子) 分割(空格)为单词列表 列表转集合(去除重复元素,做字典词表) 集合转回列表
word_list = list(set(" ".join(sentences).split()))
# 创建标志字典(将添加单词映射)
word2idx = {
'[PAD]':0, '[CLS]':1, '[SEP]':2, '[MASK]':3} # 填充 开始 分隔 掩蔽
# 创建映射字典(从4开始)
for i, w in enumerate(word_list):
word2idx[w] = i + 4
# 映射回单词的字典
idx2word = {
i:w for i, w in enumerate(word2idx)}
# 字典长度
vocab_size = len(word2idx)
# 创建句子的单词编号|列表
token_list = list()
# 存储单词标号
for sentence in sentences:
arr = [word2idx[s] for s in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









